异常检测


高斯分布
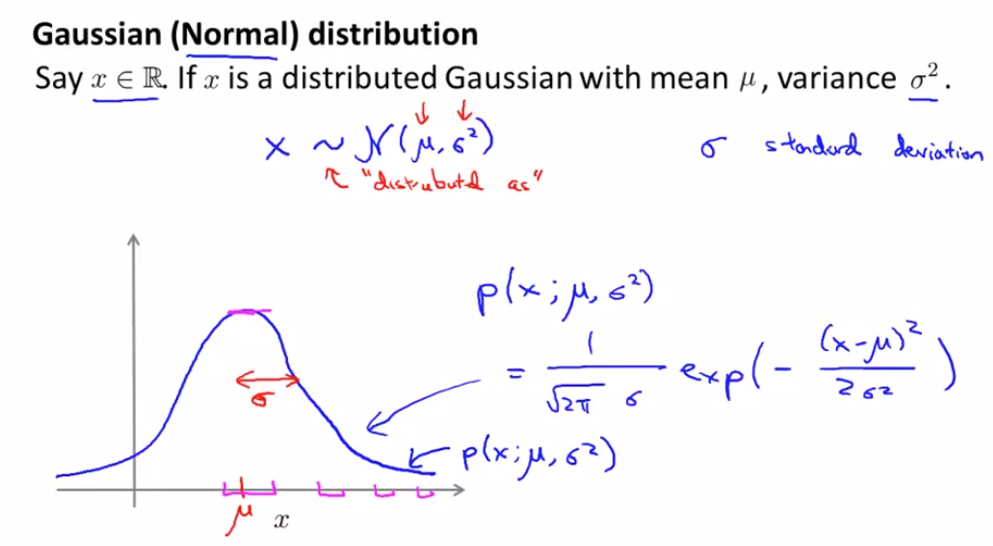
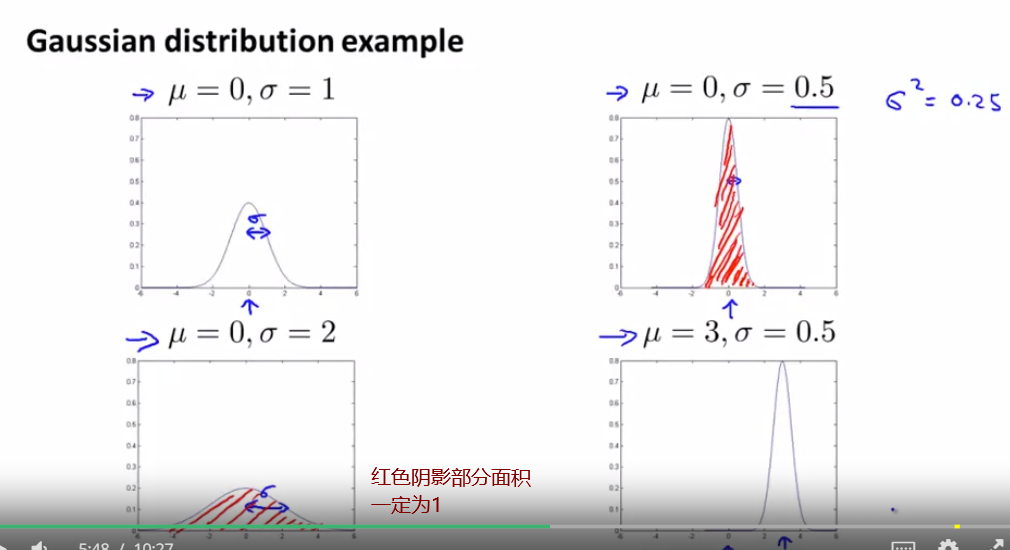
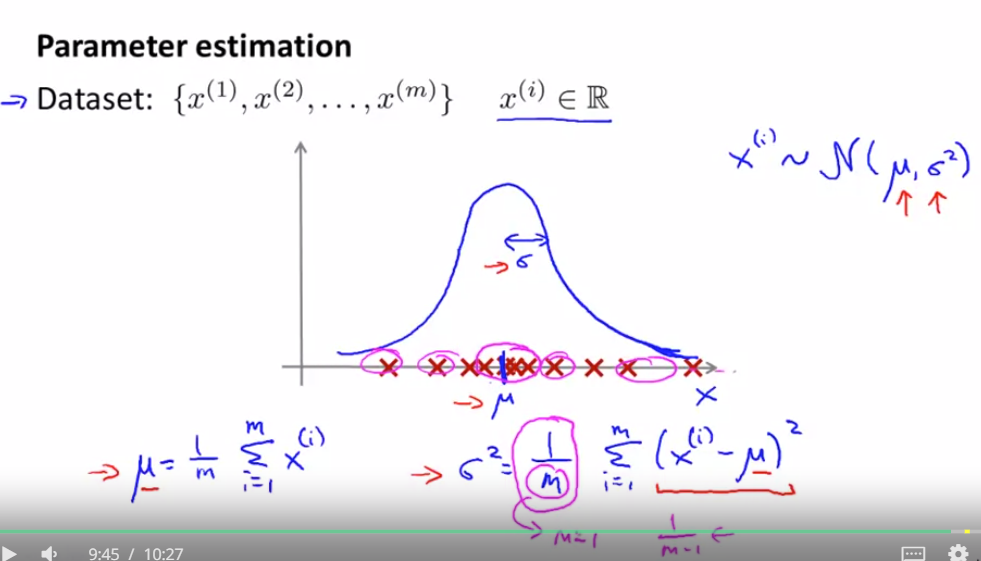

