Lecture 14:Regularization
14.1 Regularized Hypothesis Set
上节课,我们提到了过拟合是机器学习中最危险的事情。本节我们讨论用 regularization 来抑制过拟合(一般课程将 regularization 翻译为正则化,但是在《技法》中还将 regularization 用于其它抑制过拟合的手段)
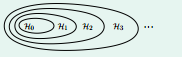
图 14.1
接这上节课的例子, 10-th 和 2-th 多项式都能很好的拟合测试数据。但是 10-th 多项式 hypothesis 是过拟合,我们就想着要从 H10 退回到低次 H。现在的问题是用什么标准去决定回退 step-back?为了回答这个问题,我们先看下图 14-1 的 Nested Hypothesis。
从图 14.1 中可以看出 Hn+1 包含了 Hn, 即 Hn 是 Hn+1 的子集。也就说是对于高次 Hn, 低于n 次的 H 都是它的子集。举个例子来说,就是 H2 = H10 with Constraint, w3=w4=...=w10 = 0
如果 regularization 是让 g 从 H10 step back 到 H2 ,那还不如直接用 H2 呢。我们现在修改 regularization 是让非 0 的 w 的个数不超过 3。 这样的好处是比 H2 灵活,比 H10 风险小。但是这个问题不容易解,我们可以换一下条件,如图 14-2 所示

图 14-2
这样的话,图 14-2 左边和右边的 H Overlaps but not same!同事 H(c) 还有个一个性质如图 14-3 所示(只有 H(c) 是图 14-2 中右图时才成立)

图 14-3
14.2 Weight Decay Regularization

图 14-4 目前要解决的问题
针对图 14-4 所示的问题,我们先看图 14-5。图 14-4 的问题就类似一组等高线去切红色圆圈。
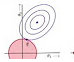
图 14-5

图 14-6
如图 14-6 所示,在 Ein 和 圆的相交处。如果 Ein 的梯度和圆法向量不是平行的,那么 Ein 的梯度必定有一个圆切线向量方向上的分量。那么 Ein还能往圆切线向量方向走。最终得到如下的结论
$$ abla E_{in}(w_{REG} varpropto w_{REG})$$
公式 14-1
即
$$ abla E_{in}(w_{REG}) = frac{2lambda}{N} w_{REG}$$
公式 14-2
如果我们知道 λ(λ 大于0) 的值,我们就能解得上式的解。这就是统计学上的 岭回归(关键我不是统计学专业的)
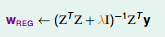
图 14-7
如果我们的解的不是线性回归,是 logistic 回归。我们就等于求解公式 14-3 的最小值。我们将公式 14-3 称做为增广误差, wTw 为正则项
$$ E_{in}(w) + frac{lambda}{N}w_{T}w$$
公式 14-3 增广误差
现在我们来看下 regularization 的效果,如果 图 14-8 所示。可以加一点点 λ 能有效抑制过拟合,加很大的 λ 有可能导致欠拟合
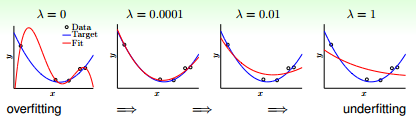
图 14-8 regularitzion effect
将 λ/N*wTw 称为 weight-decay regularization !
这里还有个小小的需要注意的地方, 假设输出的 x 在 [-1, +1] 范围内。高次方项的值很小,同时 regularization 会限制 whigh order 大小。这样在模型中的高次方项等于0,不起作用。这个时候需要换下坐标系,本节用的是勒让德多项式
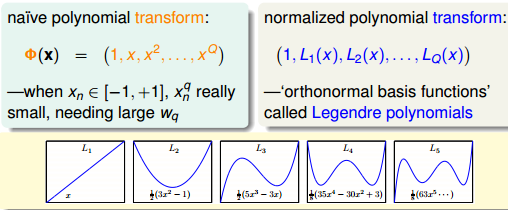
图 14-9 勒让德多项式
Q1: 如果 x 的取值范围属于 [-10000, 10000] 呢? 又该怎么办?当初在第 12 节课就应该想到这个问题
14.3 Regularization and VC Theory
我们来讨论一下 regularization 和 VC 维理论的关系
$$ E_{aug} = E_{in}(w) + frac{lambda}{N}w_{T}w$$
公式 14-4 增广误差
$$ E_{out}(w) leq E_{in}(w) + Omega(mathcal{H}(C))$$
公式 14-5 VC Bound
Eaug 要比 Ein 更接近 Eout, 所以minized Eaug 的效果更好。 另外 Eaug 中的正则化项也等于是剔除了一些 hypothesis,等于降低了 hypothesis 空间的 VC 维度,这样的话 Ein 和 Eout 的差值也就越小

