一、变量
1、尽可能使用局部变量
调用方法时传递的参数以及在调用中创建的临时变量都保存在栈中速度较快,其他变量,如
静态变量、实例变量等,都在堆中创建,速度较慢。另外,栈中创建的变量,随
着方法的运行结束,这些内容就没了,不需要额外的垃圾回收。
2、尽量减少对变量的重复计算
明确一个概念,对方法的调用,即使方法中只有一句语句,也是有消耗的。所以例如下面的操作:
for (int i = 0; i < list.size(); i++) {...}
应替换为
int length = list.size();
for (int i = 0, i < length; i++) {...}
这样,在list.size()很大的时候,就减少了很多的消耗。
3、尽量采用懒加载的策略,即在需要的时候才创建
String str = "aaa"; if (i == 1){ list.add(str); } //建议替换成 if (i == 1){ String str = "aaa"; list.add(str); }
4、异常不应该用来控制程序流程
异常对性能不利。抛出异常首先要创建一个新的对象,Throwable接口的构造函数调用
名为fillInStackTrace()的本地同步方 法,fillInStackTrace()方法检查堆栈,收集调用跟踪
信息。只要有异常被抛出,Java虚拟机就必须调整调用堆栈,因为在处理过程中创建 了一
个新的对象。异常只能用于错误处理,不应该用来控制程序流程。
5、不要将数组声明为public static final
因为这毫无意义,这样只是定义了引用为static final,数组的内容还是可以随意改变的,
将数组声明为public更是一个安全漏洞,这意味着这个数组可以被外部类所改变。
6、不要创建一些不使用的对象,不要导入一些不使用的类
这毫无意义,如果代码中出现"The value of the local variable i is not used"、
"Theimport java.util is never used",那么请删除这些无用的内容
7、程序运行过程中避免使用反射
反射是Java提供给用户一个很强大的功能,功能强大往往意味着效率不高。不建议在程序
运行过程中使用尤其是频繁使用反射机制,特别是 Method的invoke方法。如果确实有必要,一
种建议性的做法是将那些需要通过反射加载的类在项目启动的时候通过反射实例化出一个对象并放入内存。
8、使用数据库连接池和线程池
这两个池都是用于重用对象的,前者可以避免频繁地打开和关闭连接,后者可以避免频
繁地创建和销毁线程。
9、容器初始化时尽可能指定长度
容器初始化时尽可能指定长度,如:new ArrayList<>(10); new HashMap<>(32); 避免容
器长度不足时,扩容带来的性能损耗。
10、ArrayList随机遍历快,LinkedList添加删除快
二、拦截器案例
需求:
实现一个简单的双interceptor组成的拦截链。第一个interceptor会在消息发送前将时间戳信息加到消息value的最前部;第二个interceptor会在消息发送后更新成功发送消息或失败发送消息数;
1、创建第一个interceptor
import org.apache.kafka.clients.producer.ProducerInterceptor; import org.apache.kafka.clients.producer.ProducerRecord; import org.apache.kafka.clients.producer.RecordMetadata; import java.util.Map; public class TimeInterceptor implements ProducerInterceptor<String,String> { @Override public ProducerRecord<String, String> onSend(ProducerRecord<String, String> producerRecord) { //取出数据value String value = producerRecord.value(); //创建新的producer对象,并返回 return new ProducerRecord<String,String>(producerRecord.topic(),producerRecord.partition(), producerRecord.key(),System.currentTimeMillis()+","+value); } @Override public void onAcknowledgement(RecordMetadata recordMetadata, Exception e) { } @Override public void close() { } @Override public void configure(Map<String, ?> map) { } }
2、创建第二个interceptor
