协程:实现单线程下并发的效果,这种多并发可以理解为在多个函数之间来回切换。Yield, Greenlet , Gevent,
这就是用yield,实现了单线程下并发的效果:
import time
import queuedef consumer(name): print("--->starting eating baozi...") while True: new_baozi = yield print("[%s] is eating baozi %s" % (name,new_baozi)) #time.sleep(1)def producer(): r = con.__next__() r = con2.__next__() n = 0 while n < 5: n +=1 con.send(n) con2.send(n) print("�33[32;1m[producer]�33[0m is making baozi %s" %n )if __name__ == '__main__': con = consumer("c1") con2 = consumer("c2") p = producer()协程好处:
1. 无需线程上下文切换的开销,只是利用 yield 实现了函数见的切换。
2. 无需原子操作锁定及同步的开销:协程是在单线程里实现的,协程在执行时,是串行的,所以就不需要锁。("原子操作(atomic operation)是不需要synchronized",所谓原子操作是指不会被线程调度机制打断的操作;这种操作一旦开始,就一直运行到结束,中间不会有任何 context switch (切换到另一个线程)。原子操作可以是一个步骤,也可以是多个操作步骤,但是其顺序是不可以被打乱,或者切割掉只执行部分。视作整体是原子性的核心。)
3. 方便切换控制流,简化编程模型
4. 高并发+高扩展性+低成本:一个CPU支持上万的协程都不是问题。所以很适合用于高并发处理(多少个协程都是在一个线程里)。
缺点:
1. 无法利用多核资源:协程的本质是个单线程,它不能同时将 单个CPU 的多个核用上,协程需要和进程配合才能运行在多CPU上.当然我们日常所编写的绝大部分应用都没有这个必要,除非是cpu密集型应用。(Nagix就是单线程,它实现大并发就是靠上万个协程并发)
2. 进行阻塞(Blocking)操作(如IO时)会阻塞掉整个程序
符合什么条件就能称之为协程:
- 必须在只有一个单线程里实现并发
- 修改共享数据不需加锁,因为程序是串行执行。
- 用户程序里自己保存多个控制流的上下文栈
- 一个协程遇到IO操作自动切换到其它协程
事件驱动与异步IO,处理事件过程大致如下:
1. 有一个事件(消息)队列;
2. 鼠标按下时,往这个队列中增加一个点击事件(消息);
