上面那篇文章中,初步介绍了一个文本文件的读取;接下来介绍另外一种常见的本地数据格式,那就是Excel电子表格,如果读者在学习或者工作中需要使用Python分析某个Excel表格数据,改如何完成第一个的数据读取呢?
1.Pandas模块中的read_excel
方法原型:
pd.read_excel(io,sheetname=0,header=0,skiprows=None,skipfooter=None,index_col=None,names=None,parse_cols=None,parse_date=False,
na_values=None,thousands=None,convert_float=True)
io:指定电子表格的具体路径
sheetname:指定需要读取电子表格中的第几个sheet,既可以传递整数也可以传递具体的Sheet名称
header:是否需要将数据集的第一行用作表头,默认为是需要的
skiprows:读取数据时,指定跳过的开始行数
skipfooter:读取数据时,指定跳过的末尾行数
index_col:指定哪些列用作数据框的行索引(标签)
names:如果原数据集中没有字段,可以通过该参数在数据读取时给数据框添加具体的表头 #如: ['Prod_Id','Prod_Name','Prod_Color','Prod_Price'] 通过列表的 形式
parse_cols:指定需要解析的字段
parse_dates:如果参数值为True,则尝试解析数据框的行索引;如果参数为列表,则尝试解析对应的日期列;如果参数为嵌套列表,则将某些列合并为日期列;
如果参数为字典,则解析对应的列(字典中的值),并生成新的字段名(字典中的键)
na_values:指定原始数据中哪些特殊值代表了缺失值
thousands:指定原始数据集中的千分位符 #同上篇
convert_float:默认将所有的数值型字段转换为浮点型字段
converters:通过字典的形式,指定某些列需要转换的形式 #用法:converters = {0:str} 第0列转换为字符型
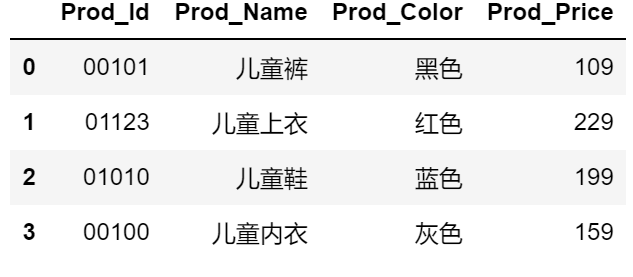
例题:如有以下Excel表格以及数据
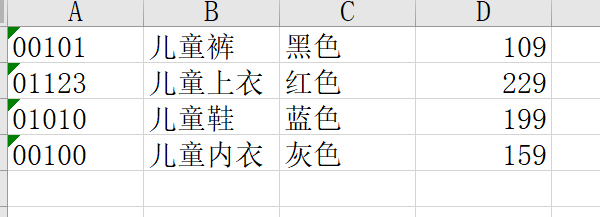
观察数据信息,发现以下几点需要注意到的
该数据集反映的是儿童类服装的产品信息。在读取数据是需要注意两点:
1.该表没有表头,如何读取数据的同时就设置好具体的表头;
2.数据集的第一列实际上是字符型的字段,如何避免数据读入时自动变成数值型字段
import pandas as pd
child_cloth = pd.read_excel(io = r'D:data_test02.xlsx', header = None,
names = ['Prod_Id','Prod_Name','Prod_Color','Prod_Price'], converters = {0:str})
child_cloth
out: