Scrapy Reference : https://doc.scrapy.org/en/master/index.html
2.1. Scrapy installation
Scrapy Installation Reference: https://doc.scrapy.org/en/latest/intro/install.html
To install scrapy on Ubuntu (or Ubuntu-based) systems, you need to install these dependencies:
1 sudo apt-get install python-dev python-pip libxml2-dev libxslt1-dev zlib1g-dev libffi-dev libssl-dev
python-dev,zlib1g-dev,libxml2-devandlibxslt1-devare required forlxmllibssl-devandlibffi-devare required forcryptography
If you want to install scrapy on Python 3, you’ll also need Python 3 development headers:
1 sudo apt-get install python3 python3-dev
you can install Scrapy with pip after that:
1 pip3 install scrapy
2.2 Scrapy 安装验证及命令介绍
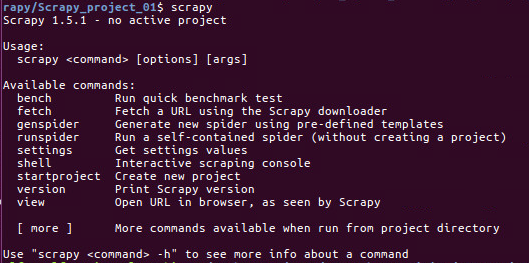
3. Scrapy 入门案例
3.1 创建项目(scrapy startproject)
- 在开始爬虫之前,必须创建一个新的scrapy项目,进入定义的项目目录中,运行命令:
1 scrapy startproject mySpider
- 其中,mySpider为项目名称,可以看到将会创建一个mySpider文件夹,目录结构如下:
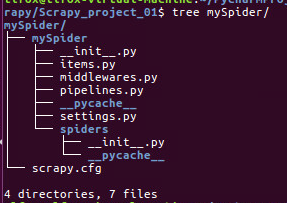
下面为个文件的作用:
1 scrapy.cfg:项目的配置文件。 2 mySpider :项目的Python模块,将会从这里引用代码。 3 mySpider/items.py:项目的目标文件 4 mySpider/pipelines.py:项目管道文件 5 mySpider/settings.py:项目的设置文件 6 mySpider/spiders/:存储爬虫代码目录
3.2 明确目标(mySpider/items.py)
我们打算抓取:http://www.itcast.cn/channel/teacher.shtml 网站的所有讲师的姓名、职称和个人信息。
- 打开mySpider目录下的items.py。
- item定义结构数据字段,用来保存爬去到的数据,有点像Python中的dict,但是提供了一些额外的保护减少错误
- 可以通过创建一个scrapy.item类,并且定义类型为scrapy Field的类属性来定义一个item(可以理解成类似于ORM的映射关系)。
- 接下来,创建一个ItcastItem类,和构建item模型(model)。
1 import scrapy 2 3 class MyspiderItem(scrapy.Item): 4 # define the fields for your item here like: 5 # name = scrapy.Field() 6 pass 7 8 class ItcastItem(scrapy.Item): #定义了三个字段 9 name = scrapy.Field() 10 level = scrapy.Field() 11 info = scrapy.Field()
3.3 制作爬虫(spider/itcastSpider.py)
爬虫功能要分两步:
1. 爬数据
在当前目录下输入命令,将mySpider/spider目录下创建一个名为itcast的爬虫,并指定爬取区域的范围:
1 scrapy genspider itcast “itcast.cn" #创建了一个名为itcast的爬虫(项目中唯一)。爬取的区域为itcast.cn。这些会写入mySpider/spider目录里的itcast.py文件中。
注:后续生成的文件为:itcast.py
执行完此代码,spders文件夹中多了一个itcast.py文件(__pycache__中也会增加一些文件):
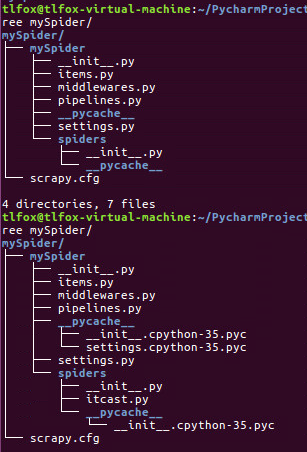
打开mySpider/spider目录里的itcast.py,默认增加了下列代码:
1 # -*- coding: utf-8 -*- 2 import scrapy 3 4 class ItcastSpider(scrapy.Spider): 5 name = 'itcast' 6 allowed_domains = ['itcast.cn'] 7 start_urls = ['http://itcast.cn/',] 8 9 def parse(self, response): 10 pass
其实也可以由我们自行创建itcast.py并编写上面的代码,只不过使用命令可以免去编写固定代码的麻烦。
要建立一个Spider,你必须用scrapy。Spider类创建一个子类,并确定了三个强制的属性和一个方法。
- name = " " :这个爬虫的识别名称,必须是唯一的,在不同的爬虫必须定义不同的名字。
- allow_domains = [] :是搜索的域名范围,也就是爬虫的约束区域,规定爬虫只爬取这个域名下的网页,不存在的URL会被忽视。
