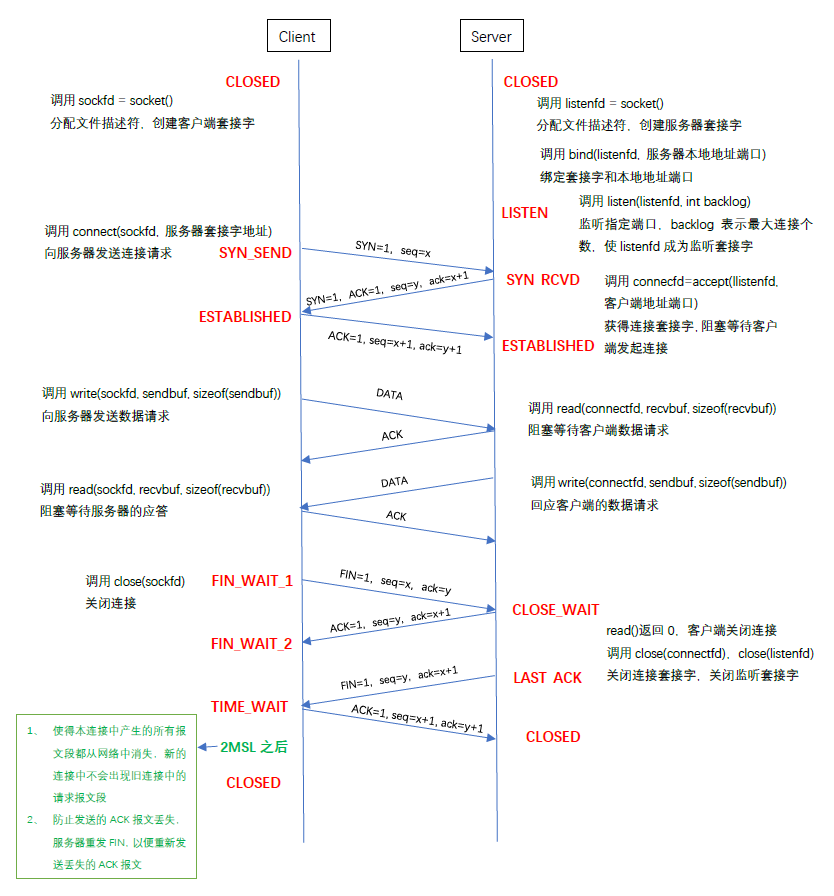
TCP在linux下的实现过程:
首先服务器端调用socket()创建服务器端的套接字之后调用bind()绑定创建socket是所拿到的socket文件描述符,之后调用acppet()阻塞自己等待客户端的连接。
客户端同样调用socket()创建客户端的套接字,之后调用connect()去连接服务器【根据服务器端的套接字锁定服务器】,此时TCP报文段中SYN=1,seq为一随机数字x,且客户端的连接状态置为SYS_SEND。
服务器端的accept()的阻塞收到该报文段之后被打断,置连接状态为SYN_RECV,并发送TCP报文段,SYN=1,ACK=1,seq为随机数字y,ack=x+1。
客户端收到该报文段后置状态为ESTABLISED,ACK=1,seq=x+1,ack=y+1。
服务器端接收到后置自己状态为ESTABLISED。此时三次握手已经结束。
之后便可调用read与write实现客户端与服务器端的通信。
那么具体的通信过程是怎么样的?
使用ipv4时,所有与TCP文件都在都在 net/ipv4/ -directory 目录下。摘选其中重要的TCP文件如下:

首先探究TCP/IP协议栈的初始化:
TCP/IP协议栈的初始化的函数入口是inet_init():
大致流程为:
首先地址族协议初始化语句for (i = 0; i < NPROTO; ++i) pops[i] = NULL;
接下来是proto_init()协议初始化;
协议初始化完成后再执行dev_init()设备的初始化。
static int __init inet_init(void) { struct inet_protosw *q; struct list_head *r; int rc = -EINVAL; BUILD_BUG_ON(sizeof(struct inet_skb_parm) > FIELD_SIZEOF(struct sk_buff, cb)); sysctl_local_reserved_ports = kzalloc(65536 / 8, GFP_KERNEL); if (!sysctl_local_reserved_ports) goto out; //tcp协议注册(传输层) rc = proto_register(&tcp_prot, 1); //第二个参数为1,表示在高速缓存内部分配空间 if (rc) goto out_free_reserved_ports; //udp协议注册(传输层) rc = proto_register(&udp_prot, 1); if (rc) goto out_unregister_tcp_proto; //raw原始协议注册(传输层) rc = proto_register(&raw_prot, 1); if (rc) goto out_unregister_udp_proto; //icmp协议注册(传输层) rc = proto_register(&ping_prot, 1); if (rc) goto out_unregister_raw_proto; /* * Tell SOCKET that we are alive... */ (void)sock_register(&inet_family_ops); #ifdef CONFIG_SYSCTL ip_static_sysctl_init(); #endif tcp_prot.sysctl_mem = init_net.ipv4.sysctl_tcp_mem; /* * Add all the base protocols. */ if (inet_add_protocol(&icmp_protocol, IPPROTO_ICMP) < 0) pr_crit("%s: Cannot add ICMP protocol ", __func__); if (inet_add_protocol(&udp_protocol, IPPROTO_UDP) < 0) pr_crit("%s: Cannot add UDP protocol ", __func__); if (inet_add_protocol(&tcp_protocol, IPPROTO_TCP) < 0) pr_crit("%s: Cannot add TCP protocol ", __func__); #ifdef CONFIG_IP_MULTICAST if (inet_add_protocol(&igmp_protocol, IPPROTO_IGMP) < 0) pr_crit("%s: Cannot add IGMP protocol ", __func__); #endif /* Register the socket-side information for inet_create. */ for (r = &inetsw[0]; r < &inetsw[SOCK_MAX]; ++r) INIT_LIST_HEAD(r); for (q = inetsw_array; q < &inetsw_array[INETSW_ARRAY_LEN]; ++q) inet_register_protosw(q); /* * Set the ARP module up */ arp_init(); /* * Set the IP module up */ ip_init(); tcp_v4_init(); /* Setup TCP slab cache for open requests. */ tcp_init(); /* Setup UDP memory threshold */ udp_init(); /* Add UDP-Lite (RFC 3828) */ udplite4_register(); ping_init(); /* * Set the ICMP layer up */ if (icmp_init() < 0) panic("Failed to create the ICMP control socket. "); /* * Initialise the multicast router */ #if defined(CONFIG_IP_MROUTE) if (ip_mr_init()) pr_crit("%s: Cannot init ipv4 mroute ", __func__); #endif /* * Initialise per-cpu ipv4 mibs */ if (init_ipv4_mibs()) pr_crit("%s: Cannot init ipv4 mibs ", __func__); ipv4_proc_init(); ipfrag_init(); dev_add_pack(&ip_packet_type); rc = 0; out: return rc; out_unregister_raw_proto: proto_unregister(&raw_prot); out_unregister_udp_proto: proto_unregister(&udp_prot); out_unregister_tcp_proto: proto_unregister(&tcp_prot); out_free_reserved_ports: kfree(sysctl_local_reserved_ports); goto out; } fs_initcall(inet_init);