3. 有个循环,不断从队列取出事件,根据不同的事件,调用不同的函数,如onClick()、onKeyDown()等;
4. 事件(消息)一般都各自保存各自的处理函数指针,这样,每个消息都有独立的处理函数;

事件驱动编程是一种编程范式,这里程序的执行流由外部事件来决定。它的特点是包含一个事件循环,当外部事件发生时使用回调机制 (callback()) 来触发相应的处理。另外两种常见的编程范式是(单线程)同步以及多线程编程。
让我们用例子来比较和对比一下单线程、多线程以及事件驱动编程模型。下图展示了随着时间的推移,这三种模式下程序所做的工作。这个程序有3个任务需要完成,每个任务都在等待I/O操作时阻塞自身。阻塞在I/O操作上所花费的时间已经用灰色框标示出来了。单线程和多线程都在各自的IO阻塞中等待,而异步IO则没有阻塞。
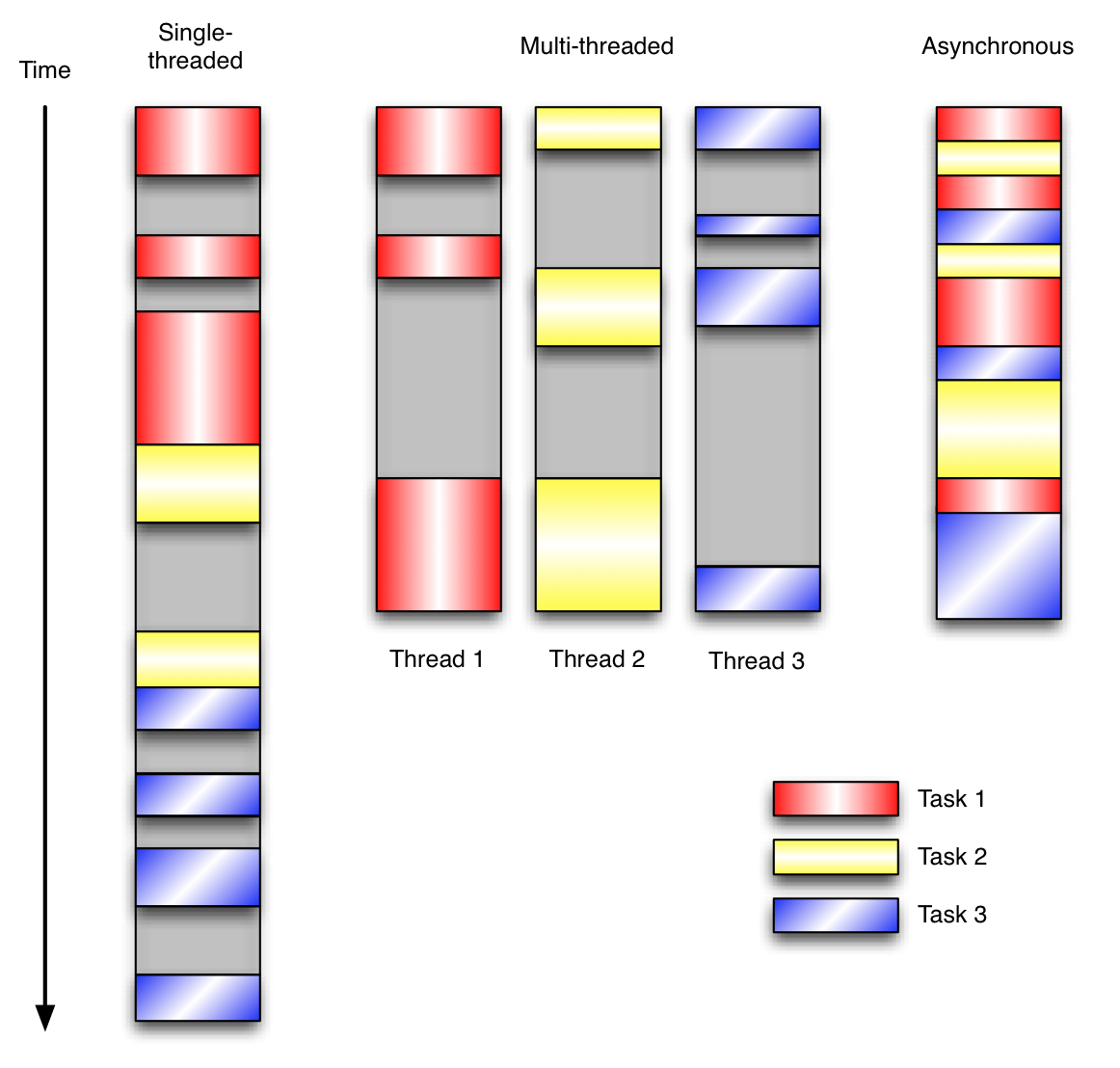
实现异步IO的方法就是加一个callback()函数。原理如下:每当程序遇到IO操作,就交给系统执行IO操作,并给系统一个callback()函数,而自己执行下一个协程;当系统执行完IO操作时,系统会自动调用回调函数并返回执行前一个协程,继续执行。
Linux & Unix
1. 用户空间与内核空间
现在操作系统都是采用虚拟存储器,那么对32位操作系统而言,它的寻址空间(虚拟存储空间)为4G(2的32次方)。操作系统的核心是内核,独立于普通的应用程序,可以访问受保护的内存空间,也有访问底层硬件设备的所有权限。为了保证用户进程不能直接操作内核(kernel),保证内核的安全,操心系统将虚拟空间划分为两部分,一部分为内核空间,一部分为用户空间。针对linux操作系统而言,将最高的1G字节(从虚拟地址0xC0000000到0xFFFFFFFF),供内核使用,称为内核空间,而将较低的3G字节(从虚拟地址0x00000000到0xBFFFFFFF),供各个进程使用,称为用户空间。
2. 文件描述符fd
文件描述符(File descriptor)是计算机科学中的一个术语,是一个用于表述指向文件的引用的抽象化概念。文件描述符在形式上是一个非负整数。当用户要访问一个文件时,内核向打开文件的进程返回一个文件描述符(一个数字)。进程会按照文件描述符去打开所对应的文件对象。
3. 缓存 I/O
缓存 I/O 又被称作标准 I/O,大多数文件系统的默认 I/O 操作都是缓存 I/O。在 Linux 的缓存 I/O 机制中,操作系统会将 I/O 的数据缓存在文件系统的页缓存( page cache )中,也就是说,数据会先被拷贝到操作系统内核的缓冲区中,然后才会从操作系统内核的缓冲区拷贝到应用程序的地址空间。 即,当用户接收数据的时候,系统会将数据放入I/O缓存页面中,再将数据考入内核地址空间,然后才会把数据copy给程序空间,供进程所使用。
4. IO模式
对于一次IO访问(以read举例),数据会先被拷贝到操作系统内核的缓冲区中,然后才会从操作系统内核的缓冲区拷贝到应用程序的地址空间。所以说,当一个read操作发生时,它会经历两个阶段:
1. 等待数据准备 (Waiting for the data to be ready)
2. 将数据从内核拷贝到进程中 (Copying the data from the kernel to the process)
linux系统产生了下面五种网络模式的方案。
- 阻塞 I/O(blocking IO)
- 非阻塞 I/O(nonblocking IO)
- I/O 多路复用( IO multiplexing)
- 信号驱动 I/O( signal driven IO)
- 异步 I/O(asynchronous IO)
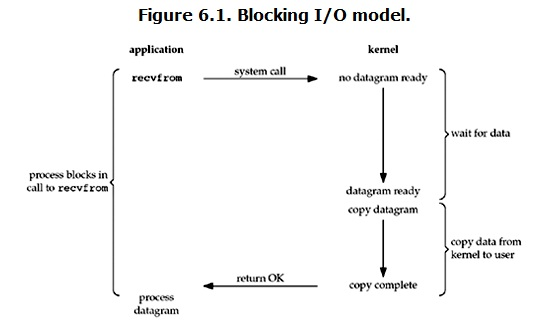
在blocking IO的模式下,没有办法实现多sockets。因为第一个线程卡住了,即便其他线程来了数据据也处理不了。
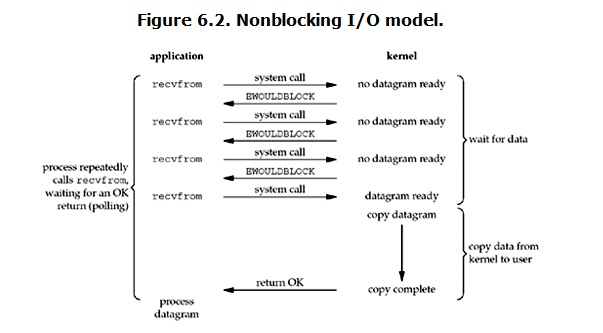
在non-blocking IO的模式下,可以实现多sockets。这种情况下,我循环100个sockets(连接),如果没有数据,我就直接走下一个循环(线程),所以不会卡住(不影响其他线程)。对同一个用户开来,这种模式下可以实现多并发了。但从内核态到用户态,还是会卡(等待数据从内核态考到用户态)。
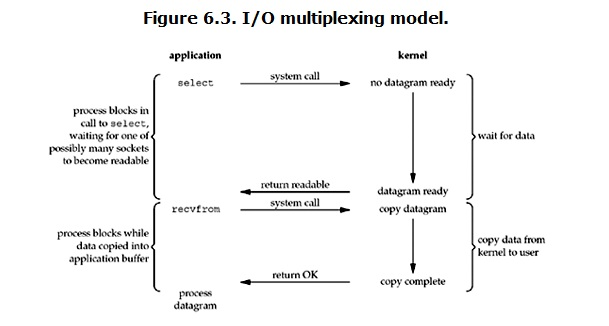
IO多路复用的模式下,即select,poll,epoll,function 不断的轮询所负责的所有sockets,当某个socket有数据到达了,就通知用户进程。这与blocking IO相似,但不同的是,select直接传了100个sockets句柄,告诉kernel帮忙检测一批socket,100个sockets中,任何一个socket的数据可读,就告诉程序接收数据。
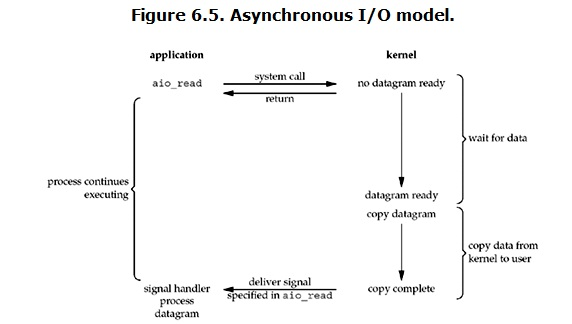
IO异步的情况下,用户进程发起read操作之后,立刻就可以开始去做其它的事。而另一方面,从kernel的角度,当它受到一个asynchronous read之后,首先它会立刻返回,所以不会对用户进程产生任何block。然后,kernel会等待数据准备完成,然后将数据拷贝到用户内存,当这一切都完成之后,kernel会给用户进程发送一个signal,告诉它read操作完成了。
blocking和non-blocking的区别
