一.配置好fiddler和手机
让手机能够通过fiddler代理访问网络
二.抓包
打开快手APP,Fiddler会快速显示很多信息,这些都是手机传送或者接收到的信息。可以逐个包点开,以json形式查看是否是我们需要的内容,如下图所示:
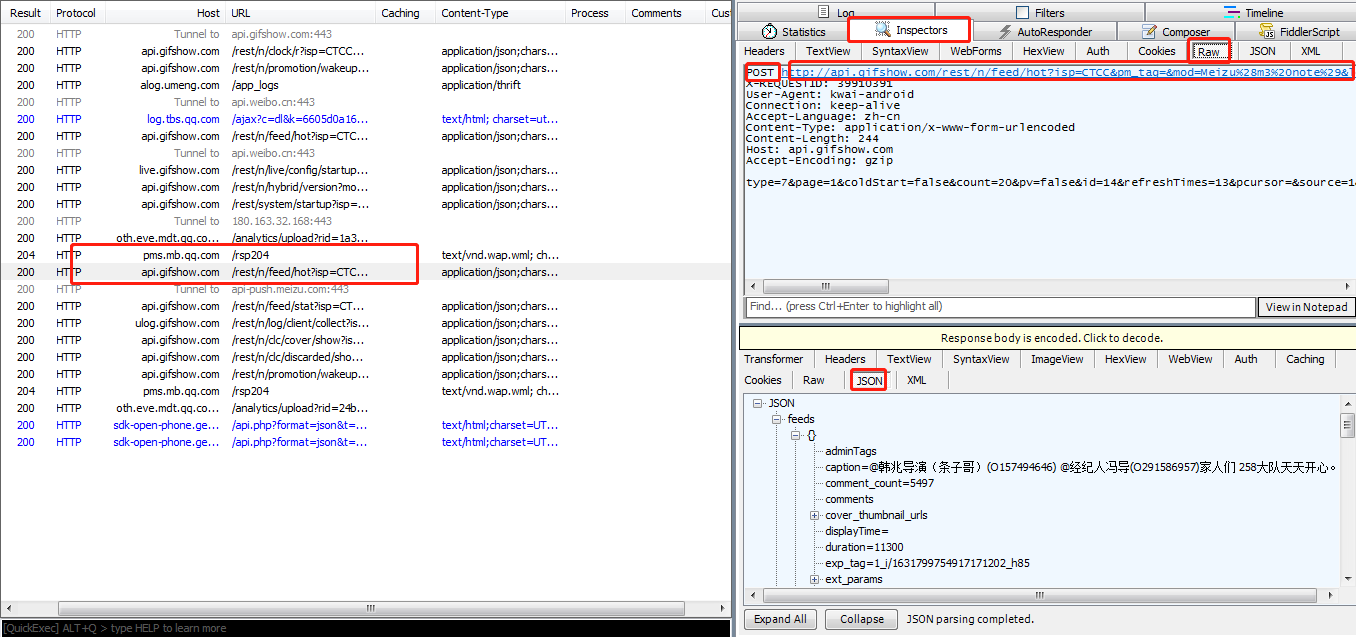
这时可以看到,有一个包里显示了很多信息,包括视频的标题,发布者,再往下拉,发现里面包含很多叫做“main_mv_url"的标签,复制其中一个标签后的url到浏览器,发现浏览器下载了一个mp4格式的视频,点开视频,就是我们需要的。为了让列表中只显示我们需要的包,让视图更清晰,可以用过滤器,只显示URL中含/rest/n/feed/的内容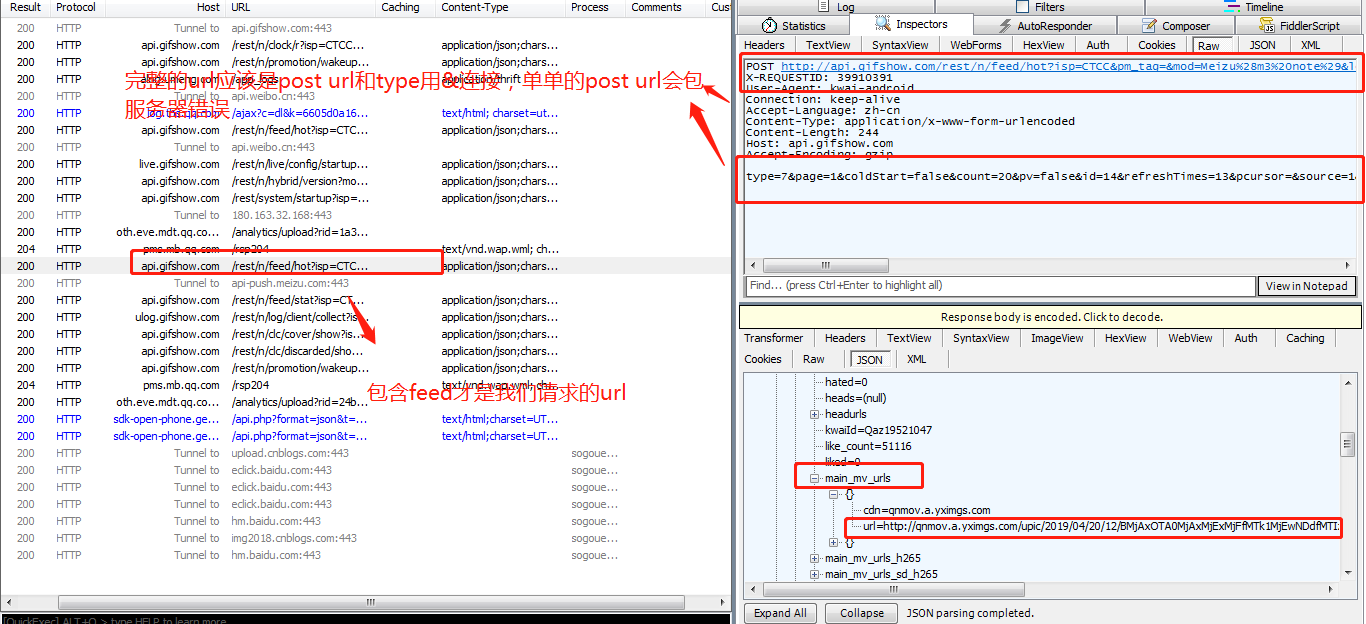
回到Fiddler,看之前那个包的头(Fiddler右上窗口),上面有个url,可以复制到浏览器会发现打开的不是和Fiddler右下角一样的json界面,而是显示服务器繁忙,因为这个url是不完整的。注意右上窗口最后一行有个“type=......”这其实是完整url的后半部分,要把它拼接到第一行POST url的后面,并且以&连接。把完整的url再复制到浏览器,得到和Fiddler右下窗口类似的内容(不是完全一样,因为视频内容会更新),ok

再观察“type=...”这串字符,可以多抓几个包对比一下,发现count后面跟着的数字是不一样的,即每个json里所含视频个数不一样。平均每个json中含有20个视频的下载链接。page后面的数字就代表页数,在快手界面不断的往下滑,隔一小段时间会有另一个包,可以发现page后的数字是递增的。__NStokensig和sig后跟的一串数字是没有规律可循的,要破解快手APP的代码才能知晓。所以无法掌握每个json的url变化规律,所以若是要抓取20个以上的视频,只能通过在快手app页面上往下滑动,抓包,copy完整的url到文本文件再用程序进行下载。
代码:
#!/usr/bin/env python # -*- coding: utf-8 -*- #author tom import pprint import requests import json import time import random class Kuaishouspider: #这个是抓包抓到的数据请求url,要和后面的type用&拼接起来 def __init__(self): self.url='http://api.ksapisrv.com/rest/n/feed/hot?isp=CTCC&pm_tag=&mod=Meizu%28m3%20note%29&lon=113.968423&country_code=cn&kpf=ANDROID_PHONE&extId=92fa9b653b19ecd11e0840d87c04822c&did=ANDROID_e1b34c4ac9ddf120&kpn=KUAISHOU&net=WIFI&app=0&