其次,探究TCP报文段的数据段是怎么实现的。
在传输数据包时使用的数据结构:
文件位置:linux-5.0.1/include/linux/sk_buff.h
作用:Linux利用套接字缓冲区在协议层和网络设备之间传送数据。Sk_buff包含了一些指针和长度信息,从而可让协议层以标准的函数或方法对应用程序的数据进行处理。每个sk_buff均包含一个数据块、四个数据指针以及两个长度字段【见下注释】。
仅仅摘选与分析TCP传输有关的数据字段:
1 struct sk_buff { 2 /* These two members must be first. */ 3 struct sk_buff *next; // 因为sk_buff结构体是双链表,所以有前驱后继。这是个指向后面的sk_buff结构体指针 4 struct sk_buff *prev; // 这是指向前一个sk_buff结构体指针 6 struct sock *sk; // 指向拥有此缓冲的套接字sock结构体 7 ktime_t tstamp; // 时间戳,表示这个skb的接收到的时间 8 struct net_device *dev; // 表示一个网络设备,当skb为输出/输入时,dev表示要输出/输入到的设备 9 unsigned long _skb_dst; // 主要用于路由子系统,保存路由有关的东西 10 char cb[48]; // 保存每层的控制信息,每一层的私有信息 11 unsigned int len, // 表示数据区的长度(tail - data)与分片结构体数据区的长度之和。其实这个len中数据区长度是个有效长度, 12 // 因为不删除协议头,所以只计算有效协议头和包内容。如:当在L3时,不会计算L2的协议头长度。 13 data_len; // 只表示分片结构体数据区的长度,所以len = (tail - data) + data_len; 14 __u16 mac_len, // mac报头的长度 15 __u8 pkt_type:3, // 标记帧的类型 16 __be16 protocol:16; // 这是包的协议类型,标识是IP包还是ARP包或者其他数据包21 __u16 tc_index; /* traffic control index */ 22 #ifdef CONFIG_NET_CLS_ACT 23 __u16 tc_verd; /* traffic control verdict */ 24 25 sk_buff_data_t transport_header; // 指向四层帧头结构体指针 26 sk_buff_data_t network_header; // 指向三层IP头结构体指针 27 sk_buff_data_t mac_header; // 指向二层mac头的头 28 /* These elements must be at the end, see alloc_skb() for details. */ 29 sk_buff_data_t tail; // 指向数据区中实际数据结束的位置 30 sk_buff_data_t end; // 指向数据区中结束的位置(非实际数据区域结束位置) 31 unsigned char *head, // 指向数据区中开始的位置(非实际数据区域开始位置) 32 *data; // 指向数据区中实际数据开始的位置 33 unsigned int truesize; // 表示总长度,包括sk_buff自身长度和数据区以及分片结构体的数据区长度 34 };
sk_buff通过一个双链表实现,且在该DS中维护了mac层IP层以及传输层的指针,则其在各个层之间的传输过程的实现变很清楚了,当刚接受到该数据时在第二层此时data指针也就是指向实际数据开始的位置与mac header 指针相同,之后在向上层进行包装是通过修改data指针是的它指向network_header(IP层头指针),在往传输层进行传输的时候就修改data指向transport_header即可。这样做就可以避免数据的复制移动,处理更为高效。
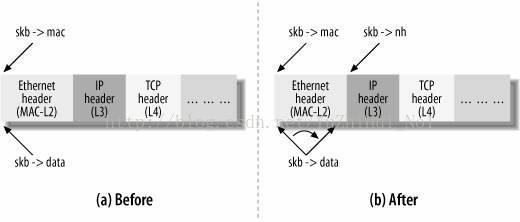
数据包在各层之间传递在linux中的实现
然后通过探究传输层与IP层如何交互以及三次握手的究竟的具体实现
TCP层的数据收发分析:
接收数据:
在ipv4的情况下,TCP接受从网络层传输的来的数据是通过tcp_v4_rcv。该方法首先检查包是否是给本机的,然后去从hash表中【该表的键值为IP+端口号】找匹配的TCP端口号。然后如果并没有该socket,就把他的数据传送给tcp_v4_do_rcv,检查socket的状态,如果状态为TCP_ESTABLISHED,数据就被传送到tcp_rcv_established(),并且将数据copy到就收队列中。其他的状态则交给tcp_rcv_state_process【也就是我们所需要关注的三次握手的过程在三次握手的】处理。
当用户想从socket读数据时(tcp_recvmsg),所有的队列必须按顺序处理【因为TCP保证可靠传输】,首先是recevie queue,然后是prequeue队列中的数据。
int tcp_v4_rcv(struct sk_buff *skb) {
...【仅仅摘取相关部分的代码】
/* 获取开始序号*/ TCP_SKB_CB(skb)->seq = ntohl(th->seq); /* 获取结束序号,syn与fin各占1 */ TCP_SKB_CB(skb)->end_seq = (TCP_SKB_CB(skb)->seq + th->syn + th->fin + skb->len - th->doff * 4); /* 获取确认序号 */ TCP_SKB_CB(skb)->ack_seq = ntohl(th->ack_seq); /* 获取标记字节,tcp首部第14个字节 */ TCP_SKB_CB(skb)->tcp_flags = tcp_flag_byte(th); TCP_SKB_CB(skb)->tcp_tw_isn = 0; /* 获取ip头的服务字段 */ TCP_SKB_CB(skb)->ip_dsfield = ipv4_get_dsfield(iph); TCP_SKB_CB(skb)->sacked = 0;
【根据不同状态进行不同处理】
