如何在 centos 7.3 上安装 caffe 深度学习工具
有好多朋友在安装 caffe 时遇到不少问题。(看文章的朋友希望关心一下我的创业项目趣智思成) 今天测试并整理一下安装过程。我是在阿里云上测试,选择centos 7.3 镜像。
先安装 epel 源
|
1
|
yum install epel-release |
安装基本编译环境
|
1
2
|
yum install protobuf-devel leveldb-devel snappy-devel opencv-devel boost-devel hdf5-develyum install gflags-devel glog-devel lmdb-devel<br>yum install atlas-devel<br>#用默认的 atlas 有点问题,需要改为 openblas |
|
1
2
3
4
|
yum install openblas-devel<br>yum install python34-develyum install gityum groupinstall "Development Tools" "Development Libraries" |
下载源代码
|
1
|
git clone https://github.com/BVLC/caffe |
到源代码目录下执行
|
1
|
mv Makefile.config.example Makefile.config |
修改配置文件 Makefile.config
所有不是#开头的都需要修改
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
# CPU-only switch (uncomment to build without GPU support).CPU_ONLY := 1# BLAS choice:# atlas for ATLAS (default)# mkl for MKL# open for OpenBlasBLAS := open # Custom (MKL/ATLAS/OpenBLAS) include and lib directories.# Leave commented to accept the defaults for your choice of BLAS# (which should work)!# BLAS_INCLUDE := /path/to/your/blas#BLAS_LIB := /path/to/your/blasBLAS_INCLUDE := /usr/include/openblasBLAS_LIB := /usr/lib64 |
最后在 caffe 目录下运行:build。就完成了。有任何问题欢迎发在评论区。
caffe学习(1):多平台下安装配置caffe
提到deep learning, caffe的大名自然是如雷贯耳,当然,除了caffe之外,还有很多其他的框架,如torch,mxnet...但是,就我自己这一个月的实验以及师兄的结论都是,caffe得出的实验performance要高于别的框架,可能是C++的威力吧~笑
OK,接下来准备在这个系列分享我使用和学习caffe的一些经验,首先自然是框架的配置了。这里我们分享一下在windows10和ubuntu14.04虚拟机下的Caffe配置(:
一.Windows10 CUDA7.5 VS2013环境
1.软件准备
1.我使用的是系统是win10,首先要确保下载安装好visual stdio 2013,community版本下载链接在这,2014-Nov 12 Release Notes,这里建议大家最好将VS安装在默认C盘位置,不然之后编译可能会出现各种莫名其妙的问题
2.GitHub - BVLC/caffe at windows 这是微软修改的caffe windows版本,集成了caffe编译需要的第三方库,使用起来非常方便!下载好之后解压到任意位置,我这里是放在D盘下,接下来,到windows目录下,copy一份CommonSettings.props.example到CommonSettings.props
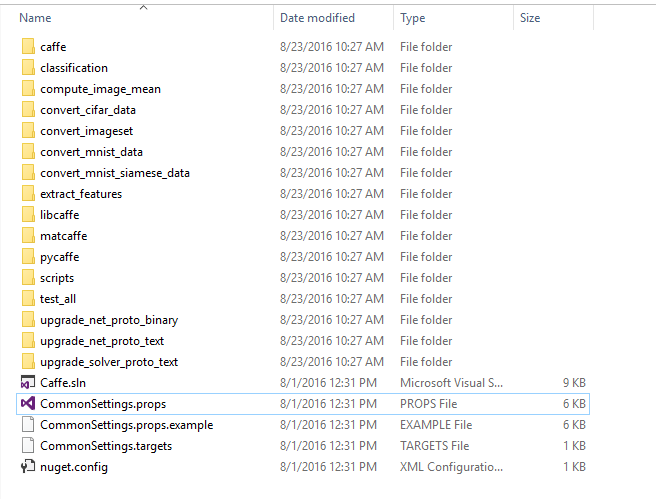 然后用vs打开CommonSettings.props,
然后用vs打开CommonSettings.props,
 我这里是默认使用GPU,CUDA版本为7.5,支持python的配置,大家可以根据自己需要进行调整,GPU对应CUDA版本和CudaArchitecture大致如下图
我这里是默认使用GPU,CUDA版本为7.5,支持python的配置,大家可以根据自己需要进行调整,GPU对应CUDA版本和CudaArchitecture大致如下图
 注意如果需要使用python接口的话,推荐安装Miniconda 2.7 64-bit Windows installer(from Miniconda website)或者是Anaconda 2.7 64-bit Windows installer(Download Anaconda Now!)