图 14-10 Another View of Augmented Error
首先, Aumented Error 中的正则化项是针对单一 hypothesis, VC Bound 中的 Ω 是对于整个 hypothesis 空间的概念。如果单一 hypothesis 能很好 replace Ω,那么
14.4 General Regularizers
我们该如何设计更一般的 regularization 项? 林老师给出的自己的建议,如图 14-11 所示

图 14-11 设计 regularization 项建议
在第 2 小节中我们详细的介绍了 用 wTw 作正则化项,在机器学习中将 wTw 正则化项称之为 L2 正则化, ∑|wn| = C 正则化项位 L1 正则化。 这两个的具体的区别如图 14-12 所示
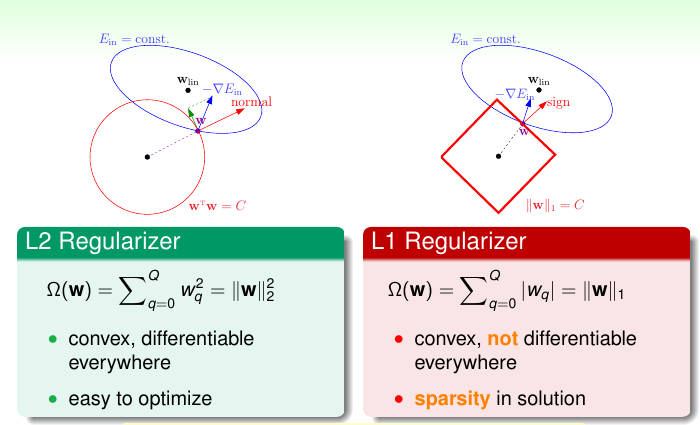
图 14-12
还是没有理解 为什么 L1 正则化项会导致稀疏解!!
我们现在来看下 噪声和正则化系数 λ 的关系,如图 14-13 所示
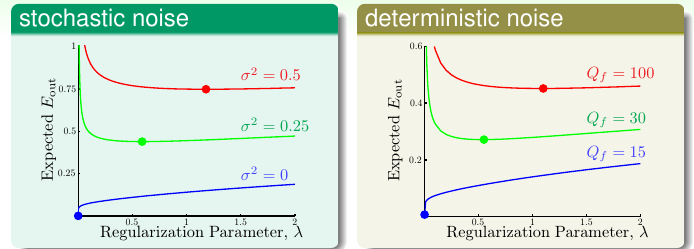
图 14-13
基本的结论是不论是 stochastic nosie or deterministic noise 都是 nosie 噪声强度越大越需要正则化(不知道为什么,没有 nosie 时候 λ 为 0 的效果是最好。而且对于某个 noise level 而言, 一开始随着 λ 的增大, out-sample error 会迅速下降最终达到一个最佳值。然后随着 λ 的增大, out-sample error 缓慢上升,此时应该是发生欠拟合)。而且林老师给出的解释无法让我相信,居然能那么完美地用开车的例子来类比(怎么看都像是机械的、形而上学的 、blabla 的),如图 14-14 所示

图 14-14
最后贴上本章的总结

图 14-15
题外话:
Q1: 不知道怎么回答,已更新第 12 节课笔记
T1: 第三小节,没怎么看懂。按照自己的理解瞎写一通~~
T2:根据第四节内容,更新第八节内容(关于 target-dependent、plausible、friendly的讨论)
关键词: 勒让德多项式 (在数学物理方法中应该学过)
T3: 贴上一张有趣的图,截自《技法》中第一节
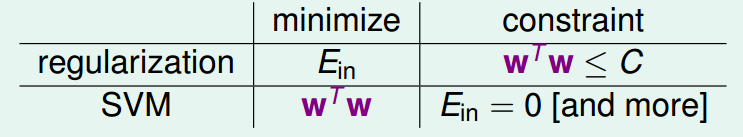
图 14-16