process: /* TIME_WAIT转过去处理 */ if (sk->sk_state == TCP_TIME_WAIT) goto do_time_wait; /* TCP_NEW_SYN_RECV状态处理 */ if (sk->sk_state == TCP_NEW_SYN_RECV) { struct request_sock *req = inet_reqsk(sk); struct sock *nsk; /* 获取控制块 */ sk = req->rsk_listener; if (unlikely(tcp_v4_inbound_md5_hash(sk, skb))) { sk_drops_add(sk, skb); reqsk_put(req); goto discard_it; } /* 不是listen状态 */ if (unlikely(sk->sk_state != TCP_LISTEN)) { /* 从连接队列移除控制块 */ inet_csk_reqsk_queue_drop_and_put(sk, req); /* 根据skb参数重新查找控制块 */ goto lookup; } /* We own a reference on the listener, increase it again * as we might lose it too soon. */ sock_hold(sk); refcounted = true; /* 处理第三次握手ack,成功返回新控制块 */ nsk = tcp_check_req(sk, skb, req, false); /* 失败 */ if (!nsk) { reqsk_put(req); goto discard_and_relse; } /* 未新建控制块,进一步处理 */ if (nsk == sk) { reqsk_put(req); } /* 有新建控制块,进行初始化等 */ else if (tcp_child_process(sk, nsk, skb)) { /* 失败发送rst */ tcp_v4_send_reset(nsk, skb); goto discard_and_relse; } else { sock_put(sk); return 0; } } /* TIME_WAIT和TCP_NEW_SYN_RECV以外的状态 */ /* ttl错误 */ if (unlikely(iph->ttl < inet_sk(sk)->min_ttl)) { __NET_INC_STATS(net, LINUX_MIB_TCPMINTTLDROP); goto discard_and_relse; } if (!xfrm4_policy_check(sk, XFRM_POLICY_IN, skb)) goto discard_and_relse; if (tcp_v4_inbound_md5_hash(sk, skb)) goto discard_and_relse; /* 初始化nf成员 */ nf_reset(skb); /* tcp过滤 */ if (tcp_filter(sk, skb)) goto discard_and_relse; /* 取tcp和ip头 */ th = (const struct tcphdr *)skb->data; iph = ip_hdr(skb); /* 清空设备 */ skb->dev = NULL; /* LISTEN状态处理 */ if (sk->sk_state == TCP_LISTEN) { ret = tcp_v4_do_rcv(sk, skb); goto put_and_return; } /* TIME_WAIT和TCP_NEW_SYN_RECV和LISTEN以外的状态 */ /* 记录cpu */ sk_incoming_cpu_update(sk); bh_lock_sock_nested(sk); /* 分段统计 */ tcp_segs_in(tcp_sk(sk), skb); ret = 0; /* 未被用户锁定 */ if (!sock_owned_by_user(sk)) { /* 未能加入到prequeue */ if (!tcp_prequeue(sk, skb)) /* 进入tcpv4处理 */ ret = tcp_v4_do_rcv(sk, skb); } /* 已经被用户锁定,加入到backlog */ else if (tcp_add_backlog(sk, skb)) { goto discard_and_relse; } bh_unlock_sock(sk); put_and_return: /* 减少引用计数 */ if (refcounted) sock_put(sk); return ret; no_tcp_socket: if (!xfrm4_policy_check(NULL, XFRM_POLICY_IN, skb)) goto discard_it; if (tcp_checksum_complete(skb)) { csum_error: __TCP_INC_STATS(net, TCP_MIB_CSUMERRORS); bad_packet: __TCP_INC_STATS(net, TCP_MIB_INERRS); } else { /* 发送rst */ tcp_v4_send_reset(NULL, skb); } discard_it: /* Discard frame. */ kfree_skb(skb); return 0; discard_and_relse: sk_drops_add(sk, skb); if (refcounted) sock_put(sk); goto discard_it; do_time_wait: if (!xfrm4_policy_check(NULL, XFRM_POLICY_IN, skb)) { inet_twsk_put(inet_twsk(sk)); goto discard_it; } /* 校验和错误 */ if (tcp_checksum_complete(skb)) { inet_twsk_put(inet_twsk(sk)); goto csum_error; } /* TIME_WAIT入包处理 */ switch (tcp_timewait_state_process(inet_twsk(sk), skb, th)) { /* 收到syn */ case TCP_TW_SYN: { /* 查找监听控制块 */ struct sock *sk2 = inet_lookup_listener(dev_net(skb->dev), &tcp_hashinfo, skb, __tcp_hdrlen(th), iph->saddr, th->source, iph->daddr, th->dest, inet_iif(skb)); /* 找到 */ if (sk2) { /* 删除tw控制块 */ inet_twsk_deschedule_put(inet_twsk(sk)); /* 记录监听控制块 */ sk = sk2; refcounted = false; /* 进行新请求的处理 */ goto process; } /* Fall through to ACK */ } /* 发送ack */ case TCP_TW_ACK: tcp_v4_timewait_ack(sk, skb); break; /* 发送rst */ case TCP_TW_RST: tcp_v4_send_reset(sk, skb); /* 删除tw控制块 */ inet_twsk_deschedule_put(inet_twsk(sk)); goto discard_it; /* 成功*/ case TCP_TW_SUCCESS:; } goto discard_it; }
来自网路层的数据的处理流程图【TCP层的内部函数】:

发送数据
当应用程序想TCP的socket中写数据的时候首先被调用的方法就是tcp_sendmsg(),它对数据进行分段并且用上边介绍过得sk_buff封装数据,之后把buffer放至写队列中