注意如果需要使用python接口的话,推荐安装Miniconda 2.7 64-bit Windows installer(from Miniconda website)或者是Anaconda 2.7 64-bit Windows installer(Download Anaconda Now!)
然后对应修改CommonSettings.props,我这里安装的是Anaconda2

3.接下来就是一些软件的安装了,首先下载CUDA,可以根据自己的GPU版本下载对应版本的CUDA,我这里下载的是CUDA7.5:https://developer.nvidia.com/cuda-downloads
下载完成之后就可以安装了,这里也是建议安装在默认位置,等待解压完成选择默认设置,等待安装完成即可.然后是CUDNN,https://developer.nvidia.com/cudnn ,貌似需要注册之后才能下载,应该不是很费事,下载cudnn v4 下载完成后,把解压后的文件夹中的bin,lib/x64,include中的内容分别放至 C:Program FilesNVIDIA GPU Computing ToolkitCUDAv7.5中的bin,lib/x64,include三个子目录下,这是%CUDA_PATH%路径,如果不太确定可以去系统环境变量下查看,最后就是Anaconda2了,下载完成之后打开cmd,输入以下命令安装一些python库
下载完成后,把解压后的文件夹中的bin,lib/x64,include中的内容分别放至 C:Program FilesNVIDIA GPU Computing ToolkitCUDAv7.5中的bin,lib/x64,include三个子目录下,这是%CUDA_PATH%路径,如果不太确定可以去系统环境变量下查看,最后就是Anaconda2了,下载完成之后打开cmd,输入以下命令安装一些python库
conda install --yes numpy scipy matplotlib scikit-image pip
pip install protobuf
至此,所有准备工作都已经完成了!
2.Caffe编译
打开D:caffe-windows下的caffe.sln,将编译选项切换成Release

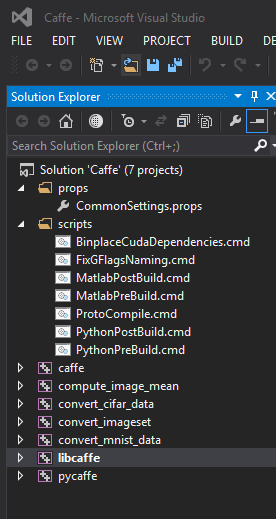 我这里删除了一些以后一般不会用到的工程,其实最主要的是caffe,libcaffe,pycaffe这三个,加快编译速度.然后我们先编译libcaffe,一般这个不出问题整个安装就没什么问题了。
我这里删除了一些以后一般不会用到的工程,其实最主要的是caffe,libcaffe,pycaffe这三个,加快编译速度.然后我们先编译libcaffe,一般这个不出问题整个安装就没什么问题了。
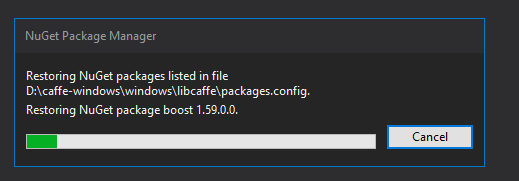 最开始VS可能会比较卡,这是在安装一些第三方库(opencv,boost之类的,microsoft用Nuget集成在了这一步),安装完成之后在D:NugetPackages下的这些都是caffe编译所需的第三方库
最开始VS可能会比较卡,这是在安装一些第三方库(opencv,boost之类的,microsoft用Nuget集成在了这一步),安装完成之后在D:NugetPackages下的这些都是caffe编译所需的第三方库
