核心:不安全指针和反射
概述
这篇文章也是长篇,为了把问题记录清楚,还是按照一直坚持的写作习惯,从零开始
在C语言中,对指针进行操作是非常正常的一件事,由于指针包裹的是内存地址,因此对于指针来说,也只有加减法具有意义
下面先看个C的代码:
int main(int argc, char* argv[]) { char *msg="hello c++"; msg++; printf("%c ",*msg); //'e' }
【分析】
”hello c++”字符串在编译之后分配成一个常量形式,也就是一个字面量常量值。msg赋值为该字符串的首地址,假如为0x1000。接着将msg自增,则msg=0x1001,然后打印该地址起始1字节的字符’e’
写这个例子主要对照说明在C中指针进行加减运算是非常平常的。但在go中不行
代码如下:
func main() { s:="hello golang" p:=&s p++ //错误,p非数值类型 }
【分析】
p为字符串s的地址,然后企图执行p++结果编译都通不过,go做不到或者说语言禁止这么做。错误显示,++必须搭配数值类型,但从代码中可以看到p的类型是*string 指针类型,明确说明不允许指针参与加减运算。
unsafe.Pointer
怎么解决这个问题呢?系统unsafe包提供一个类型Pointer,可以看到它的定义是:
type Pointer *ArbitraryType
单词Arbitrary是”任意的”的意思,再看下ArbitraryType的定义:
type ArbitraryType int
到这里基本看出来了,unsafe.Pointer实际是一个*int的包装。在go的学习中知道,int是和平台位数关联的,当前系统一般都是64位,因此int在运行时等价于int64,可以表示任意类型的地址,也即不管类型是什么,地址是相同的8个字节存储
看下这个变化:
原来是具体类型T的地址,经过unsafe.Pointer包装(或者说强转)变成unsafe.Pointer类型,就好比同一个人改头换面变成另一个身份,但本质的值并没变
接着读下系统包的文档,摘取一段:
// Pointer represents a pointer to an arbitrary type. There are four special operations
// available for type Pointer that are not available for other types:
// - A pointer value of any type can be converted to a Pointer.
// - A Pointer can be converted to a pointer value of any type.
// - A uintptr can be converted to a Pointer.
// - A Pointer can be converted to a uintptr.
// Pointer therefore allows a program to defeat the type system and read and write
// arbitrary memory. It should be used with extreme care.
【翻译下】
Pointer可以表示任意类型的指针,对于type Pointer有四个特别的操作:
- 任意类型地址能被转化为unsafe.Pointer
- unsafe.Pointer能被转化为任意类型的地址
- uintptr能被转化为Pointer
- Pointer能被转化为uintptr
因此Pointer允许程序破坏类型系统执行读写任意内存的操作,使用时务必小心....云云
下面是实验代码:
func main() { s := "hello golang" unsafe_ptr := unsafe.Pointer(&s) //类型指针 -> unsafe.Pointer pstr := (*string)(unsafe_ptr) // unsafe.Pointer -> 类型指针 fmt.Println(*pstr) //打印字符串 }
代码证实了这一点
关联图如下:
下面分述各个转化的作用
unsafe.Pointer -> 类型pointer
前面分析了几个转化,先分析从unsafe.Pointer强转到类型pointer有啥用处?
下面举个例子说明:
根据一些资料知道,在golang中的一些数据类型并非像C语言那样简单。比如string类型,它本身是由有两个字段16字节组成,前8个字节表示底层的字符串地址,后8字节表示字符串长度

和C比较,发现golang的字符串形式完全不同。C只是简单的以’�’做为结束标志,而golang是固定形式。
在这个地方就出现一个问题,怎么用代码验证golang的字符串是这种结构呢?