- start_urls= () :爬取的URL元祖/列表,爬虫从这里抓取数据,所以,第一次下载的数据将会从这些URLs开始,其他URL将会从这些起来URL中继承性生成。
- parse(self,response) :解析的方法,每个初始URL完成下载后将被调用,调用的时候传入从每一个URL传回的Response对象来作为唯一参数,主要作用如下:
- 负责解析返回的网页数据(response.body),提取结构化数据(生成item)。
- 生成需要下一页的URL请求。
Spider类是写的就是我们的爬虫代码,其中有些重要的属性和方法:


1 name:定义spider名字的字符串。 2 例如,如果spider爬取 mywebsite.com ,该spider通常会被命名为 mywebsite 3 4 allowed_domains:包含了spider允许爬取的域名(domain)的列表,可选。 5 6 start_urls:初始URL元祖/列表。当没有制定特定的URL时,spider将从该列表中开始进行爬取。 7 8 start_requests(self):该方法必须返回一个可迭代对象(iterable)。该对象包含了spider用于爬取(默认实现是使用 start_urls 的url)的第一个Request。 9 当spider启动爬取并且未指定start_urls时,该方法被调用。 10 11 parse(self, response):当请求url返回网页没有指定回调函数时,默认的Request对象回调函数。用来处理网页返回的response,以及生成Item或者Request对象。 12 13 log(self, message[, level, component]):使用 scrapy.log.msg() 方法记录(log)message。 更多数据请参见 logging
将start_urls的值修改为需要爬取的第一个url:
1 start_urls = ['http://www.itcast.cn/channel/teacher.shtml',]
修改parse()方法:
1 def parse(self, response): 2 with open("teacer.html","wb") as f: 3 f.write(response.txt)
然后运行一下看看,再mySpider目录下执行:
1 scrapy crawl itcast
注意:项目名是itcast,且唯一。它是itcastSpider类的name属性,也就是使用scrapy genspider命令的爬虫名。
一个scrapy爬虫项目里,可以存在多个爬虫,各个爬虫在执行时,就是按照name属性来区分。
运行之后,如果打印日志出现[scrapy.core.engine] INFO: Spider closed (finished),代表执行完成。之后当前文件夹中就出现一个teacher.html文件,里面就是刚刚要爬取网页的全部源代码。
#注意:Python2.x默认编码环境是ASCII,当取回数据编码格式不一样时,可能会造成乱码; #我们可以指定保存内容的编码格式,一般情况下,我们可以在代码最上方添加: import sys reload(sys) sys.setdefaultencoding("utf-8") #这三行代码是Python2.x里解决中文编码的万能钥匙,Python3,默认是unicode了。
2. 取数据
- 爬取整个网页完毕,接下来的就是取数据的过程,首先观察页面源代码:
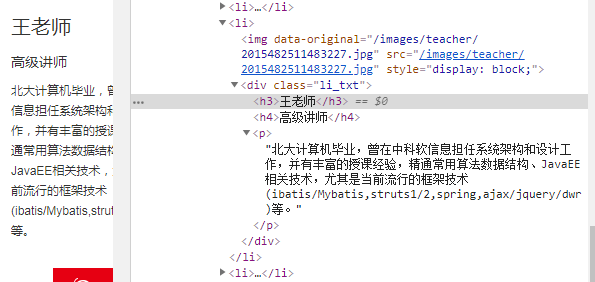
用XPath开始提取数据:(用scrapy shell来提数据更直观)
1 scrapy shell 'http://www.itcast.cn/channel/teacher.shtml' 2 2018-07-23 16:07:42 [scrapy.utils.log] INFO: Scrapy 1.5.1 started (bot: mySpider) 3 2018-07-23 16:07:42 [scrapy.utils.log] INFO: Versions: lxml 4.2.3.0, libxml2 2.9.8, cssselect 1.0.3, parsel 1.5.0, w3lib 1.19.0, Twisted 18.7.0, Python 3.5.2 (default, Nov 23 2017, 16:37:01) - [GCC 5.4.0 20160609], pyOpenSSL 18.0.0 (OpenSSL 1.0.2g 1 Mar 2016), cryptography 2.3, Platform Linux-4.4.0-130-generic-x86_64-with-Ubuntu-16.04-xenial 4 2018-07-23 16:07:42 [scrapy.crawler] INFO: Overridden settings: {'DUPEFILTER_CLASS': 'scrapy.dupefilters.BaseDupeFilter', 'NEWSPIDER_MODULE': 'mySpider.spiders', 'LOGSTATS_INTERVAL': 0, 'ROBOTSTXT_OBEY': True, 'BOT_NAME': 'mySpider', 'SPIDER_MODULES': ['mySpider.spiders']} 5 2018-07-23 16:07:43 [scrapy.middleware] INFO: Enabled extensions: 6 ['scrapy.extensions.memusage.MemoryUsage', 7 'scrapy.extensions.corestats.CoreStats', 8 'scrapy.extensions.telnet.TelnetConsole'] 9 2018-07-23 16:07:43 [scrapy.middleware] INFO: Enabled downloader middlewares: 10 ['scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware', 11 'scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware', 12 'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware', 13 'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware', 14 'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware', 15 'scrapy.downloadermiddlewares.retry.RetryMiddleware', 16 'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware', 17 'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware', 18 'scrapy.downloadermiddlewares.redirect.RedirectMiddleware', 19 'scrapy.downloadermiddlewares.cookies.CookiesMiddleware', 20 'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware', 21 'scrapy.downloadermiddlewares.stats.DownloaderStats'] 22 2018-07-23 16:07:43 [scrapy.middleware] INFO: Enabled spider middlewares: 23 ['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware', 24 'scrapy.spidermiddlewares.offsite.OffsiteMiddleware', 25 'scrapy.spidermiddlewares.referer.RefererMiddleware', 26 'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware', 27 'scrapy.spidermiddlewares.depth.DepthMiddleware'] 28 2018-07-23 16:07:43 [scrapy.middleware] INFO: Enabled item pipelines: 29 [] 30 2018-07-23 16:07:43 [scrapy.extensions.telnet] DEBUG: Telnet console listening on 127.0.0.1:6023 31 2018-07-23 16:07:43 [scrapy.core.engine] INFO: Spider opened 32 2018-07-23 16:07:45 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://www.itcast.cn/robots.txt> (referer: None) 33 2018-07-23 16:07:46 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://www.itcast.cn/channel/teacher.shtml> (referer: None) ['partial'] 34 [s] Available Scrapy objects: 35 [s] scrapy scrapy module (contains scrapy.Request, scrapy.Selector, etc) 36 [s] crawler <scrapy.crawler.Crawler object at 0x7f61eb8be0b8> 37 [s] item {} 38 [s] request <GET http://www.itcast.cn/channel/teacher.shtml> 39 [s] response <200 http://www.itcast.cn/channel/teacher.shtml> 40 [s] settings <scrapy.settings.Settings object at 0x7f61e57c4898> 41 [s] spider <ItcastSpider 'itcast' at 0x7f61e5354978> 42 [s] Useful shortcuts: 43 [s] fetch(url[, redirect=True]) Fetch URL and update local objects (by default, redirects are followed) 44 [s] fetch(req) Fetch a scrapy.Request and update local objects 45 [s] shelp() Shell help (print this help) 46 [s] view(response) View response in a browser
- response()的用法:
- dir(response):