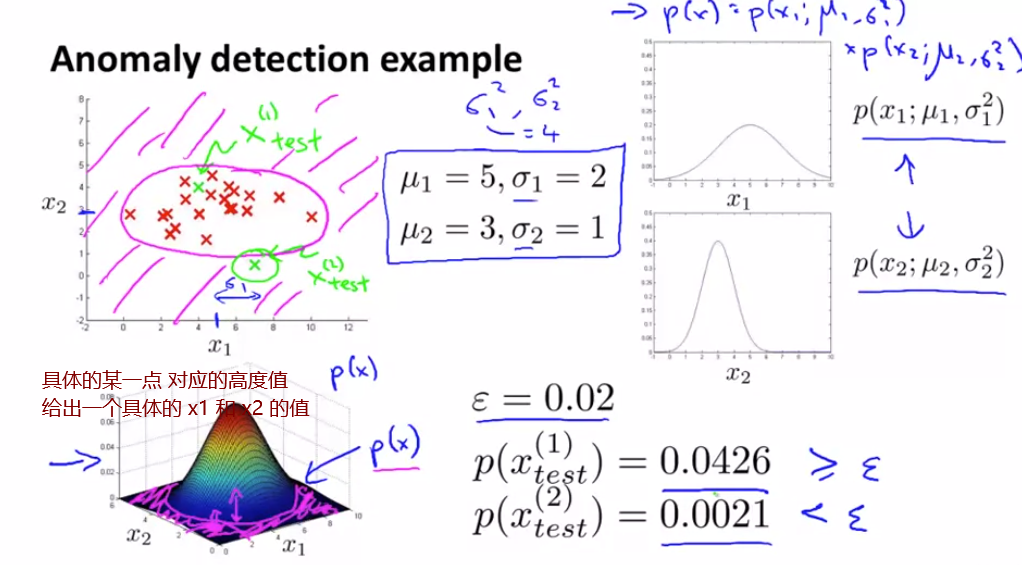




因为y=0 更常见
什么时候应该用 异常检测算法 什么时候用监督学习算法 是更有成效的 y=1 表示的是 异常的样本 关键的区别就是 在异常检测算法中 我们只有一小撮 正样本 因此学习算法不可能 从这些正样本中学出太多东西 因此取而代之的是 我们使用一组大量的 负样本 这样样本就能学到更多 或者说能从大量的负样本 比如大量的正常引擎样本中 学出 p(x) 模型 另外
我们预留一小部分 正样本来评价我们的算法 既用于交叉验证集 也用于测试集


对于欺诈检测(fraud detection) 如果你掌握了许多种 不同类型的 诈骗方法 并且相对较小的训练集 很少的一些你网站上 出现的欺诈用户 那我会使用异常检测算法
如果你是一个大型在线零售商 并且你掌握了 大量的 想要在你的网站上 实施诈骗犯罪的人 也就是说 你有很多 y=1 的样本 那么有时候 欺诈检测的方法也可能会 偏向于使用监督学习算法


