MapReduce概述
MapReduce是一种分布式计算模型,由Google提出,主要用于搜索领域,解决 海量数据的计算问题。MR由两个阶段组成:Map和Reduce,用户只需要实现map()
和reduce()两个函数,即可实现分布式计算。这两个函数的形参是key、value对,表 示函数的输入信息。
MapReduce结构
一个完整的mapreduce程序在分布式运行时有三类实例进程:
- MRAppMaster:负责整个程序的过程调度及状态协调
- mapTask:负责map阶段的整个数据处理流程
- ReduceTask:负责reduce阶段的整个数据处理流程
MapReduce的执行流程
执行流程图:
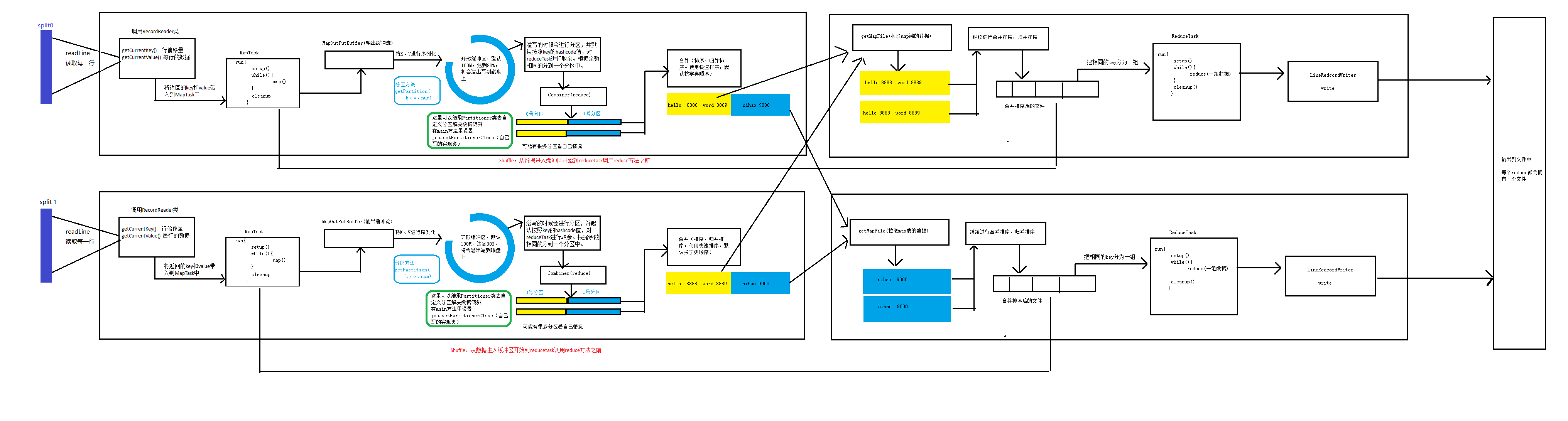
MapReduce流程执行解析
Map阶段:
切片的计算:
long splitSize = Math.max(minSize, Math.min(maxSize, blockSize))
默认:minSize 1
maxSize Long.MAX_VALUE
blockSize 128
splitSize默认是128M。
- FileInputFormat先扫描切片,每次扫描一行数据,调用RecordReader类中的getCurrentKey()、getCurrentValue()返回一个key(行偏移量),value(每行的内容)。
- context将返回的key和value带入到MapTask中,让map方法去进行处理。
- map方法处理完以后,将处理后的key、value进行序列化,写入到环形缓冲区中。(默认是100M)。当环形缓冲区到达80%以后,就会将里面的内容进行溢写。
- 溢写的时候会进行分区,并默认按照key的hashcode值,对reduceTask进行取余。根据余数相同的分到一个分区中。在分区时还会进行排序,默认按字典顺序。使用快速排序。
- Key -> key的hashcode ->根据reduceTask的个数取余->根据取余的结果进行分区。
- 在MapTask结束的时候,会将相同分区的数据聚合到一块。并进行排序,使用归并排序。
- MapTask自此结束。
Reduce阶段:
- Reduce端会将map端处理完以后的文件,相同分区的拉取到一块。进行合并和排序,归并排序。
- 一个ReduceTask去处理一个分区的数据。
- ReduceTask会根据相同的key分组,key相同的数据被分为了一组。
- 一组数据去调用一次reduce方法。
- 一个reduceTask处理完以后写入到一个reduceTask文件中。