python 爬虫 ———— 彼岸图片
首先下载爬取过程需要的一些库 (如下载过慢,可切换镜像源重新下载: 查看镜像源)
一、下载库:
1、requests
pip install requests -i https://pypi.douban.com/simple
2、lxml
pip install lxml==4.1.1 -i https://pypi.tuna.tsinghua.edu.cn/simple
二、页面路径进行分析:
可以很清晰的看到除了第一页的路径有些不大相同,后面的页数几乎大同小异,只需要修改page中的数字即可
1、使用for循环解决问题:
import requests
from lxml import etree
for i in range(20): # 设置爬取的页数 if i == 0: # 第一页的内容 url = "http://www.netbian.com/e/search/result/?searchid=108" else: # 2、3......19 循坏+1 的形式实现页数的链接中的变化(增长),从而拿到爬取的页数 url = "http://www.netbian.com/e/search/result/index.php?page=%s&searchid=108" % (i + 1)
2、 获取页面的内容、设置请求头和cookies(关于headeras 和 cookies,这里有一个的工具:https://curl.trillworks.com/ 用法:页面检查-NetWork-copy-Copy all as cURL(cmd)-复制到工具curl command-会自动生成对应的headers 和 cookies)
# 获取爬取的页面, 设置headers、cookies response = requests.get(url=url, headers=headers, cookies=cookies) # 设置响应内容的编码格式与页面相同 response.encoding = response.apparent_encoding # print(response.text) # 打印获取到的页面内容
效果:(页面数据)

看到上面这张图片,证明页面的数据信息已经获取完成。
第一次爬取大意了,直接就获取页面的URL链接进行爬取,结果拿到的图片全是一些缩略图。
3、需要通过缩略图的地址拿到原图。截取了一张图片,方便理解。 缩略图 —— 原图(大小比较)
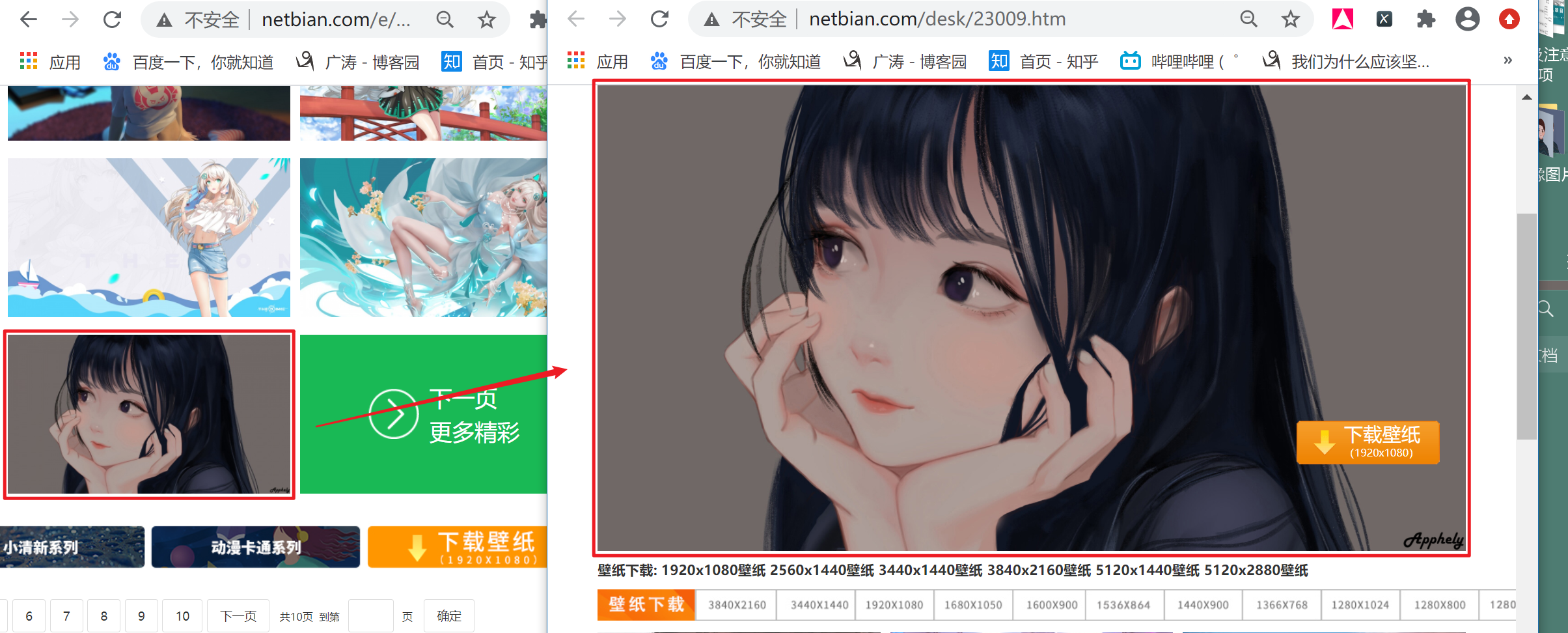
![]()
4、使用xpath来获取缩略图的图片链接
# 使用etree类来获取页面内容 tree = etree.HTML(response.text) # 使用xpath的语法获取指定的图片详情页链接,得到图片链接集 base_img_href = tree.xpath('//*[@id="main"]/div[3]/ul/li/a/@href') print(base_img_href) # 打印获取到的图片链接集合
5、循环整个页面的缩略图的href链接进行拼接,得到原图的页面,然后使用xpath拿到图片的链接、名称等