oc=MEIZU&ud=0&hotfix_ver=&c=MEIZU&sys=ANDROID_7.0&appver=6.3.3.8915&ftt=&language=zh-cn&iuid=&lat=22.583945&did_gt=1556199685379&ver=6.3&max_memory=256&type=7&page=1&coldStart=false&count=20&pv=false&id=25&refreshTimes=2&pcursor=&source=1&needInterestTag=false&browseType=1&seid=8dae8f66-01cf-4580-b703-41e6b563d775&volume=0.0&client_key=3c2cd3f3&os=android&sig=518db63518ffba8fca5c70724750dc95' self.headers={ 'Content-Type': 'application/x-www-form-urlencoded', 'Host': 'api.ksapisrv.com', 'Accept-Language': 'zh-Hans-CN;q=1' } #抓包里面的数据 self.data={ 'client_key':'3c2cd3f3', 'coldStart':'false', 'count':'20', 'country_code':'cn', 'id':'25', 'language':'zh-Hans-CN;q=1', 'pv':'false', 'refreshTimes':'2', 'sig': '518db63518ffba8fca5c70724750dc95', 'source':'1', 'type':'7' } self.count=0 def kuaishou_request(self): while True: #用来计数的 self.count+=1 #返回的json数据,我们从里面解析出视频的uerl res=requests.post(self.url,data=self.data,headers=self.headers) list=res.json()['feeds'] #list里面装着每一个视频的详细信息,包括我们所需要的视频url for info in list: pprint.pprint(info) print('描述%s'%info['caption']) print('视频连接%s'%info['main_mv_urls'][0]['url']) print('作者%s'%info['user_name']) print('id%s'%info['user_id']) print('第%s次抓取完成'%self.count) time.sleep(random.randint(500,700)) if __name__ == '__main__': ks=Kuaishouspider() ks.kuaishou_request()
代码