1 参数含义:msg:要发送的数据; 2 size:本次要发送的数据量 3 int tcp_sendmsg(struct kiocb *iocb, struct socket *sock, struct msghdr *msg, 4 size_t size) 5 { 6 struct sock *sk = sock->sk; 7 struct iovec *iov; 8 struct tcp_sock *tp = tcp_sk(sk); 9 struct sk_buff *skb; 10 int iovlen, flags; 11 int mss_now, size_goal; 12 int err, copied; 13 long timeo; 14 15 lock_sock(sk); 16 TCP_CHECK_TIMER(sk); 17 18 //计算超时时间,如果设置了MSG_DONTWAIT标记,则超时时间为0 19 flags = msg->msg_flags; 20 timeo = sock_sndtimeo(sk, flags & MSG_DONTWAIT); 21 22 //只有ESTABLISHED和CLOSE_WAIT两个状态可以发送数据,其它状态需要等待连接完成; 23 //CLOSE_WAIT是收到对端FIN但是本端还没有发送FIN时所处状态,所以也可以发送数据 24 if ((1 << sk->sk_state) & ~(TCPF_ESTABLISHED | TCPF_CLOSE_WAIT)) 25 if ((err = sk_stream_wait_connect(sk, &timeo)) != 0) 26 goto out_err; 27 28 /* This should be in poll */ 29 clear_bit(SOCK_ASYNC_NOSPACE, &sk->sk_socket->flags); 30 31 //每次发送都操作都会重新获取MSS值,保存到mss_now中 32 mss_now = tcp_current_mss(sk, !(flags&MSG_OOB)); 33 //获取一个skb可以容纳的数据量。如果不支持TSO,那么该值就是MSS,否则是MSS的整数倍 34 size_goal = tp->xmit_size_goal; 35 36 //应用要发送的数据被保存在msg中,以数组方式组织,msg_iovlen为数组大小,msg_iov为数组第一个元素 37 iovlen = msg->msg_iovlen; 38 iov = msg->msg_iov; 39 //copied将记录本次能够写入TCP的字节数,如果成功,最终会返回给应用,初始化为0 40 copied = 0; 41 42 //检查之前TCP连接是否发生过异常 43 err = -EPIPE; 44 if (sk->sk_err || (sk->sk_shutdown & SEND_SHUTDOWN)) 45 goto do_error; 46 47 //外层循环用来遍历msg_iov数组 48 while (--iovlen >= 0) { 49 //msg_iov数组中每个元素包含的数据量都可以不同,每个元素自己有多少数据量记录在自己的iov_len字段中 50 int seglen = iov->iov_len; 51 //from指向要拷贝的数据起点 52 unsigned char __user *from = iov->iov_base; 53 54 //iov指向下一个数组元素 55 iov++; 56 //内层循环用于拷贝一个数组元素 57 while (seglen > 0) { 58 //copy保存本轮循环要拷贝的数据量,下面会根据不同的情况计算该值 59 int copy; 60 //获取发送队列中最后一个数据块,因为该数据块当前已保存数据可能还没有超过 61 //size_goal,所以可以继续往该数据块中填充数据 62 skb = tcp_write_queue_tail(sk); 63 64 //cond1:tcp_send_head()返回NULL表示待发送的新数为空(可能有待确认数据) 65 //cond2:copy <= 0说明发送队列最后一个skb数据量也达到了size_goal,不能 66 // 继续填充数据了。当两次发送之间MSS发生变化会出现小于0的情况 67 68 //这两种情况中的任意一种发生都只能选择分配新的skb 69 if (!tcp_send_head(sk) || 70 (copy = size_goal - skb->len) <= 0) { 71 new_segment: 72 /* Allocate new segment. If the interface is SG, 73 * allocate skb fitting to single page. 74 */ 75 //即将分配内存,首先检查内存使用是否会超限,如果会要先等待有内存可用 76 if (!sk_stream_memory_free(sk)) 77 goto wait_for_sndbuf; 78 //分配skb,select_size()的返回值决定了skb的线性区域大小,见下文 79 skb = sk_stream_alloc_skb(sk, select_size(sk), sk->sk_allocation); 80 //分配失败,需要等待有剩余内存可用后才能继续发送 81 if (!skb) 82 goto wait_for_memory; 83 84 /* 85 * Check whether we can use HW checksum. 86 */ 87 //根据硬件能力确定TCP是否需要执行校验工作 88 if (sk->sk_route_caps & NETIF_F_ALL_CSUM) 89 skb->ip_summed = CHECKSUM_PARTIAL; 90 91 //将新分配的skb加入到TCB的发送队列中,并且更新相关内存记账信息 92 skb_entail(sk, skb); 93 //设置本轮要拷贝的数据量为size_goal,因为该skb是新分配的,所以 94 //一定可以容纳这么多,但是具体能不能拷贝这么多,还需要看有没有这么 95 //多的数据要发送,见下方 96 copy = size_goal; 97 } 98 //如果skb可以容纳的数据量超过了当前数组元素中已有数据量,那么本轮只拷贝数组元素中已有的数据量 99 if (copy > seglen) 100 copy = seglen; 101 102 /* Where to copy to? */ 103 if (skb_tailroom(skb) > 0) { 104 //如果skb的线性部分还有空间,先填充这部分 105 106 //如果线性空间部分小于当前要拷贝的数据量,则调整本轮要拷贝的数据量 107 /* We have some space in skb head. Superb! */ 108 if (copy > skb_tailroom(skb)) 109 copy = skb_tailroom(skb); 110 //拷贝数据,如果出错则结束发送过程 111 if ((err = skb_add_data(skb, from, copy)) != 0) 112 goto do_fault; 113 } else { 114 //merge用于指示是否可以将新拷贝的数据和当前skb的最后一个片段合并。