import org.apache.kafka.clients.producer.ProducerInterceptor; import org.apache.kafka.clients.producer.ProducerRecord; import org.apache.kafka.clients.producer.RecordMetadata; import java.util.Map; public class CountInterceptor implements ProducerInterceptor<String,String> { int success; int error; @Override public ProducerRecord<String, String> onSend(ProducerRecord<String, String> producerRecord) { return producerRecord; } @Override public void onAcknowledgement(RecordMetadata recordMetadata, Exception e) { if (recordMetadata!=null){ success++; }else{ error++; } } @Override public void close() { System.out.println("success:"+success); System.out.println("error:"+error); } @Override public void configure(Map<String, ?> map) { } }
3、创建生产者(添加两个拦截器)
import org.apache.kafka.clients.producer.KafkaProducer; import org.apache.kafka.clients.producer.ProducerConfig; import org.apache.kafka.clients.producer.ProducerRecord; import java.util.ArrayList; import java.util.Properties; public class InterceptorProducer { public static void main(String[] args){ //创建kafka生产者的配置信息 Properties properties = new Properties(); //kafka集群 ProducerConfig properties.put("bootstrap.servers","192.168.138.55:9092,192.168.138.66:9092,192.168.138.77:9092"); //ack应答级别 properties.put("acks","all"); //重试次数 properties.put("retries",3); //批次大小 16K properties.put("batch.size",16384); //等待时间 properties.put("linger.ms",1); //RecordAccumulator缓冲区大小 32M properties.put("buffer.memory",33554432); //key,value序列化类 properties.put("key.serializer","org.apache.kafka.common.serialization.StringSerializer"); properties.put("value.serializer","org.apache.kafka.common.serialization.StringSerializer"); //添加拦截器 ArrayList<Object> interceptors = new ArrayList<>(); interceptors.add("com.wn.interceptor.TimeInterceptor"); interceptors.add("com.wn.interceptor.CountInterceptor"); properties.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG,interceptors); //创建生产者对象 KafkaProducer<String,String> producer = new KafkaProducer<>(properties); //发送数据 for (int i=0;i<5;i++){ producer.send(new ProducerRecord<String, String>("aaa","aaabbb--"+i)); } //关闭资源 producer.close(); } }
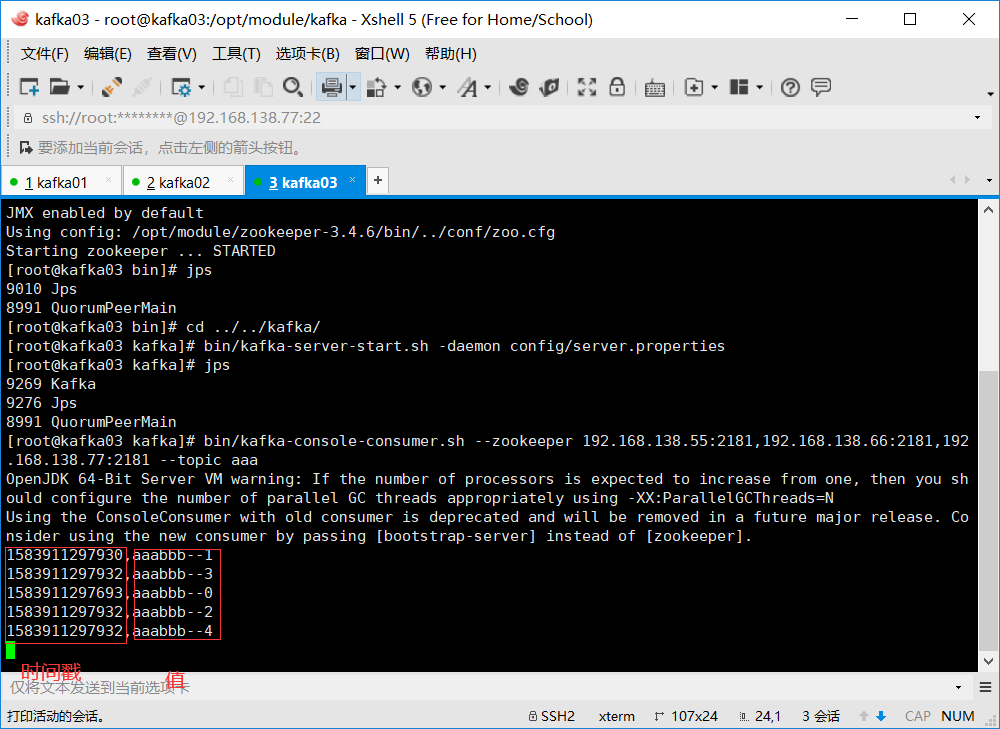
4、开启zookeeper+kafka
5、 创建消费者
bin/kafka-console-consumer.sh --zookeeper 192.168.138.55:2181,192.168.138.66:2181,192.168.138.77:2181 --topic aaa
6、启动生产者,查看效果