 然后默默等待编译完成即可,大约需要十分钟
然后默默等待编译完成即可,大约需要十分钟
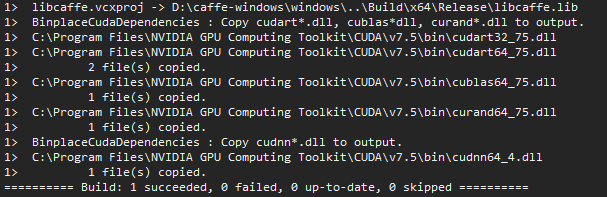 看到这里之后,这次安装基本上已经成功了.接下来编译剩下的即可
看到这里之后,这次安装基本上已经成功了.接下来编译剩下的即可
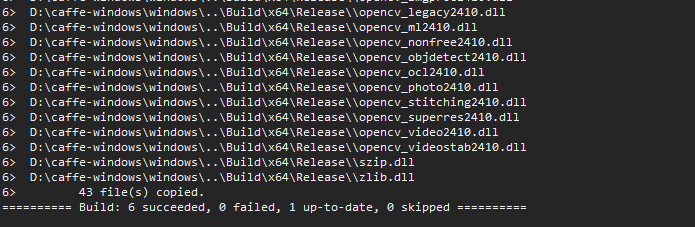 大功告成!
大功告成!
3.配置和使用
编译完成后,接下来做一些简单的配置:
1.首先,编译完成后的所有文件都在D:caffe-windowsBuildx64Release目录下,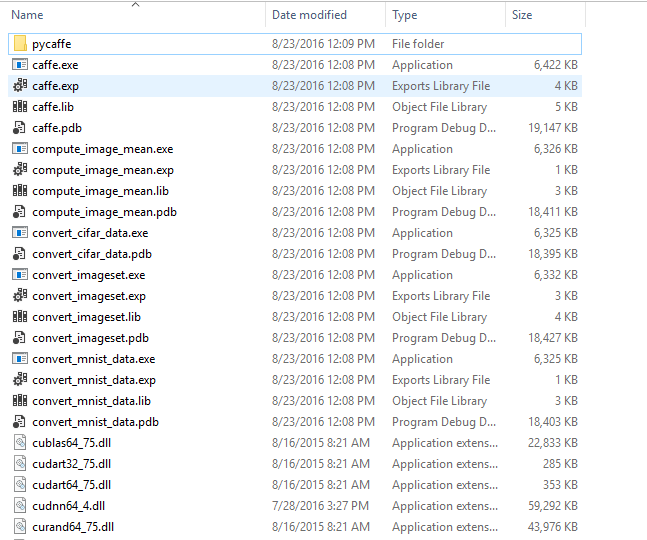
里面包含最重要的就是caffe.exe以及pycaffe,如果需要在别的机器上使用的话,只需要将Release文件夹拷贝过去即可,不需要再重新编译一遍
2.接下来我们做一些简单设置,首先打开环境变量设置,
 在user variables下新建PATH和PYTHONPATH,填写对应的文件路径,这样就可以便捷使用caffe和caffe python接口了,配置好之后我们打开cmd,先输入caffe,在python中import caffe,如果都不报错——证明你可以愉快的进入deep learning的殿堂了^_^
在user variables下新建PATH和PYTHONPATH,填写对应的文件路径,这样就可以便捷使用caffe和caffe python接口了,配置好之后我们打开cmd,先输入caffe,在python中import caffe,如果都不报错——证明你可以愉快的进入deep learning的殿堂了^_^
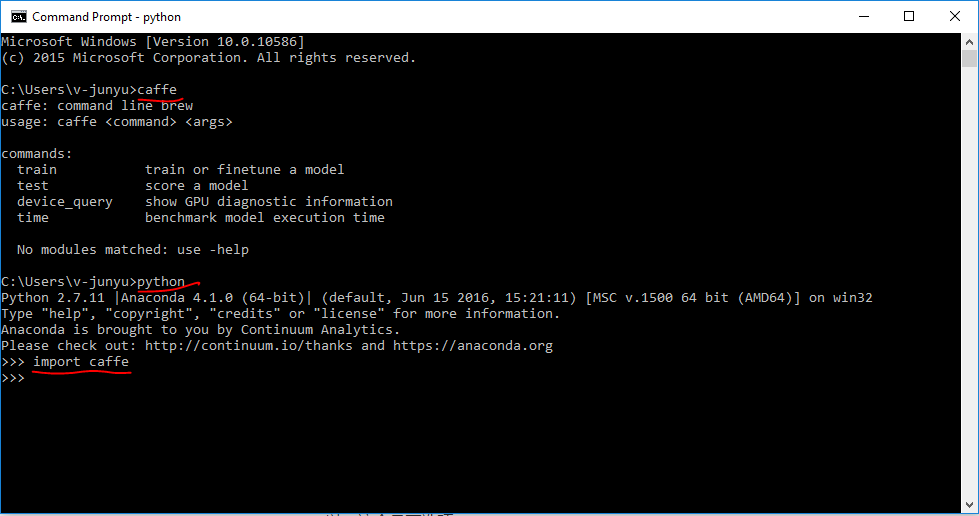
3.安装git for windows,对于习惯Linux系统的人使用这个会更加方便,当然你只用命令行也可以,这个是可选项
4.测试
下面我们在mnist数据集上做测试,MNIST handwritten digit database, Yann LeCun, Corinna Cortes and Chris Burge在这里下载这四个文件,解压到D:caffe-windowsdatamnist中 右键打开git bash here,输入:
右键打开git bash here,输入:
../../Build/x64/Release/convert_mnist_data train-images.idx3-ubyte train-labels.idx1-ubyte mnist_train_lmdb
../../Build/x64/Release/convert_mnist_data t10k-images.idx3-ubyte t10k-labels.idx1-ubyte mnist_test_lmdb
这样,训练集和测试集就创建好了,将其拷贝至D:caffe-windowsexamplesmnist目录下
 进入该目录,打开lenet_train_test.prototxt,修改如下
进入该目录,打开lenet_train_test.prototxt,修改如下
 然后打开lenet_solver.prototxt,修改第二行即可,
然后打开lenet_solver.prototxt,修改第二行即可,
