灵活,方便的网页解析库,处理高效
安装:
pip install beautifulsoup4
用法:

所谓python标准库,即不需要安装额外插件即可使用
基本使用

标签选择器

这种选择方式,它只返回第一个匹配到的内容


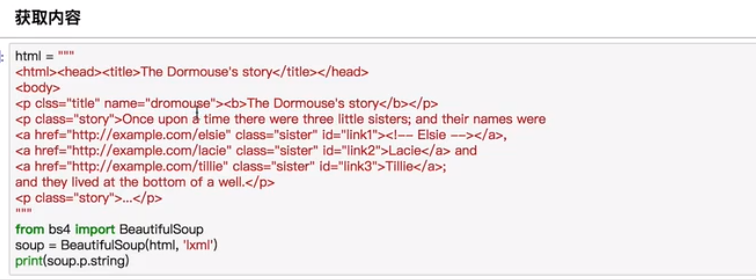



children方法返回一个迭代器,需用for循环来来获取元素,内容同content一样
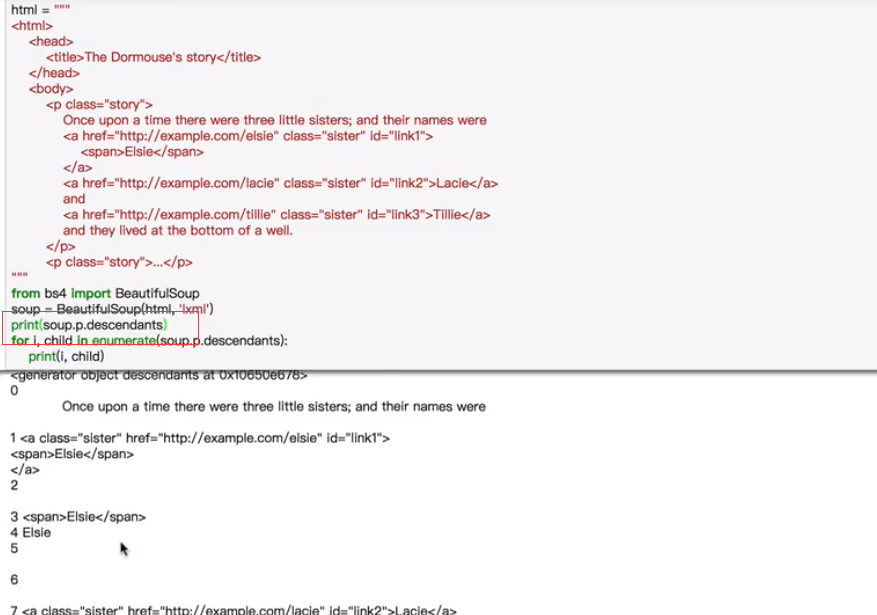
descendants返回一个迭代器,内容为所有子节点包括孙子节点一并获取,子节点同孙子节点是并列的。
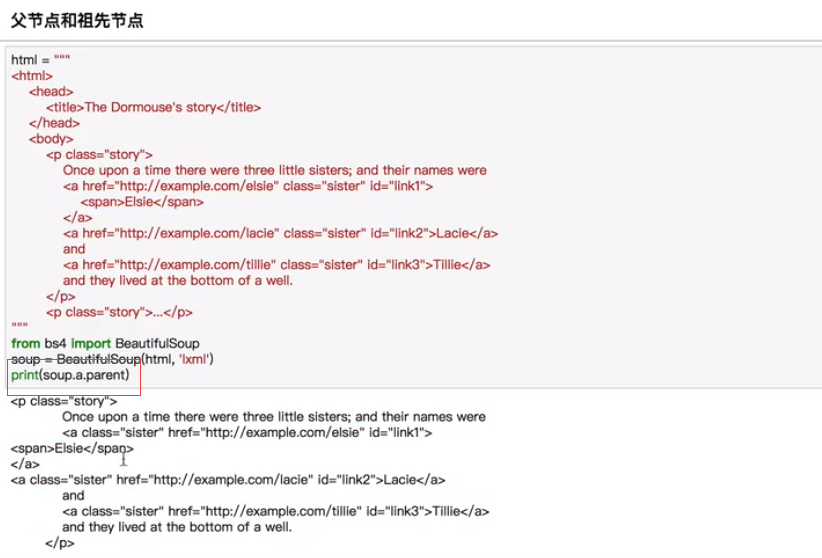


