1、直接访问数据
Oracle直接访问表中数据的方法又分为两种:一种是全表扫描;另一种是ROWID扫描
1.1 全表扫描
全表扫描方法:
- 从第一个区(EXTENT)的第一个块(BLOCK)开始扫描,读取高水位线(High Water Mark)标记以下所有格式化块
- 可以过虑行
- 如允许则执行多块读 DB_FILE_MULTIBLOCK_READ_COUNT
- 数据量很大时,比索引范围扫描快
SQL> show parameter DB_FILE_MULTIBLOCK_READ_COUNT NAME TYPE VALUE ------------------------------------ ----------- ------------------------------ db_file_multiblock_read_count integer 120
注意:数据量越多,全表扫描所需要的时间就越多,然后直接删了表数据呢?查询速度会变快?其实并不会的,因为即使我们删了数据,高位水线并不会改变,也就是同样需要扫描那么多数据块
1.2 ROWID扫描
rowid需要10个字节来存储,由18个字符组成分4个部分.伪列类似表的列,但不实际存在于表中.ROWID也就是表数据行所在的物理存储地址,所谓的ROWID扫描是通过ROWID所在的数据行记录去定位。ROWID是一个伪列,数据库里并没有这个列,它是数据库查询过程中获取的一个物理地址,用于表示数据对应的行数。
分为 USER ROWID 和 INDEX ROWID两种
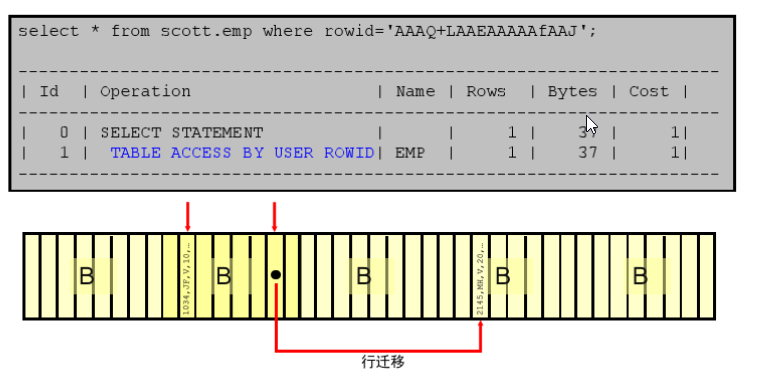

用sql查询:
SELECT T.BNAME,T.ROWID FROM TEST02T
随意获取一个ROWID序列:AAAR4GAANAAAAEEAAA,前6位表示对象编号(Data Object number),其后3位文件编号(Relative file number),接着其后6位表示块编号(Block number), 再其后3位表示行编号(Row number)

ROWID编码方法是:A ~ Z表示0到25;a ~ z表示26到51;0~9表示52到61;+表示62;/表示63;刚好64个字符。
这里随意找张表查一下文件编号、区编号、行编号,查询后会返回rowid的一系列物理地址和文件编号(rowid_relative_fno(rowid))、块编号(rowid_block_number(rowid))、行编号(rowid_row_number(rowid))
select BNAME,
rowid,
dbms_rowid.rowid_relative_fno(rowid),
dbms_rowid.rowid_block_number(rowid),
dbms_rowid.rowid_row_number(rowid)
from TEST02 select owner,object_id,data_object_id,status from dba_objects where object_name='USR02'; select file_name,file_id,relative_fno from dba_data_files;
1.3 Sample Table scan
2、访问索引
对于Oracle数据库来说,B树索引是最常见的了,下面给出B树索引的图,
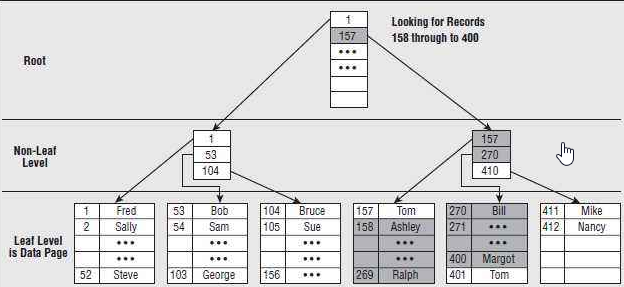
对于B树索引,分成两种类型的数据块,一种是索引分支块,另外一种是索引叶子块,索引根块是一种特殊的索引分支块。
影响逻辑读的缓存:
#清Buffer Cache
alter system flush buffer_cache;;//请勿随意在生产环境执行此语句 #清数据字典缓存(Data Dictionary Cache) alter system flush shared_pool;//请勿随意在生产环境执行此语句
2.1 索引唯一扫描
索引唯一性扫描(INDEX UNIQUE SCAN)是针对唯一性索引(UNIQUE INDEX)来说的,也就是建立唯一性索引才能索引唯一性扫描,唯一性扫描,其结果集只会返回一条记录。
创建唯一性索引SQL是:
drop table tx1 purge; create table tx1 as select * from dba_objects; update tx1 set object_id=rownum; commit; create unique index idx_id_type on tx1(object_id); set autotrace traceonly set linesize 160 exec dbms_stats.gather_table_stats('SYS','TX1',estimate_percent =>100,method_opt=>'for all indexed columns',cascade=>true); PL/SQL procedure successfully completed. SQL> select * from TX1 where object_id=188; Execution Plan ---------------------------------------------------------- Plan hash value: 581370042 ------------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | ------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | 132 | 2 (0)| 00:00:01 | | 1 | TABLE ACCESS BY INDEX ROWID| TX1 | 1 | 132 | 2 (0)| 00:00:01 | |* 2 | INDEX UNIQUE SCAN | IDX_ID_TYPE | 1 | | 1 (0)| 00:00:01 | ------------------------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 2 - access("OBJECT_ID"=188) Statistics ---------------------------------------------------------- 35 recursive calls 0 db block gets 31 consistent gets 0 physical reads 0 redo size 2685 bytes sent via SQL*Net to client 399 bytes received via SQL*Net from client 2 SQL*Net roundtrips to/from client 4 sorts (memory) 0 sorts (disk) 1 rows processed
2.2 索引范围扫描