 这里暂时不对这些配置文件做解释,只是安装完之后进行的测试,ok下面打开bash:
这里暂时不对这些配置文件做解释,只是安装完之后进行的测试,ok下面打开bash:
caffe train -solver=lenet_solver.prototxt -gpu 0
接着就可以看到一大串log出现,好像很厉害的样子!
 最后在测试集上的结果是99.13%!深度学习,很强势!
最后在测试集上的结果是99.13%!深度学习,很强势!
好了,windows下的安装配置就到这里告一段落了,训练大多数模型都已经没问题了
二.VM Ubuntu14.04下安装CPU版本的Caffe
大多数情况下,windows环境下的caffe能够完美完成Linux下caffe的功能了,但毕竟Linux是标准平台,网上的很多开源代码都是基于Linux下的caffe的,比如神经网络可视化工具deepvis,以及RGB大神的RCNN系列,而且大部分情况下只需要应用到Caffe在CPU下的版本,所以这里给出虚拟机下ubuntu14.04下安装caffe的过程
1.创建虚拟机
这里我使用虚拟机软件是VirtualBox.首先创建一个linux/ubuntu14.04/64位/4GB内存的名为caffe的虚拟机,这里内存官网建议是8GB,但是笔记本总内存才8GB,大家有条件的建议分8GB
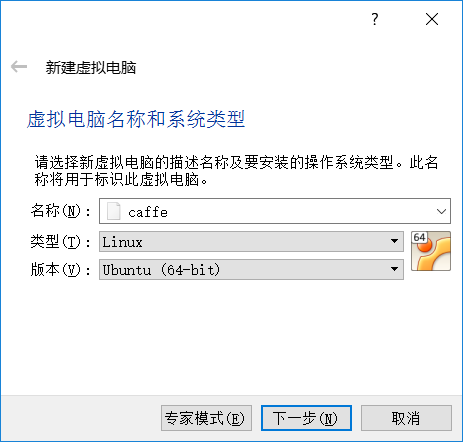
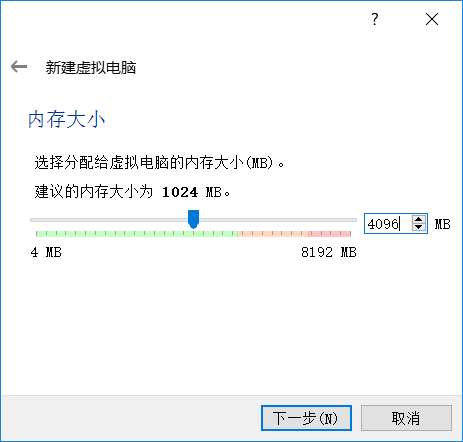
接下来一路下一步,
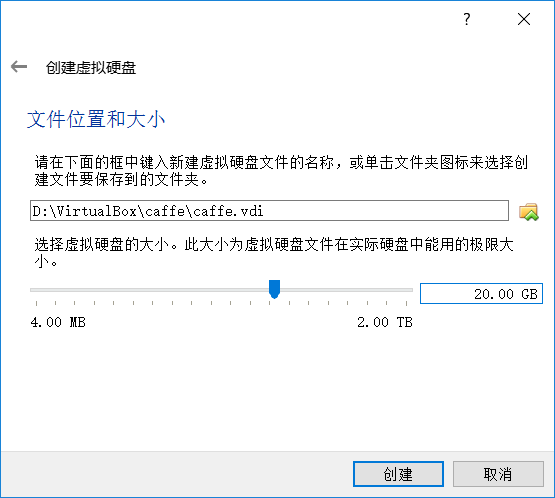 创建后点击启动,选择镜像,点击启动,
创建后点击启动,选择镜像,点击启动,
 下面就是创建虚拟机的一些常见操作了,贴几张关键的图吧
下面就是创建虚拟机的一些常见操作了,贴几张关键的图吧
 点击continue后,漫长的等待。。。
点击continue后,漫长的等待。。。
重启之后,我们先安装一下VBox Additions:
 选择设备下的安装增强功能,在终端中输入
选择设备下的安装增强功能,在终端中输入
cd /media/<USER>/VBOXADDITIONS_4.3.16_95972 (where <USER> is your user name)
sudo ./VBoxLinuxAdditions.run
在Virtual Box Manager, 点击Settings, 然后选择常规 | 高级 | 共享剪切板 | 双向,然后选择重启,这样虚拟机就可以充满全屏了,不再是一小块
 2.准备工作
2.准备工作
首先安装必要的环境:
sudo apt-get update #更新软件列表
sudo apt-get upgrade #更新软件
sudo apt-get install build-essential #安装build essentials
sudo apt-get install linux-headers-`uname -r` #安装最新版本的kernel headers
注意:官网缺少前两步,会导致CUDA安装失败
这也是个漫长的步骤,默默等待。。。
然后下载cuda7.5:
sudo apt-get install curl
cd Downloads/