# 遍历集合 for img_href in base_img_href: # 对图片链接进行拼接,拿到外部可访问的完整的链接 img_response = requests.get("http://www.netbian.com" + img_href) # 设置响应内容的编码格式与页面相同 img_response.encoding = response.apparent_encoding # 使用etree内置的函数来获取图片详情页面内容 tree = etree.HTML(img_response.text) # 获取图片的地址 img_urls = tree.xpath('//*[@id="main"]/div[3]/div/p/a/img/@src') # 获取图片的名称 img_names = tree.xpath('//*[@id="main"]/div[3]/div/p/a/img/@title') # print(img_urls, img_names) # 打印图片的链接、名称
6、通过链接匹配下载到页面中所有原图,以title作为图片名称保存
for img_url in img_urls: # 获取图片的地址 img = requests.get(img_url) for img_name in img_names: # 给获取到的图片名称加上后缀--jpg name = img_name + ".jpg" # 保存图片并以name变量设置为 with open("./彼岸壁纸/%s" % name, "wb")as f: f.write(img.content) print("%s图片保存成功" % name) print("第%s页保存成功!!!" % (i + 1))
完整代码


import requests from lxml import etree """ 彼岸桌面--动漫 动漫--url路径 # http://www.netbian.com/e/search/result/?searchid=108 # http://www.netbian.com/e/search/result/index.php?page=2&searchid=108 # http://www.netbian.com/e/search/result/index.php?page=3&searchid=108 # 设置cookies cookies = { '__cfduid': 'd04239090d5bb8b416432271ca34428821608083693', 'xygkqlastsearchtime': '1608167009', 'Hm_lvt_14b14198b6e26157b7eba06b390ab763': '1608083694,1608164971,1608168408', 'xygkqecookieinforecord': '^%^2C19-22661^%^2C19-23032^%^2C19-23009^%^2C19-23015^%^2C19-23084^%^2C', 'Hm_lpvt_14b14198b6e26157b7eba06b390ab763': '1608177829', } # 设置请求头 headers = { 'Connection': 'keep-alive', 'Cache-Control': 'no-cache', 'Upgrade-Insecure-Requests': '1', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36', 'Accept': 'image/webp,image/apng,image/*,*/*;q=0.8', 'Referer': 'http://www.netbian.com/desk/23032.htm', 'Accept-Language': 'zh-CN,zh;q=0.9', 'Sec-Fetch-Site': 'cross-site', 'Sec-Fetch-Mode': 