如果 115 //它们在页面内刚好是连续的,那么就可以合并为一个片段 116 int merge = 0; 117 //i为当前skb中已经存在的分片个数 118 int i = skb_shinfo(skb)->nr_frags; 119 //page指向上一次分配的页面,off指向该页面中的偏移量 120 struct page *page = TCP_PAGE(sk); 121 int off = TCP_OFF(sk); 122 //该函数用于判断该skb最后一个片段是否就是当前页面的最后一部分,如果是,那么新拷贝的 123 //数据和该片段就可以合并,所以设置merge为1,这样可以节省一个frag_list[]位置 124 if (skb_can_coalesce(skb, i, page, off) && off != PAGE_SIZE) { 125 /* We can extend the last page fragment. */ 126 merge = 1; 127 } else if (i == MAX_SKB_FRAGS || (!i && !(sk->sk_route_caps & NETIF_F_SG))) { 128 //如果skb中已经容纳的分片已经达到了限定值(条件1),或者网卡不支持SG IO 129 //那么就不能往skb中添加分片,设置PUSH标志位,然后跳转到new_segment处, 130 //然后重新分配一个skb,继续拷贝数据 131 /* Need to add new fragment and cannot 132 * do this because interface is non-SG, 133 * or because all the page slots are 134 * busy. */ 135 tcp_mark_push(tp, skb); 136 goto new_segment; 137 } else if (page) { 138 //如果上一次分配的页面已经使用完了,设定sk_sndpage为NULL 139 if (off == PAGE_SIZE) { 140 put_page(page); 141 TCP_PAGE(sk) = page = NULL; 142 off = 0; 143 } 144 } else 145 off = 0; 146 //如果要拷贝的数据量超过了当前页面剩余空间,调整本轮要拷贝的数据量 147 if (copy > PAGE_SIZE - off) 148 copy = PAGE_SIZE - off; 149 //检查拷贝copy字节数据后是否会导致发送内存超标,如果超标需要等待内存可用 150 if (!sk_wmem_schedule(sk, copy)) 151 goto wait_for_memory; 152 //如果没有可用页面,则分配一个新的,分配失败则会等待内存可用 153 if (!page) { 154 /* Allocate new cache page. */ 155 if (!(page = sk_stream_alloc_page(sk))) 156 goto wait_for_memory; 157 } 158 //拷贝copy字节数据到页面中 159 err = skb_copy_to_page(sk, from, skb, page, off, copy); 160 //拷贝失败处理 161 if (err) { 162 //虽然本次拷贝失败了,但是如果页面是新分配的,也不会收回了, 163 //而是将其继续指派给当前TCB,这样下次发送就可以直接使用了 164 if (!TCP_PAGE(sk)) { 165 TCP_PAGE(sk) = page; 166 TCP_OFF(sk) = 0; 167 } 168 goto do_error; 169 } 170 171 //更新skb中相关指针、计数信息 172 if (merge) { 173 //因为可以和最后一个分片合并,所以只需要更新该分片的大小即可 174 skb_shinfo(skb)->frags[i - 1].size += copy; 175 } else { 176 //占用一个新的frag_list[]元素 177 skb_fill_page_desc(skb, i, page, off, copy); 178 if (TCP_PAGE(sk)) { 179 //如果是旧页面,但是因为新分配了片段,所以累加对页面的引用计数 180 //从这里可以看出,skb中的每个片段都会持有一个对页面的引用计数 181 get_page(page); 182 } else if (off + copy < PAGE_SIZE) { 183 //页面是新分配的,并且本次拷贝没有将页面用完,所以持有页面的 184 //引用计数,然后将页面指定给sk_sndmsg_page字段,下次可以继续使用 185 get_page(page); 186 TCP_PAGE(sk) = page; 187 } 188 } 189 //设置sk_sndmsg_off的偏移量 190 TCP_OFF(sk) = off + copy; 191 }//end of 'else' 192 193 //如果本轮是第一次拷贝,清除PUSH标记 194 if (!copied) 195 TCP_SKB_CB(skb)->flags &= ~TCPCB_FLAG_PSH; 196 //write_seq记录的是发送队列中下一个要分配的序号,所以这里需要更新它 197 tp->write_seq += copy; 198 //更新该数据包的最后一个字节的序号 199 TCP_SKB_CB(skb)->end_seq += copy; 200 skb_shinfo(skb)->gso_segs = 0; 201 202 //用户空间缓存区指针前移 203 from += copy; 204 //累加已经拷贝字节数 205 copied += copy; 206 //如果所有要发送的数据都拷贝完了,结束发送过程 207 if ((seglen -= copy) == 0 && iovlen == 0) 208 goto out; 209 //如果该skb没有填满,继续下一轮拷贝 210 if (skb->len < size_goal || (flags & MSG_OOB)) 211 continue; 212 //如果需要设置PUSH标志位,那么设置PUSH,然后发送数据包,可将PUSH可以让TCP尽快的发送数据 213 if (forced_push(tp)) { 214 tcp_mark_push(tp, skb); 215 //尽可能的将发送队列中的skb发送出去,禁用nalge 216 __tcp_push_pending_frames(sk, mss_now, TCP_NAGLE_PUSH); 217 } else if (skb == tcp_send_head(sk)) 218 //当前只有这一个skb,也发送出去。因为只有一个,所以肯定也不存在拥塞,可以发送 219 tcp_push_one(sk, mss_now); 220 221 //继续拷贝数据 222 continue; 223 224 wait_for_sndbuf: 225 //设置套接字结构中发送缓存不足的标志 226 set_bit(SOCK_NOSPACE, &sk->sk_socket->flags); 227 wait_for_memory: 228 //如果已经有数据拷贝到了发送缓存中,那么调用tcp_push()立即发送,这样可能可以 229 //让发送缓存快速的有剩余空间可用 230 if (copied) 231 tcp_push(sk, flags & ~MSG_MORE, mss_now, TCP_NAGLE_PUSH); 232 //等待有空余内存可以使用,如果timeo不为0,那么这一步会休眠 233 if ((err = sk_stream_wait_memory(sk, &timeo)) != 0) 234 goto do_error; 235 //睡眠后MSS可能发生了变化,所以重新计算 236 mss_now = tcp_current_mss(sk, !(flags&MSG_OOB)); 237 size_goal = tp->xmit_size_goal; 238 }//end of 'while (seglen > 0)',内层循环 239 }//end of 'while (--iovlen >= 0)',外层循环