curl -O "http://developer.download.nvidia.com/compute/cuda/7.5/Prod/local_installers/cuda_7.5.18_linux.run"
这又是个漫长的过程。。。如果嫌这种方式太慢,可以去官网直接下载,然后复制进虚拟机,不过这种方式有时会出现一点问题
chmod +x cuda_7.5.18_linux.run #使其可运行
sudo ./cuda_7.5.18_linux.run #运行
说明:安装的过程中会显示最终用户许可协议(EULA),很长,可以按‘q’退出阅读,然后安装的时候不要安装显卡驱动,因为虚拟机是没法使用GPU的,具体如下:
- Accept the EULA
- Do NOT install the graphics card drivers (since we are in a virtual machine)
- Install the toolkit (leave path at default)
- Install symbolic link
- Install samples (leave path at default)

然后更新相应的库路径:
echo 'export PATH=/usr/local/cuda/bin:$PATH' >> ~/.bashrc
echo 'export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda/lib64:/usr/local/lib' >> ~/.bashrc
source ~/.bashrc
安装必要的依赖库:
sudo apt-get install -y libprotobuf-dev libleveldb-dev libsnappy-dev libopencv-dev libboost-all-dev libhdf5-serial-dev protobuf-compiler gfortran libjpeg62 libfreeimage-dev libatlas-base-dev git python-dev python-pip libgoogle-glog-dev libbz2-dev libxml2-dev libxslt-dev libffi-dev libssl-dev libgflags-dev liblmdb-dev python-yaml
sudo easy_install pillow
下载Caffe并安装Python依赖库
cd ~
git clone https://github.com/BVLC/caffe.git
cd caffe
cat python/requirements.txt | xargs -L 1 sudo pip install
漫长的等待。。。
增加符号链接
sudo ln -s /usr/include/python2.7/ /usr/local/include/python2.7
sudo ln -s /usr/local/lib/python2.7/dist-packages/numpy/core/include/numpy/ /usr/local/include/python2.7/numpy
然后修改Makefile.config
cp Makefile.config.example Makefile.config
用gedit打开Makefile.config(或者直接用vim在终端中打开修改也可以)