'no-cors', 'Sec-Fetch-Dest': 'image', 'If-None-Match': 'fc902a69c746e5bb8329e3d8284c0230', 'Pragma': 'no-cache', } for i in range(10): # 设置爬取的页数 if i == 0: # 第一页的内容 url = "http://www.netbian.com/e/search/result/?searchid=108" else: # 2、3、4......。 循坏+1 的形式实现页数的链接中的变化(增长),从而拿到爬取的页 url = "http://www.netbian.com/e/search/result/index.php?page=%s&searchid=108" % (i + 1) # 获取爬取的页面, 设置headers、cookies response = requests.get(url=url, headers=headers, cookies=cookies) # 设置响应内容的编码格式与页面相同 response.encoding = response.apparent_encoding # print(response.text) # 打印获取到的页面内容 # 使用etree类来获取页面内容 tree = etree.HTML(response.text) # 使用xpath的语法获取指定的图片详情页链接,得到图片链接集 base_img_href = tree.xpath('//*[@id="main"]/div[3]/ul/li/a/@href') print(base_img_href) # 打印获取到的图片链接集合 # 遍历链接集合 for img_href in base_img_href: # 对图片链接进行拼接,拿到外部可访问的完整的链接 img_response = requests.get("http://www.netbian.com" + img_href) # 设置响应内容的编码格式与页面相同 img_response.encoding = response.apparent_encoding # 使用etree内置的函数来获取图片详情页面内容 tree = etree.HTML(img_response.text) # 获取图片的地址 img_urls = tree.xpath('//*[@id="main"]/div[3]/div/p/a/img/@src') # 获取图片的名称 img_names = tree.xpath('//*[@id="main"]/div[3]/div/p/a/img/@title') # print(img_urls, img_names) # 打印图片的链接、名称 for img_url in img_urls: # 获取图片的地址 img = requests.get(img_url) for img_name in img_names: # 给获取到的图片名称加上后缀--jpg name = img_name + ".jpg" # 保存图片并以name变量设置为 with open("./彼岸壁纸/%s" % name, "wb")as f: # 写入图片二进制数据 f.write(img.content) print("%s图片保存成功" % name) print("第%s页保存成功!!!" % (i + 1))
下载图片:
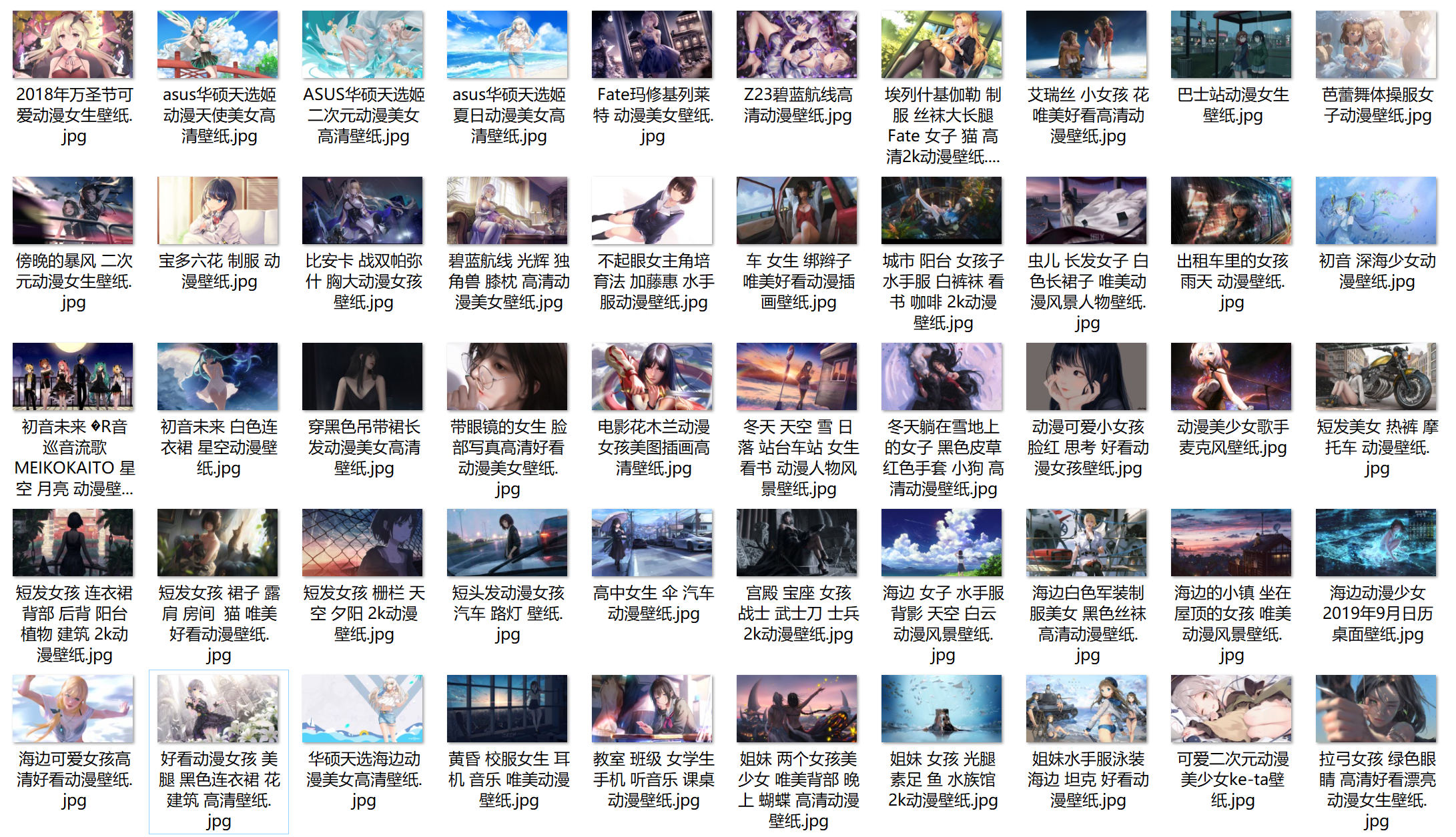
至此,彼岸图片的爬取完成!