数据的重塑简单点说,就是为了数据展示更加的直观
首先从一张图开始,也是大家常用的图:
import numpy as np
from pandas import DataFrame
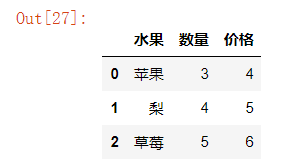
df = DataFrame({'水果':['苹果','梨','草莓'],
'数量':[3,4,5],
'价格':[4,5,6]})
df
out:
先看看代码中使用完的效果,然后再来进行小结
df.stack()

初步发现:stack的作用是,提取表格中的行出来作为一级行,把列标提取出来作为二级的行,剩下的就是按照一级行分类后,二级行标对应的数据:
验证发现:
import pandas as pd
from pandas import DataFrame
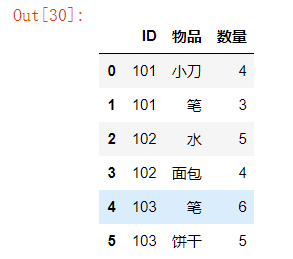
df = DataFrame({'ID':['101','101','102','102','103','103'],
'物品':['小刀','笔','水','面包','笔','饼干'],
'数量':[4,3,5,4,6,5]})
df
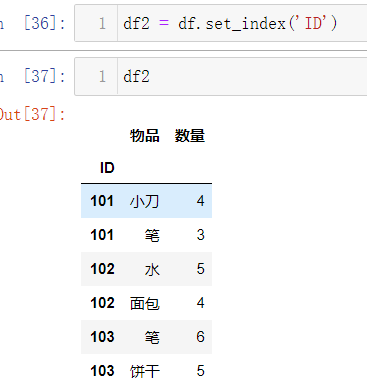
为了方便处理数据,首先我们要把pandas默认生成的index去掉,选择ID为新的index
df2 = df.setindex('ID')
然后再进行stack处理
df2.stack()

是的,结果我们发现,数据比整理前更加的混乱了,不过stack跟我们之前的理解确实差不多的,于是我们就要继续想了,应该把物品对应的名称作为行的二级分类标题才对;
于是我们可以这么做,在set_index的时候,我选择两列结果会怎么样呢?
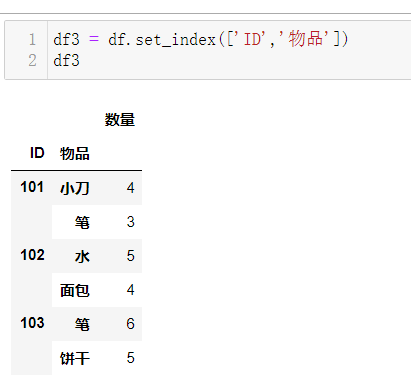
结果,好像已经满足我们的直观需求了,这个时候,发现都不必用stack函数来进行继续处理了.那我们来进行unstack处理下,看是什么样的结果:
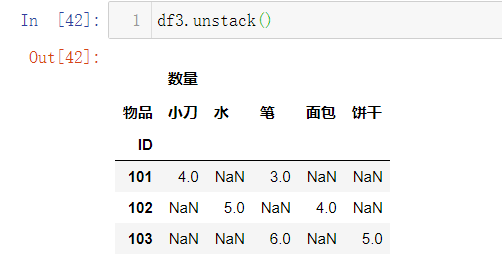
于是我又发现了,当我们使用了unstack参数后,就把原来表格的第一行自动转为了新的表的行,第二行就被转换成了列标,此时如果不是有数量这个看上去很"另类"的标值在,
数据好像确实更直观了一些,那么有没有更好的办法呢?难道是set_index的时候要选择3列
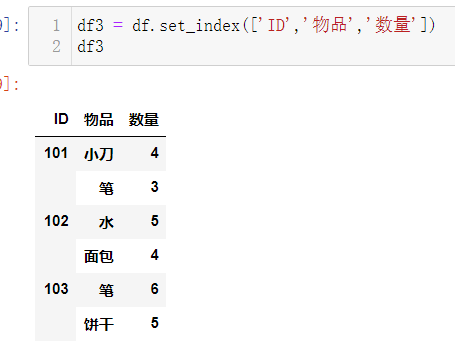
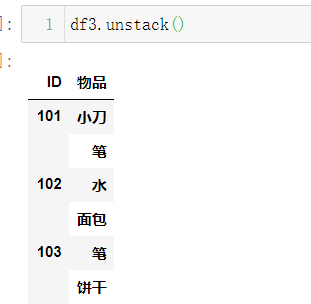
这么折腾一阵后,发现,结果比之前的更惨了,哎哟,这啥回事嘛?我到现在为止,用stack和unstack的方式确实没有发现更好的处理方式,如果有大神可以用这种方式做得更好的,欢迎指点;
其实也没那么纠结,我们主要以处理问题为准,其他的不深究,于是就来了pivot的概念了,首先来展示一下,对上面一题,
df.pivot('ID','物品','数量') #pivot(index=None, columns=None, values=None)
out:
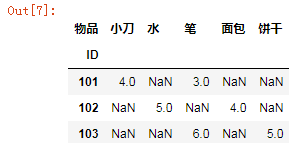
一看就明白,pivot使用起来就非常的清晰了,带三个参数,第一个是index,第二个是columns,第三个是数值型的。
做统计的是,直接把数值型的列表给去除了,直接显示对应的数量;