代码:
func main() { var a string = "hello" var ptr_header = (*reflect.StringHeader)(unsafe.Pointer(&a)) fmt.Printf("%x ", ptr_header.Data) //146c558 fmt.Printf("%d ", ptr_header.Len) //5 }
【分析】
借用了反射包中的reflect.StringHeader结构体,这个结构体实际就是字符串的结构描述。在这里为了方便直接拿过来用,自定义同样可以。进入文档查看一下内部结构:
type StringHeader struct { Data uintptr Len int }
struct说明了字符串的结构,Data表示字符串真正的首地址,Len表示字符串长度,打印结果证明了这一点。而在技巧上就使用了unsafe.Pointer -> 类型的转换。也许会认为,直接用下面的代码强转不行吗?
var header = (*reflect.StringHeader)(&a)
//Cannot convert expression of type '*string' to type '*StringHeader'
错误:不能将*string类型强转为*StringHeader!
这个地方体现了unsafe.Pointer的作用,因为根据文档,它可以被转化为任意类型的指针属于万能类型
问题似乎解决了,但是出现了第二个问题,即使得到字符串的首地址,但是我想看看Data地址处是不是真的是”hello”,很可惜,上面这个代码解决不了这个问题,于是又出现了uintptr
uintptr
uintptr的本质是integer类型,可以足够容纳任意类型的地址。虽然它和地址有关系,但是语义是完全不同的。
原因在于,整型和指针是完全不同的语义,就像前面提到的,指针是不能加减的(语言禁止这么操作),但是整型是可以正常加减。所以在执行打印header.Data时,把它解释成整数。
到这里就出现绕的问题,想通过地址打印数据,地址又不能直接到达(地址在结构体中)。等得到地址时却是整型,而又不能用整型解释内存地址。
下面做个总结:
- uintptr可以加减移动,不能解释内存
- unsafe.pointer不能加减移动,不能解释内存,但是可以作为桥梁在uintptr和类型地址之间转换
- 类型地址不能加减移动,但是可以真正的解释内存
可以看出,unsafe.Pointer做为桥梁起到中转作用,但是这个指针不能解释内存,有点类似于C中的void*,万能、抽象又空泛
修改后的代码如下:
func mem(ptr uintptr, len int) { //打印内存 for i := 0; i < len; i++ { pointer := unsafe.Pointer(ptr + uintptr(i)) fmt.Printf("%c", *(*byte)(pointer)) } } func main() { var a string = "hello" var header = (*reflect.StringHeader)(unsafe.Pointer(&a)) mem(header.Data, header.Len) }
【分析】
这个代码就是三者之间互相转换的技巧,mem()方法中最终转换得到一个具体类型的地址,通过这个地址解释内存。
代码的作用
经过一系列的转换并打印内存,作用在于:只要知道一个类型的结构描述,就可以遍历它的底层内存值,这对于了解底层有用处。按着这个思路可以解释数组、切片、结构体等各种类型的底层
举例说明,如何知道字符串底层是utf8编码呢?通过上述代码可以立刻得证.
不安全指针的基本原理就写到这,后面可以举一反三做更深入的研究,除此外,unsafe包还有几个方法,平常基本没有用到就暂时略过。
unsafe.Pointer在反射中的应用
做了四页的铺垫,通过对不安全指针的了解,下面开始记录反射
前面的分析也涉及到反射使用不安全指针进行操作,下面看下具体:

这里把ty的类型也带上为了看的更清楚,reflect.Type是一个只有方法的interface{}类型。
断点进入reflect.TypeOf(t);