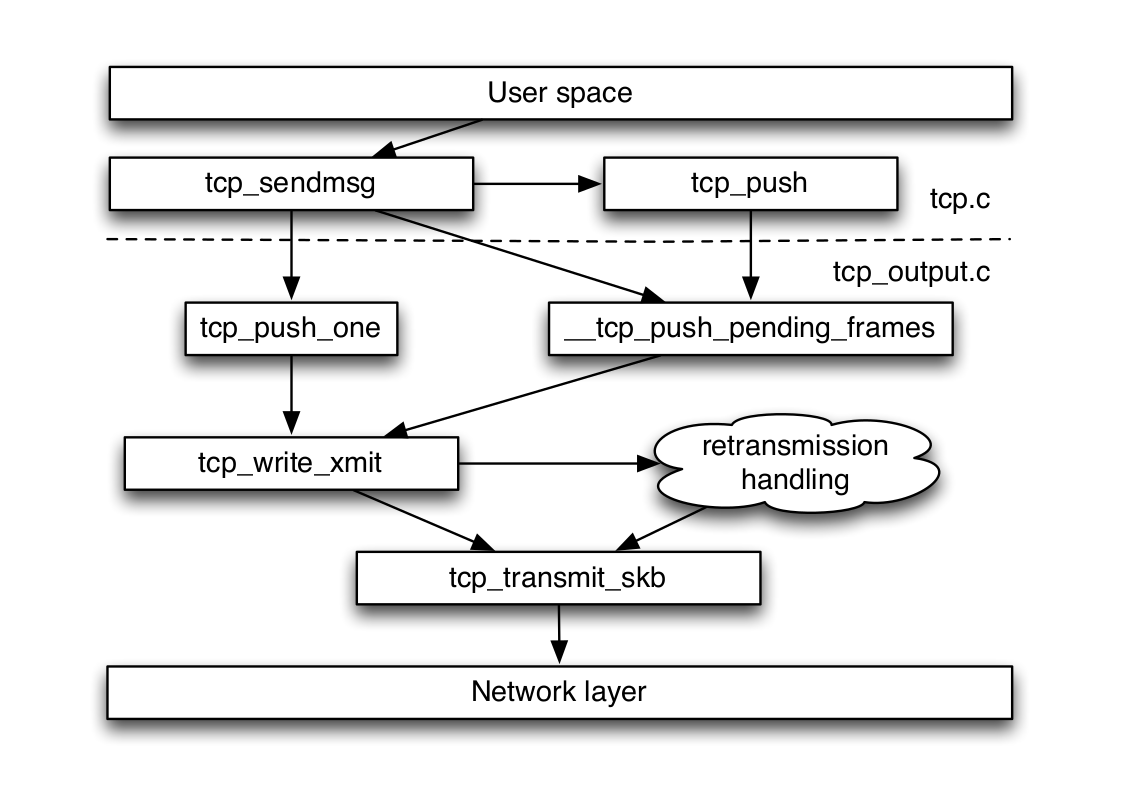
发送数据至ip层的处理
三次握手的具体实现过程:
首先是客户端需要发送SYN=1,seq=x的数据段的实现,此函数从sys_connect()入手。
整个发送的调用过程为:tcp_v4_connect()->tcp_connect()->tcp_transmit_skb(),在发送结束后置状态为TCP_SYN_SENT。
截取发送过中的的代码:
1: /* 构造并发送SYN段 */ 2: int tcp_connect(struct sock *sk) 3: { 4: struct tcp_sock *tp = tcp_sk(sk); 5: struct sk_buff *buff; 6: 7: tcp_connect_init(sk);/* 初始化传输控制块中与连接相关的成员 */ 8: 9: /* 为SYN段分配报文并进行初始化 */ 10: buff = alloc_skb(MAX_TCP_HEADER + 15, sk->sk_allocation); 11: if (unlikely(buff == NULL)) 12: return -ENOBUFS; 13: 14: /* Reserve space for headers. */ 15: skb_reserve(buff, MAX_TCP_HEADER); 16: 17: TCP_SKB_CB(buff)->flags = TCPCB_FLAG_SYN; 18: TCP_ECN_send_syn(sk, tp, buff); 19: TCP_SKB_CB(buff)->sacked = 0; 20: skb_shinfo(buff)->tso_segs = 1; 21: skb_shinfo(buff)->tso_size = 0; 22: buff->csum = 0; 23: TCP_SKB_CB(buff)->seq = tp->write_seq++; 24: TCP_SKB_CB(buff)->end_seq = tp->write_seq; 25: tp->snd_nxt = tp->write_seq; 26: tp->pushed_seq = tp->write_seq; 27: tcp_ca_init(tp); 28: 29: /* Send it off. */ 30: TCP_SKB_CB(buff)->when = tcp_time_stamp; 31: tp->retrans_stamp = TCP_SKB_CB(buff)->when; 32: 33: /* 将报文添加到发送队列上 */ 34: __skb_queue_tail(&sk->sk_write_queue, buff); 35: sk_charge_skb(sk, buff); 36: tp->packets_out += tcp_skb_pcount(buff); 37: /* 发送SYN段 */ 38: tcp_transmit_skb(sk, skb_clone(buff, GFP_KERNEL)); 39: TCP_INC_STATS(TCP_MIB_ACTIVEOPENS); 40: 41: /* Timer for repeating the SYN until an answer. */ 42: /* 启动重传定时器 */ 43: tcp_reset_xmit_timer(sk, TCP_TIME_RETRANS, tp->rto); 44: return 0; 45: }
之后服务器在收到SYN数据段时,处理入口就是上边讲述过的tcp_v4_do_rcv()。
整个接收数据处理并发送的调用过程为:tcp_v4_do_rcv()->tcp_rcv_state_process()->tcp_v4_conn_request()->tcp_v4_send_synack().
其中tcp_v4_send_synack() 完成构建SYN+ACK段 *,生成IP数据报并发送出去 。【源代码如下】
1: /* 向客户端发送SYN+ACK报文 */ 2: static int tcp_v4_send_synack(struct sock *sk, struct open_request *req, 3: struct dst_entry *dst) 4: { 5: int err = -1; 6: struct sk_buff * skb; 7: 8: /* First, grab a route. */ 9: /* 查找到客户端的路由 */ 10: if (!dst && (dst = tcp_v4_route_req(sk, req)) == NULL) 11: goto out; 12: 13: /* 根据路由、传输控制块、连接请求块中的构建SYN+ACK段 */ 14: skb = tcp_make_synack(sk, dst, req); 15: 16: if (skb) {/* 生成SYN+ACK段成功 */ 17: struct tcphdr *th = skb->h.th; 18: 19: /* 生成校验码 */ 20: th->check = tcp_v4_check(th, skb->len, 21: req->af.v4_req.loc_addr, 22: req->af.v4_req.rmt_addr, 23: csum_partial((char *)th, skb->len, 24: skb->csum)); 25: 26: /* 生成IP数据报并发送出去 */ 27: err = ip_build_and_send_pkt(skb, sk, req->af.v4_req.loc_addr, 28: req->af.v4_req.rmt_addr, 29: req->af.v4_req.opt); 30: if (err == NET_XMIT_CN) 31: err = 0; 32: } 33: 34: out: 35: dst_release(dst); 36: return err; 37: } 38:
客户端回复确认ACK段
处理的入口函数同样为上述的tcp_v4_do_rcv()
服务器端的接收并发送数据段的的调用过程:tcp_v4_do_rcv()->tcp_rcv_state_process().