调用blocking IO会一直block住对应的进程直到操作完成,而non-blocking IO在kernel还准备数据的情况下会立刻返回。
synchronous IO和asynchronous IO的区别
在说明synchronous IO和asynchronous IO的区别之前,需要先给出两者的定义。POSIX的定义是这样子的:
- A synchronous I/O operation causes the requesting process to be blocked until that I/O operation completes;
- An asynchronous I/O operation does not cause the requesting process to be blocked;
两者的区别就在于synchronous IO做”IO operation”的时候会将process阻塞。按照这个定义,之前所述的blocking IO,non-blocking IO,IO multiplexing都属于synchronous IO。

select,poll,epoll都是IO多路复用的机制。I/O多路复用就是通过一种机制,一个进程可以监视多个描述符,一旦某个描述符就绪(一般是读就绪或者写就绪),能够通知程序进行相应的读写操作。
1. 如果select监控100个sockets (默认最多1024个),并交给kernel去监测,但100个sockets内,有一个连接活跃了,就会给告诉程序去取数据,但哪个连接有数据不知道。select得循环查找哪个连接是活跃的,然后再取数据。
2. pollfd并没有最大数量限制(但是数量过大后性能也是会下降),和select函数一样,poll返回后,需要轮询pollfd来获取就绪的描述符。
3. epoll跟select一样,监控100个sockets,并交给kernel去监测,只不过,100个socket内,有一个socket活跃了,kernel会告诉用户哪个连接有数据。
相对于select和poll来说,epoll更加灵活,没有描述符限制(可以处理好几十万的连接,靠内存大小,一个连接占4K的内存)。epoll使用一个文件描述符管理多个描述符,将用户关系的文件描述符的事件存放到内核的一个事件表中,这样在用户空间和内核空间的copy只需一次。
select,poll,epoll都属于IO多路复用,当数据来了没有取,数据是存放在内核内存。
水平触发:告诉进程哪些文件描述符刚刚变为就绪状态,如果数据没有取走,会再次告知。
边缘触发:Edge Triggered,只告诉进程哪些文件描述符刚刚变为就绪状态,它只说一遍,如果我们没有采取行动,那么它将不会再次告知,这种方式称为边缘触发)