1)去掉 # CPU_ONLY: = 1 的注释

2)在PYTHON_INCLUDE下, 把/usr/lib/python2.7/dist-packages/numpy/core/include替换成/usr/local/lib/python2.7/dist-packages/numpy/core/include

3.编译Caffe
终于可以编译caffe了,这三句即可,如果前面配置一切正常,这里应该不会出错
make pycaffe
make all
make test
依然是等待。。。
4.测试
这里我们测试一下CPU下的caffe能否正常运行即可:
首先为方便使用,我们将PYTHONPATH写入.bashrc中:
echo 'export PYTHONPATH=/home/<USER>/caffe/python' >> ~/.bashrc
source ~/.bashrc
然后在终端中输入:python和import caffe
 一切正常
一切正常
下面测试一下mnist数据集:
cd ~/caffe
./data/mnist/get_mnist.sh
./examples/mnist/create_mnist.sh
然后编辑examples/mnist文件夹下的lenet_solver.prototxt文件,将solver_mode模式从GPU改为CPU
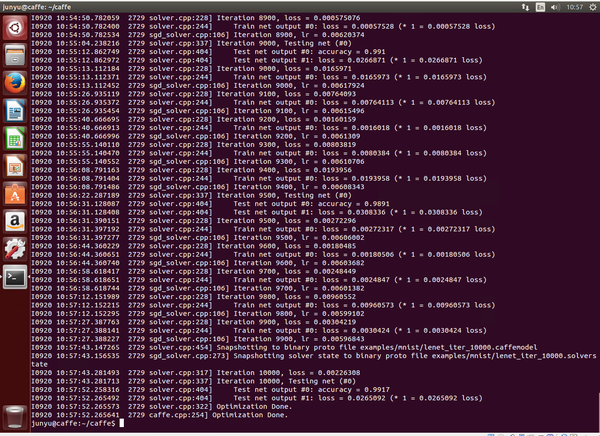
./examples/mnist/train_lenet.sh
由于是使用CPU进行训练,所以速度会比较慢,大概三十分钟才能整个训练完
配置过程主要参考官方文档:Ubuntu 14.04 VirtualBox VM · BVLC/caffe Wiki · GitHub
后面如果需要的话,还会继续添加在Ubuntu14.04中的caffe配置,但目前这两种已经够用了
Caffe的官网上Caffe | Deep Learning Framework 提供了很多的examples,你可以很容易地开始训练一些已有的经典模型,如LeNet。我建议先从 LeNet MNIST Tutorial开始,因为数据集很小,网络也很小但很经典,用很少的时间就可以跑起来了。当你看到terminal刷拉拉的一行行输出,看到不断减少的loss和不断上升的accuracy,训练结束你得到了99+%的准确率,感觉好厉害的样子。你可以多跑跑几个例子,熟悉一下环境和接口。
2.单步调试,跟着Caffe在网络里流动
当玩了几天之后,你对Caffe的接口有点熟悉了,对已有的例子也玩腻了,你开始想看看具体是怎么实现的了。我觉得最好的方法是通过单步调试的方式跟着程序一步一步的在网络里前向传播,然后再被当成误差信息传回来。
Caffe就像一个你平常编程中Project,你可以使用IDE或者GDB去调试它,这里我们不细说调试的过程。你可以先跟踪前向传播的过程,无非就是从高层次到低层次的调用Forward函数, Solver->Net->Layer->Specific Layer (Convolution等...).后向传播也类似,但因为你对Caffe里面的各种变量运算不熟悉,当你跟踪完前向传播时可能已经头晕眼花了,还是休息一下,消化一下整个前向传播的流程。
刚刚开始你没有必要对每个Layer的计算细节都那么较真,大概知道程序的运算流程就好,这样你才可以比较快的对Caffe有个大体的把握。
