1、count:查询记录条数
db.user.count()
它也跟find一样可以有条件的
db.user.count({"age":22})
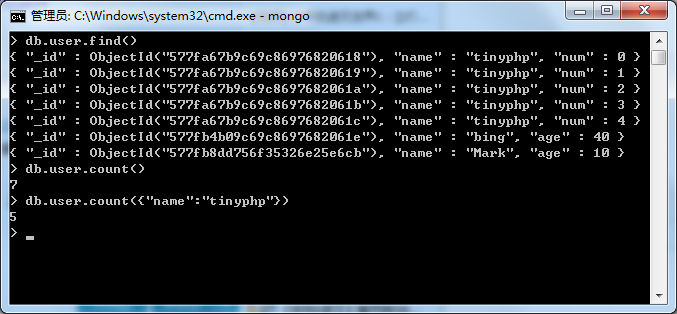
2、distinct:用来找出给定键的所有不同的值
db.user.distinct("num")

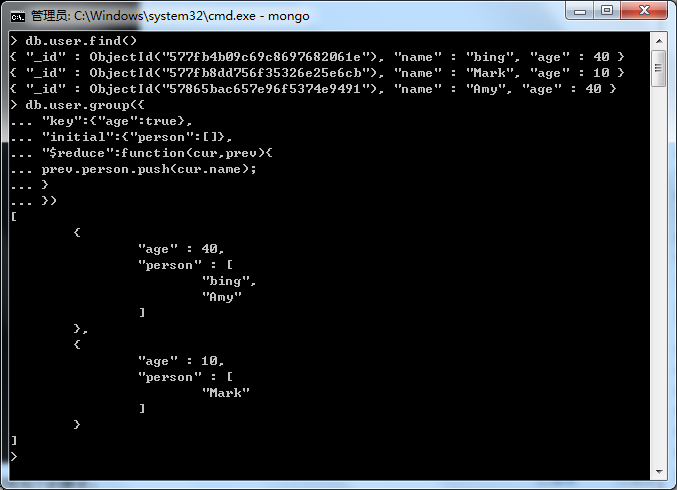
3、Group:分组查询
key:用来分组文档的字段,我们这里是对年龄分组
initial: 每组都分享一个”初始化函数“
$reduce: 执行的reduce函数,第一个参数是当前的文档对象,第二个参数是上一次function操作的累计对象,有多少个文档, $reduce就会调用多少次
db.user.group({ "key":{"age":true}, "initial":{"person":[]}, "$reduce":function(cur,prev){ prev.person.push(cur.name); } })
如果想再过滤掉age小于20的人,group有这么两个可选参数: condition 和 finalize
condition:执行过滤的条件
finalize:在reduce执行完成,结果集返回之前对结果集最终执行的函数。
db.user.group({ "key":{"age":true}, "initial":{"person":[]}, "$reduce":function(doc,out){ out.person.push(doc.name); }, "finalize":function(out){ out.count=out.person.length; }, "condition":{"age":{$lt:20}} })
4、MapReduce:
MongoDB中的MapReduce相当于关系数据库中的group by。
参数:
map函数:这个称为映射函数,里面会调用emit(key,value),集合会按照你指定的key进行映射分组。
reduce函数:这个称为简化函数,会对map分组后的数据进行分组简化,注意:在reduce(key,value)中的key就是emit中的key,vlaue为emit分组后的emit(value)的集合,。
mapReduce函数:这个就是最后执行的函数,参数为map,reduce和一些可选参数。
示例:
map函数,对age大于10的进行处理:
var m=function(){ if(this.age>10){ emit(this.age,{name:this.name}); } }
reduce函数:
var r=function(key,values){ var count=0; values.forEach(function(){count+=1;}); return count; }
执行:
db.user.mapReduce(m,r,{"out":"collection"})
查看输出集合“collecton”的情况
db.collection.find()

从结果集也可以看出,临时结果集中的_id是emit函数中的key。
从图中我们可以看到如下信息:
result: "存放的集合名“。
input:传入文档的个数。
emit:此函数被调用的次数。
reduce:此函数被调用的次数。
output:最后返回文档的个数。