



那今天我们只考虑有label的猫跟狗的data,画一个boundary,将猫跟狗的train data分开的话,你可能就会画在中间(垂直)。
那如果unlabel的分布长的像灰色的点这个样子的话,这可能会影响你的决定。虽然unlabel data只告诉我们了input,但unlabeled data的分布可以告诉我们一些事。
那你可能会把boundary变为这样(斜线)。但是semi-supervised learning使用unlabel的方式往往伴随着一些假设,其实semi-supervised learning有没有用,是取决于你这个假设符不符合实际/精不精确
监督生成模型

半监督生成模型


但是由于不是凸函数,所以你要去iteratively solve这个函数
假设一:Low-density Separation

下来我们讲一个general的方式,这边基于的假设是Low-density Separation,也就是说:这个世界非黑即白的。什么是非黑即白呢?
非黑即白意思就是说:假设我们现在有一大堆的data(有label data,也有unlabel data),在两个class之间会有一个非常明显的红色boundary。比如说:现在两边都是label data,boundary 的话这两条直线都是可以的,
就可以把这两个class分开,在train data上都是100%。但是你考虑unlabel data的话,左边的boundary是比较好的,右边的boundary是不好的。
因为这个假设是基于这个世界是一个非黑即白的世界,这两个类之间会有一个很明显的界限。Low-density separation意思就是说,在这两个class交界处,density是比较低的。


基于熵的正则化

所以我们需要做的事情是,这个model的output在label data上分类整确,但在unlabel data上的entropy越小越好。所以根据这个假设,你就可以去重新设计你的loss function。
我们原来的loss function是说:我希望找一个参数,让我现在在label data上model的output跟正确的model output越小越好,你可以cross entropy evaluate它们之间的距离,这个是label data的部分。
在unlabel data的部分,你会加上每一笔unlabel data的output distribution的entropy,那你会希望这些unlabel data的entropy 越小越好。那么在这两个中间,你可以乘以一个weight(ln5ln5)来考虑说:
你要偏向unlabel data多一点还是少一点
在train的时候,用GD来一直minimize这件事情,没有什么问题的。unlabel data的角色就很像regularization,所以它被称之为 entropy-based regulariztion。
之前我们说regularization是在原来的loss function后面加一个惩罚项(L2,L1),让它不要overfitting;现在加上根据unlabel data得到的entropy 来让它不要overfitting。

假设二:Smoothness Assumption


那为什么会有Smoothness Assumption这样的假设呢?因为在真实的情况下是很多可能成立的
 比如说,我们考虑这个例子(手写数字辨识的例子)。看到这变有两个2有一个3,单纯算它们peixel相似度的话,搞不好,两个2是比较不像的,右边两个是比较像的(右边的2和3)。
比如说,我们考虑这个例子(手写数字辨识的例子)。看到这变有两个2有一个3,单纯算它们peixel相似度的话,搞不好,两个2是比较不像的,右边两个是比较像的(右边的2和3)。
如果你把你的data都通通倒出来的话,你会发现这个2(最左边)跟这个2(右边)中间有很多连续的形态(中间有很多不直接相连的相似,但是有很多stepping stones可以直接跳过去)。
所以根据smoothness Assumption的话,左边的2跟右边的2是比较像的,右边的2跟3中间没有过渡的形态,它们两个之间是不像的。如果看人脸辨识的是,也是一样的。
如果从一个人的左脸照一张相跟右脸照一张相,这是差很多的。如果你拿另外一个人眼睛朝左的相片来比较的话,会比较像这个跟眼睛朝右。如果你收集更多unlabel data的话,在这一张脸之间有很多过渡的形态,
眼睛朝左的脸跟眼睛朝向右的脸是同一个脸。
聚类和标记

如何实践这个smoothness assumption,最简单的方法是cluster and then label。现在distribution长这么样子,橙色是class1,绿色是class2,蓝色是unlabel data。
接下来你就做一下cluster,你可能分成三个cluster,然后你看cluster1里面class1的label data最多,所以cluster1里面所有的data都算是class1,cluster2,cluster3都算是class2、class3,然后把这些data拿去learn就结束了,
但是这个方法不一定有用。如果你今天要做cluster label,cluster要很强,因为这一招work的假设就是不同class cluster在一起。可是在image里面,把不同class cluster在一起是没有那么容易的。
我们之前讲过说,为什么要用deep learning,不同class可能会长的很像,也有可能长的不像,你单纯只有pixel来做class,你结果是会坏掉的。
如果你要让cluster and then label这个方法有用,你的class要很强。你要用很好的方法来描述image,我们自己试的时候我们会用deep autoendcoder,用这个来提取特征,然后再进行聚类。
基于图的方法
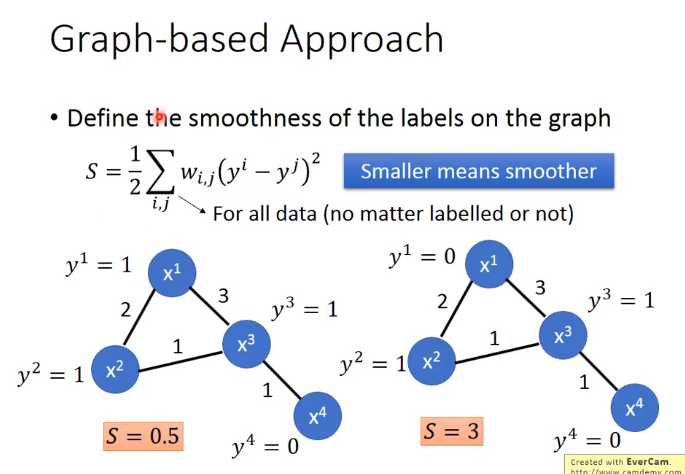
high density path的意思就是说,如果今天有两个点,他们在这个graph上面是相的(走的到),那么他们这就是同一个class,如果没有相连,就算实际的距离也不是很远,那也不是同一个class