在发送结束后,客户端处于TCP_SYN_SENT状态。
根据TCP_SYN_SENT状态,在tcp_v4_do_rcv()调用的处理为:tcp_rcv_synsent_state_process()
/* 在SYN_SENT状态下处理接收到的段,但是不处理带外数据 */ static int tcp_rcv_synsent_state_process(struct sock *sk, struct sk_buff *skb, struct tcphdr *th, unsigned len) { if (th->ack) {/* 处理ACK标志 */ /* rfc3 * "If the state is SYN-SENT then * first check the ACK bit * If the ACK bit is set * If SEG.ACK =< ISS, or SEG.ACK > SND.NXT, send * a reset (unless the RST bit is set, if so drop * the segment and return)" * * We do not send data with SYN, so that RFC-correct * test reduces to */ if (TCP_SKB_CB(skb)->ack_seq != tp->snd_nxt) goto reset_and_undo; if (tp->rx_opt.saw_tstamp && tp->rx_opt.rcv_tsecr && !between(tp->rx_opt.rcv_tsecr, tp->retrans_stamp, tcp_time_stamp)) { NET_INC_STATS_BH(LINUX_MIB_PAWSACTIVEREJECTED); goto reset_and_undo; } /* Now ACK is acceptable. * * "If the RST bit is set * If the ACK was acceptable then signal the user "error * connection reset", drop the segment, enter CLOSED state, * delete TCB, and return." */ if (th->rst) {/* 收到ACK+RST段,需要tcp_reset设置错误码,并关闭套接口 */ tcp_reset(sk); goto discard; } /* rfc * "fifth, if neither of the SYN or RST bits is set then * drop the segment and return." * * See note below! * --ANK() */ if (!th->syn)/* 在SYN_SENT状态下接收到的段必须存在SYN标志,否则说明接收到的段无效,丢弃该段 */ goto discard_and_undo; discard: __kfree_skb(skb); return ; } else {/*tcp_send_ack();在主动连接时,向服务器端发送ACK完成连接,并更新窗口
alloc_skb();构造ack段
tcp_transmit_skb(); * 将ack段发出 *
tcp_send_ack(sk); } return -1; } /* 在SYN_SENT状态下收到了SYN段并且没有ACK,说明是两端同时打开 */ if (th->syn) { /* We see SYN without ACK. It is attempt of * simultaneous connect with crossed SYNs. * Particularly, it can be connect to self. */ tcp_set_state(sk, TCP_SYN_RECV);/* 设置状态为TCP_SYN_RECV */
服务端收到ACK段
处理入口仍然为上述tcp_v4_do_rcv(),
处理的调用过程为tcp_v4_do_rcv()->tcp_rcv_state_process().
处理结束后当前服务端处于TCP_SYN_RECV状态变为TCP_ESTABLISHED状态。
1: /* 除了ESTABLISHED和TIME_WAIT状态外,其他状态下的TCP段处理都由本函数实现 */ 2: int tcp_rcv_state_process(struct sock *sk, struct sk_buff *skb, 3: struct tcphdr *th, unsigned len) 4: { 5: struct tcp_sock *tp = tcp_sk(sk); 6: int queued = 0; 7: 8: tp->rx_opt.saw_tstamp = 0; 9: 10: switch (sk->sk_state) { 11: ..... 12: /* SYN_RECV状态的处理 */ 13: if (tcp_fast_parse_options(skb, th, tp) && tp->rx_opt.saw_tstamp &&/* 解析TCP选项,如果首部中存在时间戳选项 */ 14: tcp_paws_discard(tp, skb)) {/* PAWS检测失败,则丢弃报文 */ 15: if (!th->rst) {/* 如果不是RST段 */ 16: /* 发送DACK给对端,说明接收到的TCP段已经处理过 */ 17: NET_INC_STATS_BH(LINUX_MIB_PAWSESTABREJECTED); 18: tcp_send_dupack(sk, skb); 19: goto discard; 20: } 21: /* Reset is accepted even if it did not pass PAWS. */ 22: } 23: 24: /* step 1: check sequence number */ 25: if (!tcp_sequence(tp, TCP_SKB_CB(skb)->seq, TCP_SKB_CB(skb)->end_seq)) {/* TCP段序号无效 */ 26: if (!th->rst)/* 如果TCP段无RST标志,则发送DACK给对方 */ 27: tcp_send_dupack(sk, skb); 28: goto discard; 29: } 30: 31: /* step 2: check RST bit */ 32: if(th->rst) {/* 如果有RST标志,则重置连接 */ 33: tcp_reset(sk); 34: goto discard; 35: } 36: 37: /* 如果有必要,则更新时间戳 */ 38: tcp_replace_ts_recent(tp, TCP_SKB_CB(skb)->seq); 39: 40: /* step 3: check security and precedence [ignored] */ 41: 42: /* step 4: 43: * 44: * Check for a SYN in window. 