1 >>> dir(response) 2 ['_DEFAULT_ENCODING', '__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__slots__', '__str__', '__subclasshook__', '__weakref__', '_auto_detect_fun', '_body', '_body_declared_encoding', '_body_inferred_encoding', '_cached_benc', '_cached_selector', '_cached_ubody', '_declared_encoding', '_encoding', '_get_body', '_get_url', '_headers_encoding', '_set_body', '_set_url', '_url', 'body', 'body_as_unicode', 'copy', 'css', 'encoding', 'flags', 'follow', 'headers', 'meta', 'replace', 'request', 'selector', 'status', 'text', 'url', 'urljoin', 'xpath']
-
- response.css:
1 >>> response.css("div.li_txt")[0].extract() 2 '<div class="li_txt"> <h3>朱老师</h3> <h4>高级讲师</h4> <p>15年以上的软件开发、大型软件项目设计和团队管理经验。精通C/C++、pascal、Basic等各种编程语言,精通MySQL、Oracle、SQLServer等关系数据库。讲课深入浅出,将复杂理论转化为通俗易懂的语言,深受学生的好评。</p> </div>' 3 >>> response.css("div.li_txt")[1].extract() 4 '<div class="li_txt"> <h3>王老师</h3> <h4>高级讲师</h4> <p>毕业于山东大学,计算机硕士。具有10年项目开发、项目管理经验,任事业部技术总监,长期一线项目经理。主持开发过的项目涉及银行、政府等应用领域。多年企业内训培训师,讲课深入浅出,深受学生和企业员工的好评。</p> </div>'
-
- response.xpath:
1 >>> response.xpath("//div[@class='li_txt']")[1].extract #注意:要加() 2 <bound method Selector.get of <Selector xpath="//div[@class='li_txt']" data='<div class="li_txt"> <h3>王老师</h3'>> 3 4 >>> response.xpath("//div[@class='li_txt']")[1].extract() 5 '<div class="li_txt"> <h3>王老师</h3> <h4>高级讲师</h4> <p>毕业于山东大学,计算机硕士。具有10年项目开发、项目管理经验,任事业部技术总监,长期一线项目经理。主持开发过的项目涉及银行、政府等应用领域。多年企业内训培训师,讲课深入浅出,深受学生和企业员工的好评。</p> </div>' 6 7 >>> response.xpath("//div[@class='li_txt']/h3")[1].extract() 8 '<h3>王老师</h3>' 9 10 >>> response.xpath("//div[@class='li_txt']/h3/text()")[1].extract() 11 '王老师' 12 13 >>> response.xpath("//div[@class='li_txt']/h4/text()")[1].extract() 14 '高级讲师' 15 16 >>> response.xpath("//div[@class='li_txt']/p/text()")[1].extract() 17 '毕业于山东大学,计算机硕士。具有10年项目开发、项目管理经验,任事业部技术总监,长期一线项目经理。主持开发过的项目涉及银行、政府等应用领域。多年企业内训培训师,讲课深入浅出,深受学生和企业员工的好评。'
Example2:
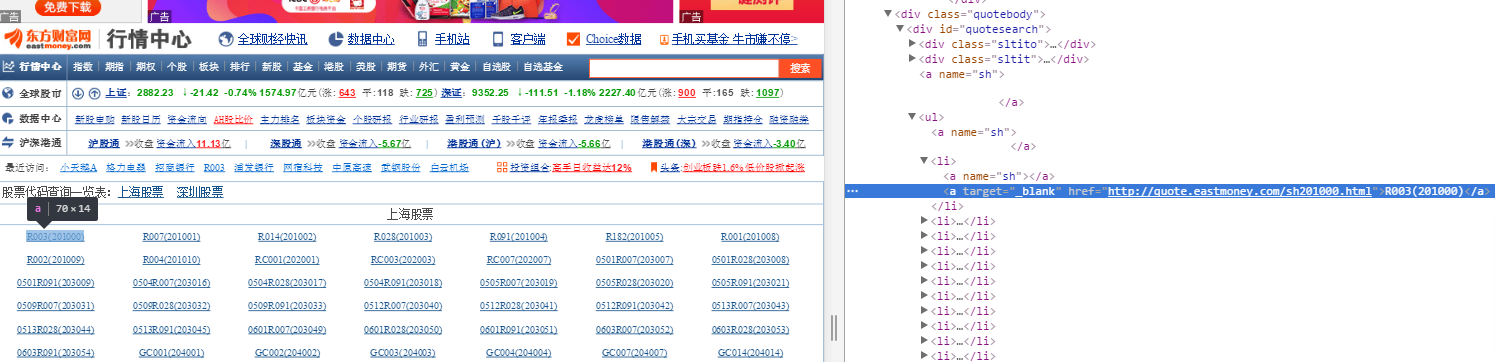
1 >>> stocklist = response.xpath("//div[@id='quotesearch']/ul/li/a/text()") #no extract() 2 3 >>> print (type(stocklist)) 4 <class 'scrapy.selector.unified.SelectorList'> #still a selector 5 6 >>> print (dir(stocklist)) 7 ['__add__', '__class__', '__contains__', '__delattr__', '__delitem__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__getslice__', '__getstate__', '__gt__', '__hash__', '__iadd__', '__imul__', '__init__', '__iter__', '__le__', '__len__', '__lt__', '__module__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__reversed__', '__rmul__', '__setattr__', '__setitem__', '__sizeof__', '__slots__', '__str__', '__subclasshook__', '__weakref__', 'append', 'attrib', 'clear', 'copy', 'count', 'css', 'extend', 'extract', 'extract_first', 'extract_unquoted', 'get', 'getall', 'index', 'insert', 'pop', 're', 're_first', 'remove', 'reverse', 'select', 'sort', 'x', 'xpath'] 8 9 >>> print (stocklist) 10 .... 