标准选择器
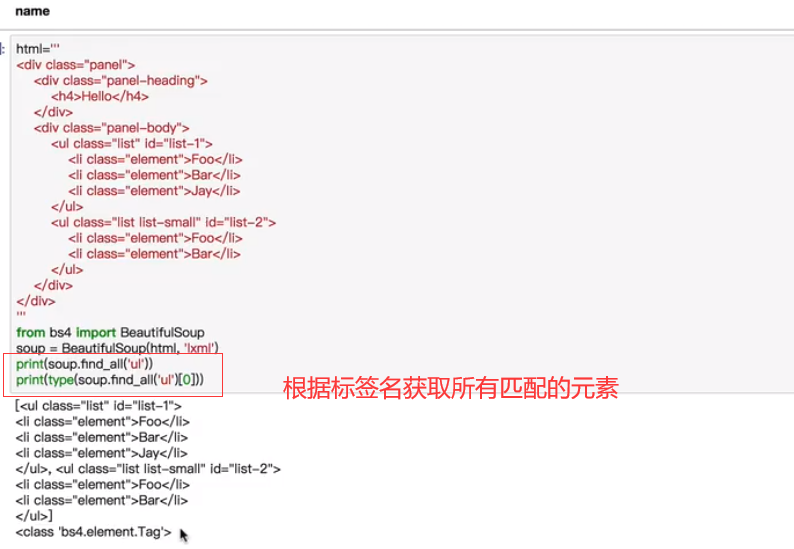
find_all(name,attrs,recursive,text,kwargs)**
可根据标签名,属性,内容查找文档,以列表的形式返回所有的匹配项
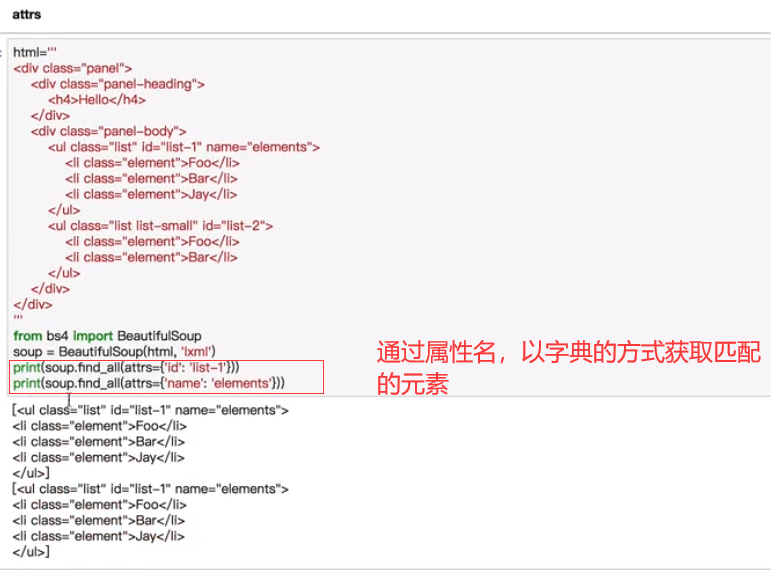


find(name,attrs,recursive,text,kwargs)**
返回第一个匹配到的元素

CSS选择器
通过select()直接传入CSS选择器即可完成选择

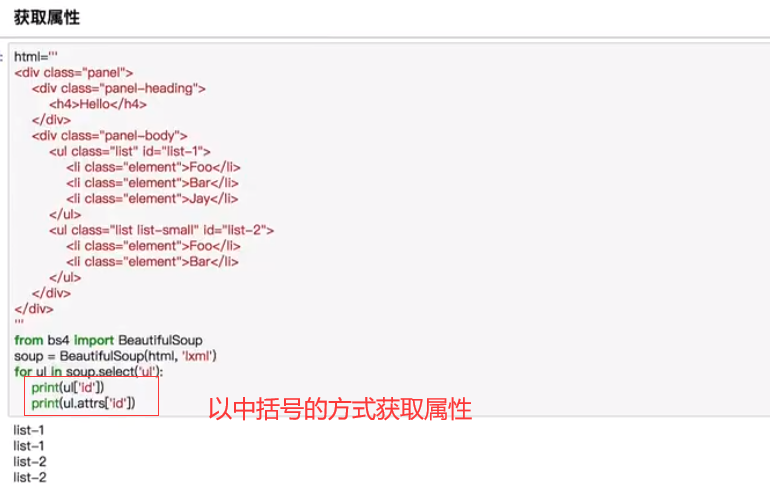
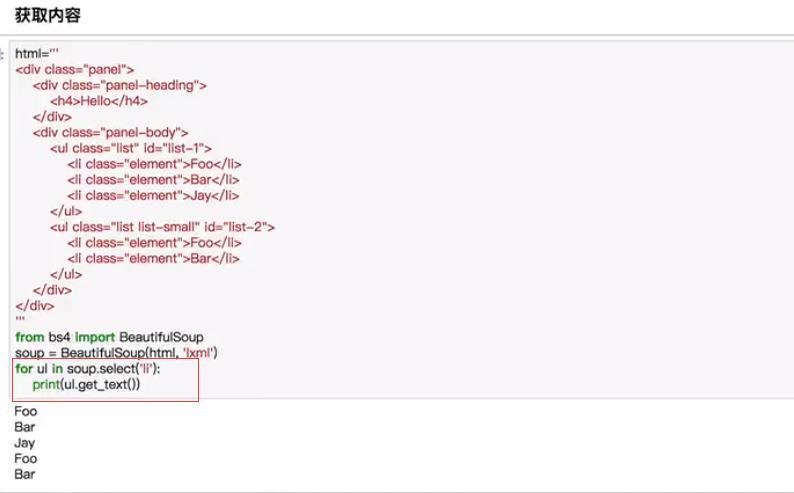
总结:一共三种选择器:标签选择器,标准选择器,CSS选择器。
- 推荐使用lxml解析库,必要时使用html.parser
- 标签选择器筛选功能弱但速度快
- 建议使用find(),find_all()查询匹配单个结果或多个结果
- 如对CSS选择器熟悉建议使用select()