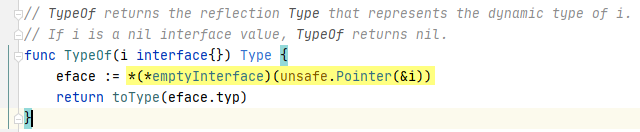
不管什么值进入TypeOf之后,都被转化为interface。interface是一个万能类型,它具有包裹值的所有信息。正是依赖于这个转化,反射才能得到众多信息。
进入方法内部,首先使用unsafe.Pointer对接口值取地址,然后再使用一个具体类型emptyInterface强转,这些技巧在前面已经分析清楚
接口可以容纳其它任意类型值,但是接口自己本身也有一个描述,就是emptyInterface类型。然后得到它的成员变量:typ *rtype,而rtype又实现了Type接口,所以ty最终是reflect.Type类型,可以调用Type的接口方法进行操作。这就是反射的准备工作。
在这个准备中,由于最初的值已经被转化成interface{},因此所有信息都收集完成,后面的接口方法调用,比如ty.Kind(),就是对已有的信息进行判断和操作,所以这一块就不再记录。
类型的扩展
首先对上面的内容做个示意图:
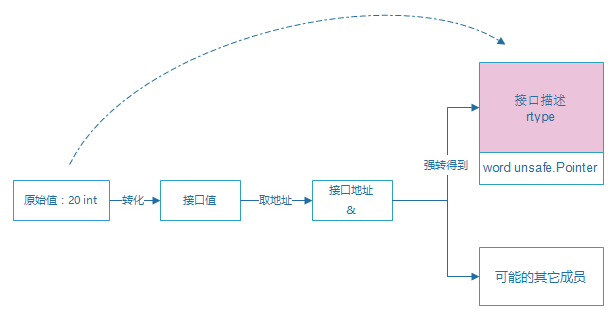
图示说明前面一系列的操作过程,最终结果是:由原始值int 20得到一个接口描述rtype。
在记录string的时候知道,得到一个值的地址只是得到一个类型描述结构的起始处,比对来看
重点在于红块的rtype部分。但是这个rtype的结构是浮动的。浮动的意思是指,原始值不同,这个rtype也不同,比如int和struct类型得到的都不同,对于struct来说除了有rtype这一段,还有其它的信息,比如字段信息。
源码如下:
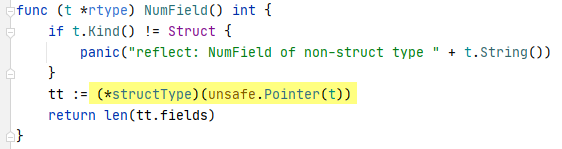
这段源码清楚的表明,rtype再一次被强转成了structType类型,再查看其源码:

发现structType除了有rtype之外,还有pkgPath,fields字段,说明结构类型扩展了,原因是struct需要记录的信息更多
从这几个源码最终看到,为什么反射能得到那么多信息,就是因为在不同类型 -> interface{}这一步得到的信息是不同的,有的多有的少,在调用Type的相关方法时,先查查类型,如果匹配就进行该类型的特定强转。
下面看下强转的思路,图示如下:
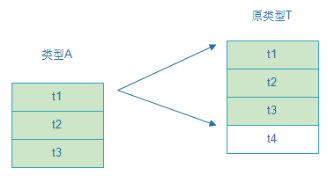
如图,假如类型T有四个成员,类型A具备其中三个,那么就可以把T强转成类型A,也就是说强转的类型一定是原类型的子集,而且对应的成员类型和顺序完全相同。代码面前无秘密:
type T struct { t1 int t2 int t3 string } type A struct { a1 int a2 int } func main() { var t = T{ 1, 2, "t", } var a = (*A)(&t) //不能从*T转化为*A }
【分析】
A想把T中自己能对应的成员搬出来,代码使用(*A)强转,但是根本不通。这里就是unsafe.Pointer施展本领的地方
同理,可以将T类比于反射之后的rtype,不管哪种类型一番转换之后的rtype都是rtype的子集。因此前面的structType才能强转。
这个问题同时给出一个非常好的启示:如何从类型T中按类型S截取数据?上述代码给了答案
反射的原理基本就这些,剩下的工作就是按部就班的调试各个方法,不再记录
本篇结束
package main import ( "fmt" "unsafe" ) //基础类型 type _rtype struct { a1 int a2 int } //struct : 扩展类型 type _structType struct { _rtype pkgpath string } type iface struct { rt *_rtype p unsafe.Pointer } func main() { var t = iface{ rt: &_rtype{ 20, 30, }, p: nil, } var s = (*_structType)(unsafe.Pointer(t.rt)) fmt.Println(s.a1) }