11 <Selector xpath="//div[@id='quotesearch']/ul/li/a/text()" data='御家汇(300740)'>, <Selector xpath="//div[@id='quotesearch']/ul/li/a/text()" data='华宝股份(300741)'>, <Selector xpath="//div[@id='quotesearch']/ul/li/a/text()" data='越博动力(300742)'>, <Selector xpath="//div[@id='quotesearch']/ul/li/a/text()" data='天地数码(300743)'>, <Selector xpath="//div[@id='quotesearch']/ul/li/a/text()" data='欣锐科技(300745)'>, <Selector xpath="//div[@id='quotesearch']/ul/li/a/text()" data='汉嘉设计(300746)'>, <Selector xpath="//div[@id='quotesearch']/ul/li/a/text()" data='锐科激光(300747)'>, <Selector xpath="//div[@id='quotesearch']/ul/li/a/text()" data='宁德时代(300750)'>] 12 13 >>> print(stocklist[100]) 14 <Selector xpath="//div[@id='quotesearch']/ul/li/a/text()" data='中证500C(501037)'> 15 16 >>> stocklist = response.xpath("//div[@id='quotesearch']/ul/li/a/text()").extract() #to call the method of extract() 17 18 >>> print(type(stocklist)) 19 <class 'list'> 20 21 >>> print(stocklist) 22 [...'乐歌股份(300729)', '科创信息(300730)', '科创新源(300731)', '设研院(300732)', '西菱动力(300733)', '光弘科技(300735)', '百华悦邦(300736)', '科顺股份(300737)', '奥飞数据(300738)', '明阳电路(300739)', '御家汇(300740)', '华宝股份(300741)', '越博动力(300742)', '天地数码(300743)', '欣锐科技(300745)', '汉嘉设计(300746)', '锐科激光(300747)', '宁德时代(300750)'] 23 24 >>> print(stocklist[100]) 25 中证500C(501037) 26 27 28 >>> stocklist = response.xpath("//div[@id='quotesearch']") 29 30 >>> stock = stocklist.xpath("./ul/li/a/text()") #注意./ 31 32 >>> print(type(stock)) 33 <class 'scrapy.selector.unified.SelectorList'> 34 35 >>> print(stock[100]) 36 <Selector xpath='./ul/li/a/text()' data='中证500C(501037)'>
1 >>> stocklist = response.css("div#quotesearch") #without extract() 2 3 >>> print(type(stocklist)) 4 <class 'scrapy.selector.unified.SelectorList'> 5 6 >>> print(stocklist) 7 [<Selector xpath="descendant-or-self::div[@id = 'quotesearch']" data='<div id="quotesearch"> <div'>] 8 9 >>> stocklist = response.css("div#quotesearch").extract() #call the method extract() 10 11 >>> print(type(stocklist)) 12 <class 'list'> 13 14 >>>print(stocklist) = print(stocklist[0]) #在列表中只有一个项目 15 [... <li><a target="_blank" href="http://quote.eastmoney.com/sz300743.html">天地数码(300743)</a></li> <li><a target="_blank" href="http://quote.eastmoney.com/sz300745.html">欣锐科技(300745)</a></li> <li><a target="_blank" href="http://quote.eastmoney.com/sz300746.html">汉嘉设计(300746)</a></li> <li><a target="_blank" href="http://quote.eastmoney.com/sz300747.html">锐科激光(300747)</a></li> <li><a target="_blank" href="http://quote.eastmoney.com/sz300750.html">宁德时代(300750)</a></li> </ul> </div>'] 16 17 #CSS与xpath不同,不能像xpath那样有“root”和“/ 。