Zookeeper 的核心是广播,这个机制保证了各个Server之间的同步。实现这个机制的协议叫做Zab协议。
Zab协议有两种模式,它们分别是恢复模式(选主)和广播 模式(同步)。当服务启动或者在领导者崩溃后,Zab就进入了恢复模式,当领导者被选举出来,且大多数Server完成了和leader的状态同步以后, 恢复模式就结束了。
状态同步保证了leader和Server具有相同的系统状态。为了保证事务的顺序一致性,zookeeper采用了递增的事务id号 (zxid)来标识事务。
所有的提议(proposal)都在被提出的时候加上了zxid。实现中zxid是一个64位的数字,它高32位是epoch用 来标识leader关系是否改变,每次一个leader被选出来,它都会有一个新的epoch,标识当前属于那个leader的统治时期。低32位用于递 增计数。
每个Server在工作过程中有三种状态:
LOOKING:当前Server不知道leader是谁,正在搜寻。
LEADING:当前Server即为选举出来的leader。
FOLLOWING:leader已经选举出来,当前Server与之同步。
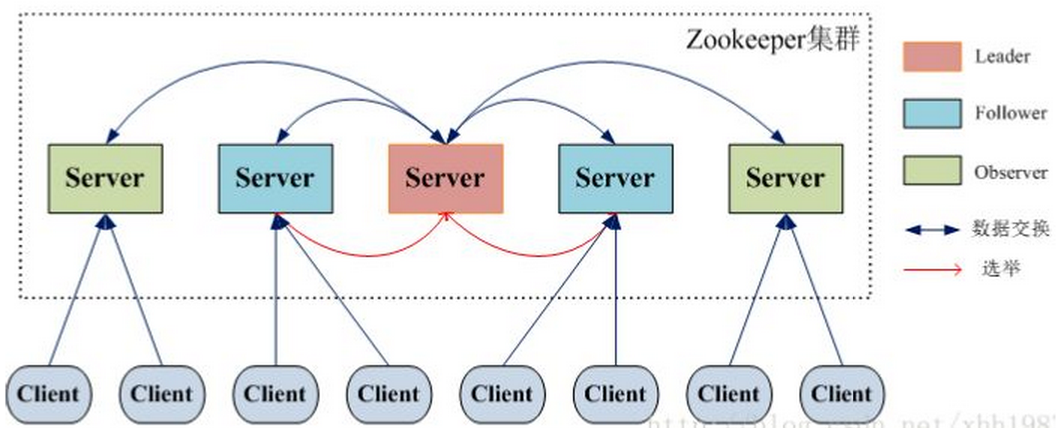
ZooKeeper的安装模式分为三种,分别为:单机模式、集群模式和集群伪分布模式
环境
CentOS7.0 (windows中使用就使用zkServer.cmd)
ZooKeeper最新版本
用root用户安装(如果用于hbase时将所有文件权限改为hadoop用户)
Java环境,最好是最新版本的。
分布式时多机间要确保能正常通讯,关闭防火墙或让涉及到的端口通过。
下载
去官网下载 :http://zookeeper.apache.org/releases.html#download
下载后放进CentOS中的/usr/local/ 文件夹中,并解压到当前文件中 /usr/local/zookeeper(怎么解压可参考之前的Haproxy的安装文章)
安装
单机模式
进入zookeeper目录下的conf子目录, 重命名 zoo_sample.cfg文件,Zookeeper 在启动时会找这个文件作为默认配置文件:
mv /usr/local/zookeeper/conf/zoo_sample.cfg zoo.cfg
配置zoo.cfg参数

# The number of milliseconds of each tick tickTime=2000 # The number of ticks that the initial # synchronization phase can take initLimit=10 # The number of ticks that can pass between # sending a request and getting an acknowledgement syncLimit=5 # the directory where the snapshot is stored. # do not use /tmp for storage, /tmp here is just # example sakes. dataDir=/usr/local/zookeeper/data dataLogDir=/usr/local/zookeeper/log # the port at which the clients will connect clientPort=2181 # # Be sure to read the maintenance section of the # administrator guide before turning on autopurge. # #http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance # # The number of snapshots to retain in dataDir #autopurge.snapRetainCount=3 # Purge task interval in hours # Set to "0" to disable auto purge feature #autopurge.purgeInterval=1
参数说明:
tickTime:毫秒值.这个时间是作为 Zookeeper 服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个 tickTime 时间就会发送一个心跳。
dataDir:顾名思义就是 Zookeeper 保存数据的目录,默认情况下,Zookeeper 将写数据的日志文件也保存在这个目录里。
dataLogDir:顾名思义就是 Zookeeper 保存日志文件的目录
clientPort:这个端口就是客户端连接 Zookeeper 服务器的端口,Zookeeper 会监听这个端口,接受客户端的访问请求。
再创建上面配置的data和log文件夹:
mkdir /usr/local/zookeeper/data mkdir /usr/local/zookeeper/log
启动zookeeper
先进入/usr/local/zookeeper文件夹
cd /usr/local/zookeeper
再运行
bin/zkServer.sh start
检测是否成功启动:执行
bin/zkCli.sh 或 echo stat|nc localhost 2181
伪集群模式
所谓伪集群, 是指在单台机器中启动多个zookeeper进程, 并组成一个集群. 以启动3个zookeeper进程为例,模拟3台机。
将zookeeper的目录多拷贝2份:
zookeeper/conf/zoo.cfg文件与单机一样,只改为下面的内容:
tickTime=2000 initLimit=5 syncLimit=2 dataDir=/usr/local/zookeeper/data dataLogDir=/usr/local/zookeeper/log clientPort=2180 server.0=127.0.0.1:2888:3888 server.1=127.0.0.1:2889:3889 server.2=127.0.0.1:2890:3890
新增了几个参数, 其含义如下:
1 initLimit: zookeeper集群中的包含多台server, 其中一台为leader, 集群中其余的server为follower. initLimit参数配置初始化连接时, follower和leader之间的最长心跳时间. 此时该参数设置为5, 说明时间限制为5倍tickTime, 即5*2000=10000ms=10s.