索引范围扫描(INDEX RANGE SCAN)适用于所有类型的B树索引,一般不包括唯一性索引,因为唯一性索引走索引唯一性扫描。 当扫描的对象是非唯一性索引的情况,where谓词条件为Between、=、<、>等等的情况就是索引范围扫描,注意,可以是等值查询,也可以是范围查询。如果where条件里有一个索引键值列没限定为非空的,那就可以走索引范围扫描,如果改索引列是非空的,那就走索引全扫描
前面说了,同样的SQL建的索引不同,就可能是走索引唯一性扫描,也有可能走索引范围扫描。在同等的条件下,索引范围扫描所需要的逻辑读和索引唯一性扫描对比,逻辑读如何?索引范围扫描可能返回多条记录,所以优化器为了确认,肯定会多扫描,所以在同等条件,索引范围扫描所需要的逻辑读至少会比相应的唯一性扫描的逻辑读多1
drop table tx1 purge; create table tx1 as select * from dba_objects; update tx1 set object_id=rownum; commit; create index idx_id_type on tx1(object_id); SQL>set autotrace traceonly SQL>set linesize 160 SQL>exec dbms_stats.gather_table_stats('SYS','TX1',estimate_percent =>100,method_opt=>'for all indexed columns',cascade=>true); PL/SQL procedure successfully completed. SQL> select * from TX1 where object_id=188; Execution Plan ---------------------------------------------------------- Plan hash value: 2934712578 --------------------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | --------------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | 132 | 2 (0)| 00:00:01 | | 1 | TABLE ACCESS BY INDEX ROWID BATCHED| TX1 | 1 | 132 | 2 (0)| 00:00:01 | |* 2 | INDEX RANGE SCAN | IDX_ID_TYPE | 1 | | 1 (0)| 00:00:01 | --------------------------------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 2 - access("OBJECT_ID"=188) Statistics ---------------------------------------------------------- 35 recursive calls 0 db block gets 32 consistent gets 0 physical reads 0 redo size 2685 bytes sent via SQL*Net to client 399 bytes received via SQL*Net from client 2 SQL*Net roundtrips to/from client 4 sorts (memory) 0 sorts (disk) 1 rows processed
NOTE: 可以看到consistent gets , range scan 比 unique scan 多一个
INDEX UNIQUE SCAN : 31 consistent gets
INDEX RANGE SCAN : 32 consistent gets
2.3 索引全扫描
索引全扫描(INDEX FULL SCAN)适用于所有类型的B树索引(包括唯一性索引和非唯一性索引)。
索引全扫描过程简述:索引全扫描是指扫描目标索引所有叶子块的索引行,但不意思着需要扫描所有的分支块,索引全扫描时只需要访问必要的分支块,然后定位到位于改索引最左边的叶子块的第一行索引行,就可以利用改索引叶子块之间的双向指针链表,从左往右依次顺序扫描所有的叶子块的索引行
索引全扫描的例子:直接查emp表就好,因为empno是非空的
drop table tx1 purge; create table tx1 as select * from dba_objects; update tx1 set object_id=rownum; commit; alter table TX1 modify object_id not null; create index idx_id_type on TX1(object_id); set autotrace traceonly set linesize 160 exec dbms_stats.gather_table_stats('SYS','TX1',estimate_percent =>100,method_opt=>'for all indexed columns',cascade=>true); select * from TX1 order by object_id; Execution Plan ---------------------------------------------------------- Plan hash value: 3024276290 ------------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | ------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 73400 | 9461K| 1592 (1)| 00:00:01 | | 1 | TABLE ACCESS BY INDEX ROWID| TX1 | 73400 | 9461K| 1592 (1)| 00:00:01 | | 2 | INDEX FULL SCAN | IDX_ID_TYPE | 73400 | | 165 (1)| 00:00:01 | ------------------------------------------------------------------------------------------- Statistics ---------------------------------------------------------- 35 recursive calls 0 db block gets 11290 consistent gets 0 physical reads 0 redo size 4915612 bytes sent via SQL*Net to client 54221 bytes received via SQL*Net from client 4895 SQL*Net roundtrips to/from client 4 sorts (memory) 0 sorts (disk) 73400 rows processed
2.4 索引快速全扫描