/ //”的概念。 18 >>> stocklist = response.css("div#quotesearch") 19 >>> stock = stocklist.css("./ul/li/a::text") 20 Traceback (most recent call last): 21 File "/usr/lib/python3.5/code.py", line 91, in runcode 22 exec(code, self.locals) 23 File "<console>", line 1, in <module> 24 File "/home/tlfox/.local/lib/python3.5/site-packages/parsel/selector.py", line 93, in css 25 return self.__class__(flatten([x.css(query) for x in self])) 26 File "/home/tlfox/.local/lib/python3.5/site-packages/parsel/selector.py", line 93, in <listcomp> 27 return self.__class__(flatten([x.css(query) for x in self])) 28 File "/home/tlfox/.local/lib/python3.5/site-packages/parsel/selector.py", line 262, in css 29 return self.xpath(self._css2xpath(query)) 30 File "/home/tlfox/.local/lib/python3.5/site-packages/parsel/selector.py", line 265, in _css2xpath 31 return self._csstranslator.css_to_xpath(query) 32 File "/home/tlfox/.local/lib/python3.5/site-packages/parsel/csstranslator.py", line 109, in css_to_xpath 33 return super(HTMLTranslator, self).css_to_xpath(css, prefix) 34 File "/home/tlfox/.local/lib/python3.5/site-packages/cssselect/xpath.py", line 192, in css_to_xpath 35 for selector in parse(css)) 36 File "/home/tlfox/.local/lib/python3.5/site-packages/cssselect/parser.py", line 355, in parse 37 return list(parse_selector_group(stream)) 38 File "/home/tlfox/.local/lib/python3.5/site-packages/cssselect/parser.py", line 368, in parse_selector_group 39 yield Selector(*parse_selector(stream)) 40 File "/home/tlfox/.local/lib/python3.5/site-packages/cssselect/parser.py", line 376, in parse_selector 41 result, pseudo_element = parse_simple_selector(stream) 42 File "/home/tlfox/.local/lib/python3.5/site-packages/cssselect/parser.py", line 432, in parse_simple_selector 43 result = Class(result, stream.next_ident()) 44 File "/home/tlfox/.local/lib/python3.5/site-packages/cssselect/parser.py", line 743, in next_ident 45 raise SelectorSyntaxError('Expected ident, got %s' % (next,)) 46 cssselect.parser.SelectorSyntaxError: Expected ident, got <DELIM '/' at 1>
- 我们之前在mySpider/items.py里定义了一个ItcastItem类,这里引入进来:
1 from mySpider.items import ItcastItem
- 然后将我们得到的数据封装到一个ItcastItem对象中,可以保存每个老师的属性:(./mySpider/spiders/itcast.py)
