上面一篇文章有记录pandas构造数据框的方式有二维数组,字典,嵌套的列表和元组等,本篇用于介绍通过外部数据读取的方式来构造数据框。
python读取外部数据集的时候,这些数据集可能包含在文本文件(csv,txt),电子表格Excel和数据库中(Mysql,SQL server)等,那么如何来用pandas来实现这些
文件,表格和数据库的读取呢?
1.文本文件的读取
read_table函数介绍
函数原型:
pd.read_table(filepath_or_buffer,sep='t',header='infer',names=None,index_col=None,usecols=None,dtype=None,converters=None,skiprows=None,
skipfooter=None,nrows=None,na_values=None,skip_blank_lines=True,parse_dates=False,thousands=None,comment=None,encoding=None)
各参数的含义:
file_path_or_buffer:指定txt或csv文件所在的具体路径
sep:指定数据集中各字段之间的分隔符,默认为Tab制表符
header:是否需要将原数据集中的第一行作为表头,默认将第一行用作字段名称
names:如果原数据集中没有字段,可以通过该参数在数据读取时给数据框添加具体的表头
index_col:指定原数据集中的某些列作为数据框的行索引(标签)
usecols:指定需要读取原数据集中的哪些变量名;
dtype:读取数据时,可以为原数据的每个字段设置不同的数据类型
converters:通过字典格式,为数据集中的某些字段设置转换函数
skiprows:数据读取时,指定需要跳过原数据集开头的行数
skipfooter:数据读取时,指定需要跳过原数据集末尾的行数
nrows:指定读取的数据的行数
na_values:指定原数据集中哪些特征的值作为缺失值
skip_blank_lines:读取数据时是否需要跳过原数据集中的空白行,默认为True
parse_dates:如果参数值为True,则尝试解析数据框的行索引;如果参数为列表,则尝试解析对应的日期列;如果参数为嵌套列表,则将某些列合并为日期列;
如果参数为字典,则解析对应的列(字典中的值),并生成新的字段名(字典中的键)。
thousands:指定原始数据集中的千分位符
comment:指定注释符,在读取数据时,如果碰到行首指定的注释符,则跳过改行
encoding:如果文件中含有中文,有时需要指定字符编码。
涉及的参数比较多,用的时候有些参数是用不上的,根据需要设置,如下示例:
有txt文件,内容如下:
'''
数据来源:某公司人事记录表
时间范围:2019.1.1~2019.10.31
year,month,day,gender,occupation,income
1990,3,7,男,销售经理,6&000
1989,8,10,女,化妆师,8$500
# 1991,10,10,男,后端开发,13&500
1992,10,7,女,前端设计,6&500
1985,6,15,男,数据分析师,18&000
该数据集仅用于参考!
不可以用于他用!
备注于2019年11月。
'''
处理数据之前,先观察数据有以下特点,思考如何解决:
1.数据集并不是从第一行开始的,前面几行实际上是数据集的来源说明,读取数据时需要注意什么问题。
2.数据的末尾3行仍然不是需要读入的数据,如何避免后3行数据的读入。
3.中间部分的数据,第四行前加了#号,表示不需要读取改行数据,改如何处理
4.数据集中的收入一行,千分位符是&,如何将该字段读入为正常的数值型数据
5.如果需要将year,month和day三个字段解析为新的birthday字段,该如何做到。
6.数据集中含有中文,一般在读取含中文的文本文件是都会出现编码错误,该如何解决。
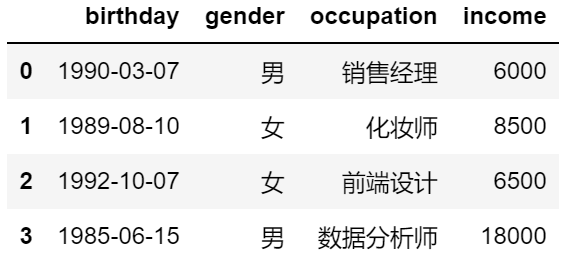
import pandas as pd
test_Data = pd.read_table(r'D:data_test01.txt',sep=',',header='infer',
skiprows=2,skipfooter=3,parse_dates={'birthday':[0,1,2]},
comment='#',encoding='utf-8',thousands='&',engine='python')
test_Data
out:
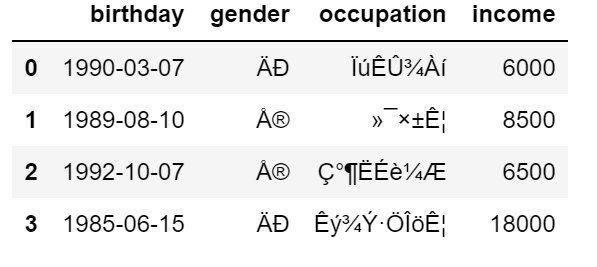
这里补充说明一下utf-8编码的问题:encoding应该是用utf-8的,没有错误;但是我开始的时候怎么搞都是说utf-8的编码问题,我查阅了很多方法都不行;后面参考了一些人的经验改成,
encoding = 'ISO-8859-1',于是显示成了如下乱码的样子,至少没有报错了。花了我不少时间去研究都没有找到处理方式(文件内容我也改成UTF-8的编码了);
然后参考了一本相关的书,提示到,我们处理txt文件的时候,只在txt里面更改编码方式加上设置encoding=utf-8 是没有效果的,要把文件另存为,UTF-8编码格式的,然后替换原文件,如下:

然后再次运行,就得出了正常的结果;也算是一个处理中文编码问题的经验吧。