索引快速全扫描和索引全扫描很类似,也适用于所有类型的B树索引(包括唯一性索引和非唯一性索引)。和索引全扫描类似,也是扫描所有叶子块的索引行,这些都是索引快速全扫描和索引全扫描的相同点
索引快速全扫描和索引全扫描区别:
- 索引快速全扫描只适应于CBO(基于成本的优化器)
- 索引快速全扫描可以使用多块读,也可以并行执行
- 索引全扫描会按照叶子块排序返回,而索引快速全扫描则是按照索引段内存储块顺序返回
- 索引快速全扫描的执行结果不一定是有序的,而索引全扫描的执行结果是有序的,因为索引快速全扫描是根据索引行在磁盘的物理存储顺序来扫描的,不是根据索引行的逻辑顺序来扫描的
条件是使用复合索引,而且使用Hint
/*+ index_ffs(表名 索引名) */ select /*+ index_ffs(emp_test pk_emp_test) */ empno from emp_test;
--使用上面的例子
SQL> select count(*) from TX1 ; Execution Plan ---------------------------------------------------------- Plan hash value: 3091724858 ----------------------------------------------------------------------------- | Id | Operation | Name | Rows | Cost (%CPU)| Time | ----------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | 54 (0)| 00:00:01 | | 1 | SORT AGGREGATE | | 1 | | | | 2 | INDEX FAST FULL SCAN| IDX_ID_TYPE | 73400 | 54 (0)| 00:00:01 | ----------------------------------------------------------------------------- Statistics ---------------------------------------------------------- 1 recursive calls 0 db block gets 171 consistent gets 0 physical reads 0 redo size 551 bytes sent via SQL*Net to client 387 bytes received via SQL*Net from client 2 SQL*Net roundtrips to/from client 0 sorts (memory) 0 sorts (disk) 1 rows processed
2.5 索引跳跃式扫描
索引跳跃式扫描(INDEX SKIP SCAN)适用于所有类型的复合B树索引(包括唯一性索引和非唯一性索引),索引跳跃式扫描可以使那些在where条件中没有目标索引的前导列指定查询条件但是有索引的非前导列指定查询条件的目标SQL依然可以使用跳跃索引,定义解释有点绕,举个例子说明新建了复合索引:
create index 索引名 on 表名(列名1,列名2)
假如改目标SQL符合索引跳跃式扫描的条件,即使,只有列名1这个前导列,还是可以走索引跳跃式扫描的,这个就是跳跃式扫描,不需要如下sql,全部索引列都定位到
SQL> select * from 表名 where 列名1 = 条件1 and 列名2 = 条件2
SQL> SELECT * FROM TEST02 WHERE BNAME='XXXXXX' ;
drop table TX1 purge; create table TX1 as select * from dba_objects; update TX1 set object_type='TABLE'; commit; update TX1 set object_type='VIEW' where rownum<=30000; commit; create index idx_object_id on TX1(object_type,object_id); exec dbms_stats.gather_table_stats('SYS','TX1',estimate_percent =>100,method_opt=>'for all indexed columns',cascade=>true); set autotrace traceonly select * from TX1 where object_id=188; Execution Plan ---------------------------------------------------------- Plan hash value: 4103120730 ----------------------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | ----------------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | 129 | 4 (0)| 00:00:01 | | 1 | TABLE ACCESS BY INDEX ROWID BATCHED| TX1 | 1 | 129 | 4 (0)| 00:00:01 | |* 2 | INDEX SKIP SCAN | IDX_OBJECT_ID | 1 | | 3 (0)| 00:00:01 | ----------------------------------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 2 - access("OBJECT_ID"=188) filter("OBJECT_ID"=188) Statistics ---------------------------------------------------------- 36 recursive calls 0 db block gets 37 consistent gets 0 physical reads 0 redo size 2692 bytes sent via SQL*Net to client 399 bytes received via SQL*Net from client 2 SQL*Net roundtrips to/from client 4 sorts (memory) 0 sorts (disk) 1 rows processed
当然索引跳跃式扫描并不是说适用所有情况,不加前导列,有时候是不走跳跃式扫描的,Oracle中的索引跳跃式扫描仅仅适用于那些目标索引前导列的distinct值数量较少,后续非导列的可选择性又非常好的情况,索引跳跃式扫描的执行效率一定会随着目标索引前导列的distinct值数量的递增而递减的
2.6 Index join scan
2.7 using bitmap indexes
2.7 combining bitmap indexes
拓展补充
对于索引来说,如果索引条件有null值,是不走索引的