建一个graph:有些时候这个graph representation是很自然就得到了。举例来说:假设你现在要做的是网页的分类,而你有记录网页之间的Hyperlink,
那Hyperlink就很自然的告诉你网页之间是如何连接的。假设现在做的是论文的分类,论文和论文之间有引用之间的关系,这个引用也是graph,可以很自然地把图画出来给你。

所谓的edge也不是只有相连不相连这样boundary的选择而已,你可以给edge一些weight,你可以让你的edge跟你的要被连接起来的两个data points的相似度是成正比的。
怎么定义这个相似度呢?我会建议比较好的选择就是Gaussian Radial Basis function来定义这个相似度。

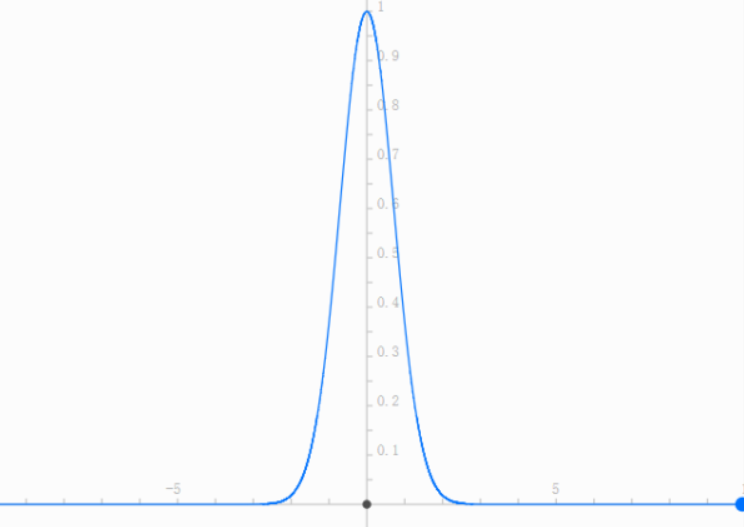
e^(-x^2)的图像
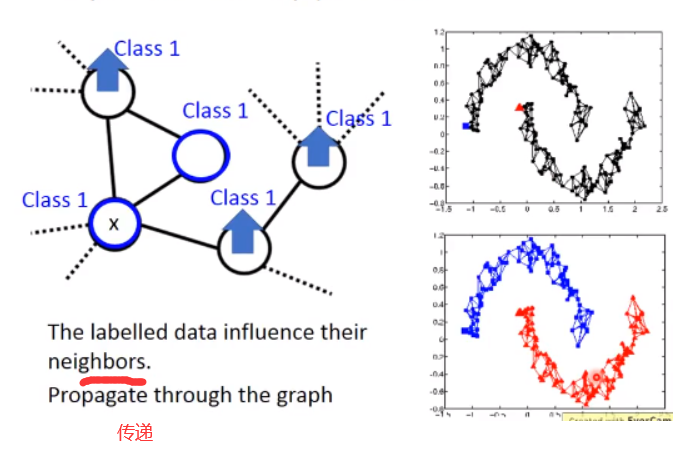
如果我们现在在graph上有一些label data,在这个graph上我们说这笔data1是属于class1,那跟它有相连的data points属于class1的几率也会上升,所以每笔data会影响它的邻居。
光是会影响它的邻居是不够的,如果你只考虑光是影响它的邻居的话可能帮助是不会太大。为什么呢?如果说相连的本来就很像,你train一个model,input很像output马上就很像的话,帮助不会太大。
那graph-based approach真正帮助的是:它的class是会传递的,本来这个点有跟class1相连所以它会变得比较像class1。但是这件事会像传染病一样传递过去,虽然这个点真正没有跟class1相连,
因为像class1这件事情是会感染,所以这件事情会通过graph link传递过来。
举例来说看这个例子,你把你的data points建成graph,这个如果是理想的例子的话,一笔label是属于class1(蓝色),一笔label是属于class2(红色)。经过garph-based approach,
你的graph建的这么漂亮的话(上面都是蓝色的,下面都是红色的).
你的data要足够多,如果data不够多的话,这个地方没收集到data,那这个点就断掉了,那这个information就传不过去了,比如下图就出现四个小的cluster。

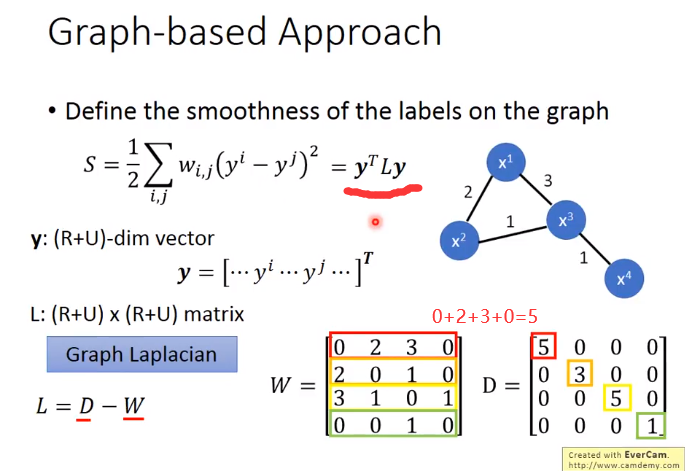


其实你要算smothness时不一定要放在output的地方,如果你今天是deep neural network的话,你可以把你的smothness放在network任何地方。你可以假设你的output是smooth,你也可以同时说:我把某一个hidden layer接出来再乘上别的一些transform,它也要是smooth,也可以说每一个hidden layer的output都是smooth
Better Representation