1 # -*- coding: utf-8 -*- 2 import scrapy 3 from mySpider.items import ItcastItem 4 5 class ItcastSpider(scrapy.Spider): 6 #爬虫名,启动爬虫时需要的参数*必需) 7 name = 'itcast' 8 9 #爬取域范围,允许爬虫在这个域名下进行爬取(可选) 10 allowed_domains = ['itcast.cn'] 11 12 # 起始url列表,爬虫执行后第一批请求,将从这个列表里获取。 13 start_urls = ['http://www.itcast.cn/channel/teacher.shtml',] 14 15 def parse(self, response): 16 node_list = response.xpath("//div[@class='li_txt']") 17 18 #用来存储所有的item字段的 19 #items = [] 20 for node in node_list: 21 #创建item字段对象,用来存储信息。 22 item = ItcastItem() 23 #.extract()将xpath对象转换为Unicode字符串 24 name = node.xpath("./h3/text()").extract() 25 title = node.xpath("./h4/text()").extract() 26 info = node.xpath("./p/text()").extract() 27 28 item['name']=name[0] 29 item['title']=title[0] 30 item['info']=info[0] 31 32 #items.append(item) 33 #放回提取到的每个item数据,给管道文件来处理,同时放回到for循环,继续执行for循环代码。 34 yield items 35
yield的作用是:它把数据返回到一个管道中,等处理网数据之后,它会回到for循环的初始位置,执行没有完成的for循环语句,直到for循环语句结束之后方法才会结束。
另一种实现方式:
1 # -*- coding: utf-8 -*- 2 import scrapy 3 from mySpider.items import ItcastItem 4 5 class ItcastSpider(scrapy.Spider): 6 #爬虫名,启动爬虫时需要的参数*必需) 7 name = 'itcast' 8 9 #爬取域范围,允许爬虫在这个域名下进行爬取(可选) 10 allowed_domains = ['itcast.cn'] 11 12 # 起始url列表,爬虫执行后第一批请求,将从这个列表里获取。 13 start_urls = ['http://www.itcast.cn/channel/teacher.shtml',] 14 15 def parse(self, response): 16 node_list = response.xpath("//div[@class='li_txt']") 17 18 #用来存储所有的item字段的 19 items = [] 20 21 for node in node_list: 22 #创建item字段对象,用来存储信息。 23 item = ItcastItem() 24 #.extract()将xpath对象转换为Unicode字符串 25 name = node.xpath("./h3/text()").extract() 26 title = node.xpath("./h4/text()").extract() 27 info = node.xpath("./p/text()").extract() 28 #xpath返回的是包含一个元素的列表 29 item['name']=name[0] 30 item['title']=title[0] 31 item['info']=info[0] 32 33 items.append(item) #放回提取到的每个item数据,给管道文件来处理,同时放回到for循环,继续执行for循环代码。 34 35 #直接返回最后数据 36 return items
保存数据
scrapy保存信息的最简单的方式主要有四种,-o输出指点的文件,命令如下:
1 # json格式,默认为Unicode编码 2 scrapy crawl itcast -o teachers.json 3 4 # json lines格式,默认为Unicode编码 5 scrapy crawl itcast -o teachers.json1 6 7 # csv 逗号表示式,可用Excel打开 8 scrapy crawl itcast -o teachers.csv 9 10 # xml 格式: 11 scrapy crawl itcast -o teachers.xml
3. item pipeline
当item在spider中被收集之后,它将会被传递到item Pipeline,这些item Pipeline组件按定义的顺序处理item。
每个item Pipeline都是实现了简单方法的Python类,比如决定此item是丢弃而存储,以下是item pipeline的一些典型应用:
- 验证爬取的数据(检查item包含某些字段,比如说name字段)
- 查重(并丢弃)
- 将爬取结果保存到文件或者数据库中。
编写item pipeline
编写item pipeline很简单,item pipeline组件是一个独立的python类,其中process_item()方法必须实现:
/mySpider/settings
1 ITEM_PIPELINES = { 2 'ITcast.pipelines.ItcastPipeline':300, # 数越低,处理的优先级越高。 3 'ITcast.pipelines.xxxPipeline':400, 4 }