45: */ 46: if (th->syn && !before(TCP_SKB_CB(skb)->seq, tp->rcv_nxt)) {/* 如果有SYN标志并且序号在接收窗口内 */ 47: NET_INC_STATS_BH(LINUX_MIB_TCPABORTONSYN); 48: tcp_reset(sk);/* 复位连接 */ 49: return 1; 50: } 51: 52: /* step 5: check the ACK field */ 53: if (th->ack) {/* 如果有ACK标志 */ 54: /* 检查ACK是否为正常的第三次握手 */ 55: int acceptable = tcp_ack(sk, skb, FLAG_SLOWPATH); 56: 57: switch(sk->sk_state) { 58: case TCP_SYN_RECV: 59: if (acceptable) { 60: tp->copied_seq = tp->rcv_nxt; 61: mb(); 62: /* 正常的第三次握手,设置连接状态为TCP_ESTABLISHED */ 63: tcp_set_state(sk, TCP_ESTABLISHED); 64: sk->sk_state_change(sk); 65: 66: /* Note, that this wakeup is only for marginal 67: * crossed SYN case. Passively open sockets 68: * are not waked up, because sk->sk_sleep == 69: * NULL and sk->sk_socket == NULL. 70: */ 71: if (sk->sk_socket) {/* 状态已经正常,唤醒那些等待的线程 */ 72: sk_wake_async(sk,0,POLL_OUT); 73: } 74: 75: /* 初始化传输控制块,如果存在时间戳选项,同时平滑RTT为0,则需计算重传超时时间 */ 76: tp->snd_una = TCP_SKB_CB(skb)->ack_seq; 77: tp->snd_wnd = ntohs(th->window) << 78: tp->rx_opt.snd_wscale; 79: tcp_init_wl(tp, TCP_SKB_CB(skb)->ack_seq, 80: TCP_SKB_CB(skb)->seq); 81: 82: /* tcp_ack considers this ACK as duplicate 83: * and does not calculate rtt. 84: * Fix it at least with timestamps. 85: */ 86: if (tp->rx_opt.saw_tstamp && tp->rx_opt.rcv_tsecr && 87: !tp->srtt) 88: tcp_ack_saw_tstamp(tp, 0); 89: 90: if (tp->rx_opt.tstamp_ok) 91: tp->advmss -= TCPOLEN_TSTAMP_ALIGNED; 92: 93: /* Make sure socket is routed, for 94: * correct metrics. 95: */ 96: /* 建立路由,初始化拥塞控制模块 */ 97: tp->af_specific->rebuild_header(sk); 98: 99: tcp_init_metrics(sk); 100: 101: /* Prevent spurious tcp_cwnd_restart() on 102: * first data packet. 103: */ 104: tp->lsndtime = tcp_time_stamp;/* 更新最近一次发送数据包的时间 */ 105: 106: tcp_initialize_rcv_mss(sk); 107: tcp_init_buffer_space(sk); 108: tcp_fast_path_on(tp);/* 计算有关TCP首部预测的标志 */ 109: } else { 110: return 1; 111: } 112: break; 113: ..... 114: } 115: } else 116: goto discard; 117: ..... 118: 119: /* step 6: check the URG bit */ 120: tcp_urg(sk, skb, th);/* 检测带外数据位 */ 121: 122: /* tcp_data could move socket to TIME-WAIT */ 123: if (sk->sk_state != TCP_CLOSE) {/* 如果tcp_data需要发送数据和ACK则在这里处理 */ 124: tcp_data_snd_check(sk); 125: tcp_ack_snd_check(sk); 126: } 127: 128: if (!queued) { /* 如果段没有加入队列,或者前面的流程需要释放报文,则释放它 */ 129: discard: 130: __kfree_skb(skb); 131: } 132: return 0;
至此三次握手就处理完毕了。
三次握手核心函数的断点如图所示:
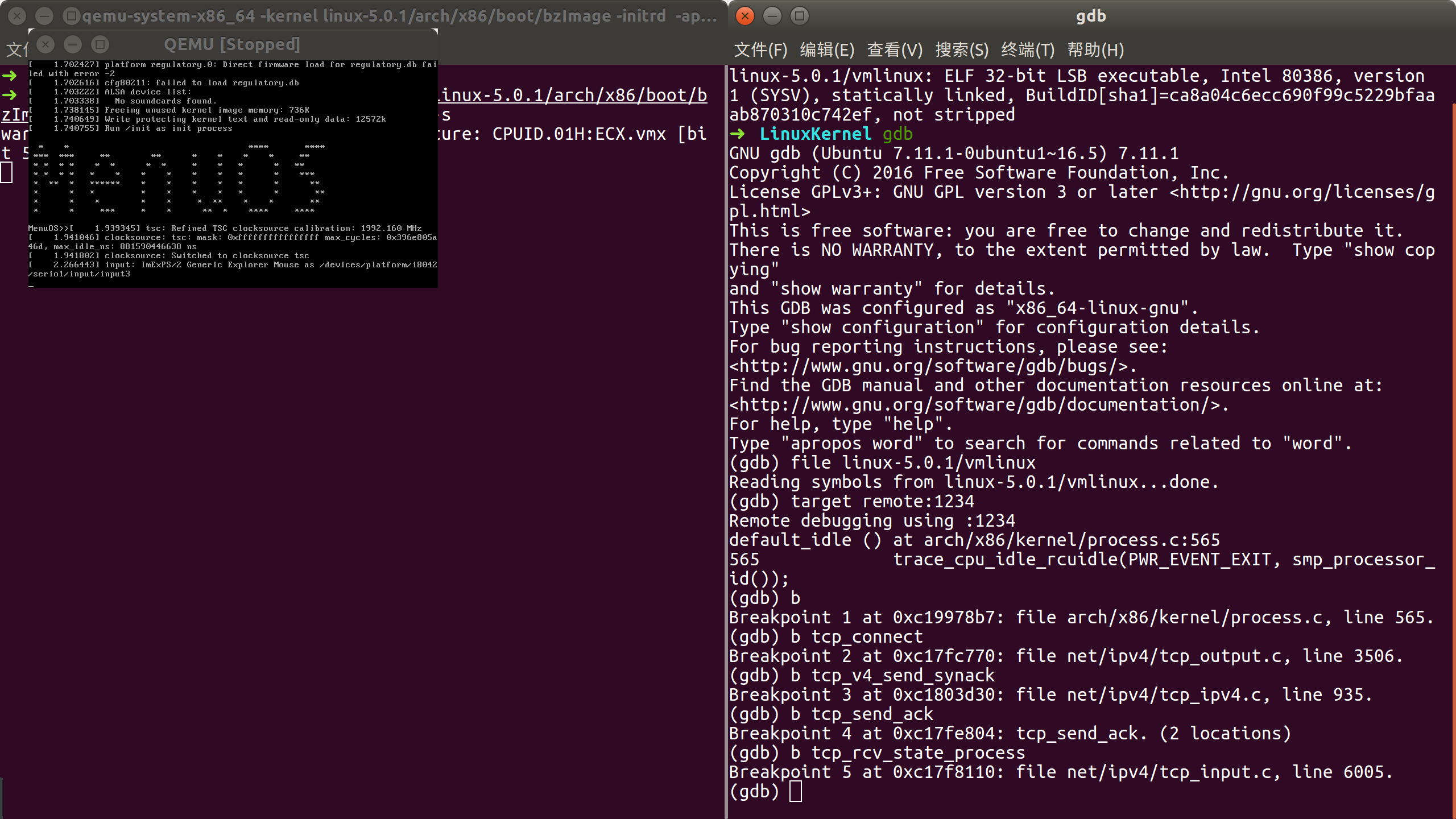
可使用wireshark通过抓取localhost的包来验证三次握手的环节【由于不是很熟悉操作,没有做】
至此就分析完毕了。