2 syncLimit: 该参数配置leader和follower之间发送消息, 请求和应答的最大时间长度. 此时该参数设置为2, 说明时间限制为2倍tickTime, 即4000ms.
3 server.X=A:B:C 其中X是一个数字, 表示这是第几号server. A是该server所在的IP地址. B配置该server和集群中的leader交换消息所使用的端口. C配置选举leader时所使用的端口. 由于配置的是伪集群模式, 所以各个server的B, C参数必须不同.
参照zookeeper/conf/zoo.cfg, 配置zookeeper1/conf/zoo.cfg, 和zookeeper2/conf/zoo.cfg文件. 只需更改dataDir, dataLogDir, clientPort参数即可.在之前设置的dataDir中新建myid文件, 写入一个数字, 该数字表示这是第几号server. 该数字必须和zoo.cfg文件中的server.X中的X一一对应.
/usr/local/zookeeper/data/myid文件中写入0, /usr/local/zookeeper1/data/myid文件中写入1, /Users/apple/zookeeper2/data/myid文件中写入2.
分别进入/usr/local/zookeeper/bin, /usr/local/zookeeper1/bin, /usr/local/zookeeper2/bin三个目录, 启动server。启动方法与单机一致。
bin/zkServer.sh start
分别检测是否成功启动:执行
bin/zkCli.sh 或 echo stat|nc localhost 2181
集群模式
集群模式的配置和伪集群基本一致.
由于集群模式下, 各server部署在不同的机器上, 因此各server的conf/zoo.cfg文件可以完全一样.
下面是一个示例:
tickTime=2000 initLimit=5 syncLimit=2 dataDir=/usr/local/zookeeper/data dataLogDir=/usr/local/zookeeper/log clientPort=2180 server.0=192.168.80.30:2888:3888 server.1=192.168.80.31:2888:3888 server.2=192.168.80.32:2888:3888
示例中部署了3台zookeeper server, 分别部署在192.168.80.30, 192.168.80.31, 192.168.80.32上.
需要注意的是, 各server的dataDir目录下的myid文件中的数字必须不同,192.168.80.30 server的myid为0, 192.168.80.31 server的myid为1, 192.168.80.32 server的myid为2
分别进入/usr/local/zookeeper/bin目录, 启动server。启动方法与单机一致。
bin/zkServer.sh start
分别检测是否成功启动:执行
bin/zkCli.sh 或 echo stat|nc localhost 2181
这时会报大量错误?其实没什么关系,因为现在集群只起了1台server,zookeeper服务器端起来会根据zoo.cfg的服务器列表发起选举leader的请求,因为连不上其他机器而报错,那么当我们起第二个zookeeper实例后,leader将会被选出,从而一致性服务开始可以使用,这是因为3台机器只要有2台可用就可以选出leader并且对外提供服务(2n+1台机器,可以容n台机器挂掉)。
ZooKeeper服务命令
1. 启动ZK服务: zkServer.sh start 2. 查看ZK服务状态: zkServer.sh status 3. 停止ZK服务: zkServer.sh stop 4. 重启ZK服务: zkServer.sh restart
zk客户端命令:
ZooKeeper 命令行工具类似于Linux的shell环境,使用它可以对ZooKeeper进行访问,数据创建,数据修改等操作.
使用 zkCli.sh -server 192.168.80.31:2181 连接到 ZooKeeper 服务,连接成功后,系统会输出 ZooKeeper 的相关环境以及配置信息。命令行工具的一些简单操作如下:
1. 显示根目录下、文件: ls / 使用 ls 命令来查看当前 ZooKeeper 中所包含的内容 2. 显示根目录下、文件: ls2 / 查看当前节点数据并能看到更新次数等数据 3. 创建文件,并设置初始内容: create /zk "test" 创建一个新的 znode节点“ zk ”以及与它关联的字符串 4. 获取文件内容: get /zk 确认 znode 是否包含我们所创建的字符串 5. 修改文件内容: set /zk "zkbak" 对 zk 所关联的字符串进行设置 6. 删除文件: delete /zk 将刚才创建的 znode 删除 7. 退出客户端: quit 8. 帮助命令: help