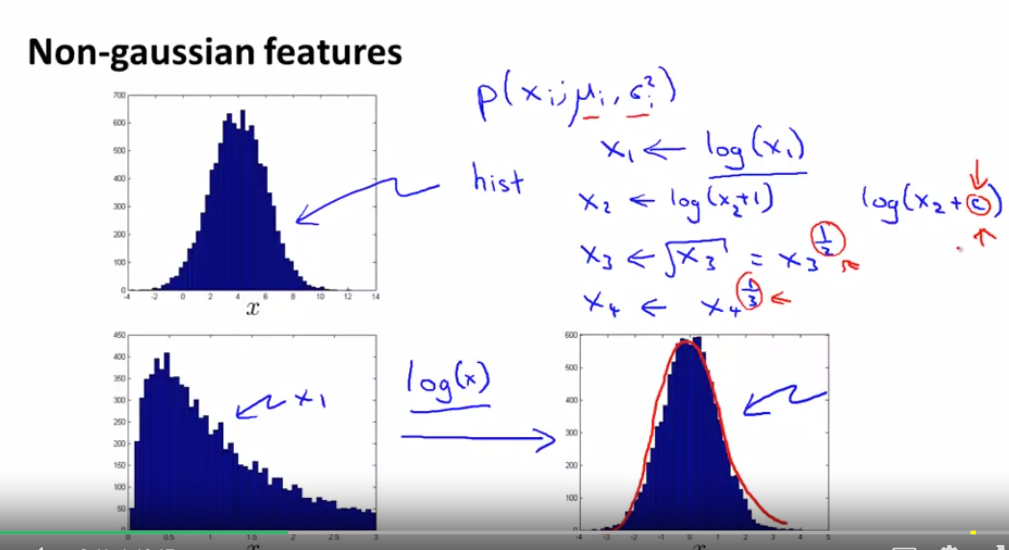
做的事情 是对数据进行一些不同的转换 来确保这些数据 .看起来更像高斯分布 虽然通常来说你不这么做 算法也会运行地很好
但如果你使用一些转换方法 使你的数据更像高斯分布的话 你的算法会工作得更好
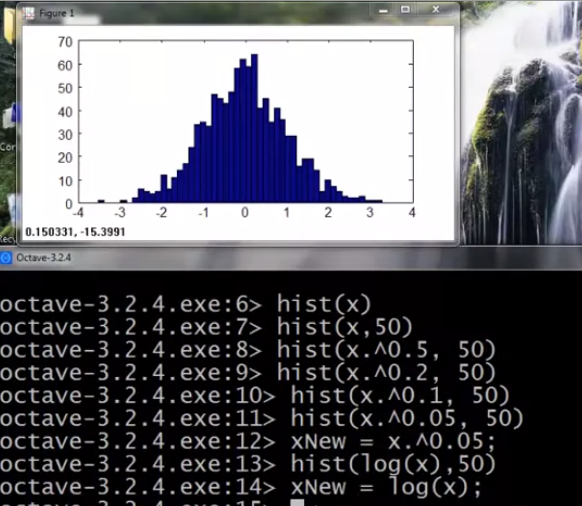
先加载1000个数据,尝试不同的函数令图像直方图更接近高斯分布

我们先完整地训练出 一个学习算法 然后在一组交叉验证集上运行算法 然后找出那些预测出错的样本 然后再看看 我们能否找到一些其他的特征变量 来帮助学习算法 让它在那些交叉验证时 判断出错的样本中表现更好 在异常检测中 我们希望 p(x) 的值 对正常样本来说是比较大的 而对异常样本来说 值是很小的 因此 一个很常见的问题是 p(x) 是具有可比性的 也许正常样本和异常样本的值都很大 我们来看一个具体点的例子 假如说这是我的无标签数据 那么 我只有一个特征变量 x1 我要用一个高斯分布来拟合它假如我的数据拟合出的高斯分布是这样的 假如我的异常样本中 x 的取值为2.5 因此 我画出我的异常样本 你不难发现 它看起来就像被淹没在 一堆正常样本中似的 我用绿色画出来的 这个异常样本 它的概率值很大 是蓝色曲线的高度 而我们的算法 没能把这个样本判断为异常
现在如果说这代表 飞机引擎的制造或者别的什么 那么我会做的是 我会看看我的训练样本 然后看看到底是 哪一个具体的飞机引擎出错了 看看通过这个样本 能不能启发我 想出一个新的特征 x2 来帮助算法区别出 不好的样本 和我剩下的正确的样本 也就是那些红色的叉叉 或者说正常的飞机引擎样本。如果我这样做的话 我们的期望是 创建一个新的特征 x2 使得 当我重新画数据时 如果我用训练集中的 所有正常样本 我应该就会发现 所有的训练样本都是这里的红叉了 我们也希望能看到 对于异常样本 这个新特征变量 x2 的值会看起来是异常的 因此对于我这里的绿色的样本 这是异常的样本 对吧 我的 x1 值仍然是2.5 那么我的 x2 很有可能 是一个比较大的值 比如这里的3.5 或者一个非常小的值。现在如果我再来给数据建模 我会发现 我的异常检测算法 会在中间区域 给出一个较高的概率 然后越到外层越小 到了那个绿色的样本 我的异常检测算法 会给出非常小的概率值 所以这个过程 实际上就是,看看哪里出了错 看看那些 算法没能正确标记的异常点 看看你能不能得到启发来创造新的特征变量 所以也就是说 找一找飞机引擎中的不寻常的问题 然后来建立一些新特征变量 有了这些新的特征变量 应该就能更容易 从正常样本中区别出异常来 这就是误差分析的过程

计算机在执行一个任务时 进入了一个死循环 因此被卡住了 意思就是说 假如我感觉 我的其中一台机器 或者说其中一台服务器的代码 执行到一个死循环卡住了 因此CPU负载升高 但网络流量没有升高
因为只是CPU执行了 较多的工作 所以负载较大 卡在了死循环里 在这种情况下 要检测出异常 我可以新建一个特征 x5
通过这样的方法 ,建立新的特征变量你就可以通过不同特征变量的组合,捕捉到对应的不寻常现象