3.个性化定制Caffe
到这里,你已经可以说自己有用过Caffe了,但是还不能算入门,因为你还不知道怎么修改源码,满足自己特定的需求。我们很多时候都需要自己定义新的层来完成特定的运算,这时你需要在Caffe里添加新的层。
你一开肯定无从下手,脑子一片空白。幸运的是Caffe github上的Wiki Development · BVLC/caffe Wiki · GitHub已经有了教程了,而且这是最接近latest Caffe的源码结构的教程,你在网上搜到的Blog很多是有点过时的,因为Caffe最近又重构了代码。你可以跟着它的指导去添加自己的层。
虽然你已经知道要在哪里添加自己的东西了,但你遇到最核心的问题是如何写下面这四个函数。
- forward_cpu()
- forward_gpu()
- backward_cpu()
- backward_gpu()
4.理解并实现Backpropagation
这个我觉得是与平台无关的,不管你是使用Caffe、Torch 7,还是Theano,你都需要深刻理解并掌握的。因为我比较笨,花了好长时间才能够适应推导中的各种符号。其实也不难,就是误差顺着Chain rule法则流回到前面的层。我不打算自己推导后向传播的过程,因为我知道我没有办法将它表达得很好,而且网上已经有很多非常好的教程了。下面是我觉得比较好的学习步骤吧。
- 从浅层的神经网络(所谓的全连接层)的后向传播开始,因为这个比较简单,而且现在我们常说的CNN和LSTM的梯度计算也最终会回归到这里。
- 第一个必看的是Ng深入浅出的Ufldl教程UFLDL Tutorial,还有中文版的,这对不喜欢看英语的同学是个好消息。当然你看一遍不理解,再看一遍,忘了,再看,读个几遍你才会对推导过程和数学符号熟悉。我头脑不大行,来来回回看了好多次。
- 当然,Ufldl的教程有点短,我还发现了一个讲得更细腻清晰的教程, Michael Nielsen写的Neural networks and deep learning。它讲得实在太好了,以至于把我的任督二脉打通了。在Ufldl的基础上读这个,你应该可以很快掌握全连接层的反向传播。
- 最后在拿出standford大牛karpathy的一篇博客Hacker's guide to Neural Networks,这里用了具体的编程例子手把手教你算梯度,并不是推导后向传播公式的,是关于通用梯度计算的。用心去体会一下。
- 这时你跃跃欲试,回去查看Caffe源码里Convolution层的实现,但发现自己好像没看懂。虽说卷积层和全连接层的推导大同小异,但思维上还是有个gap的。我建议你先去看看Caffe如何实现卷积的,Caffe作者贾扬清大牛在知乎上的回答在 Caffe 中如何计算卷积?让我茅塞顿开。重点理解im2col和col2im.
- 这时你知道了Convolution的前向传播,还差一点就可以弄明白后向传播怎么实现了。我建议你死磕Caffe中Convolution层的计算过程,把每一步都搞清楚,经过痛苦的过程之后你会对反向传播有了新的体会的。在这之后,你应该有能力添加自己的层了。再补充一个完整的添加新的层的教程Making a Caffe Layer • Computer Vision Enthusiast。这篇教程从头开始实现了一个Angle To Sine Cosine Layer,包含了梯度推导,前向与后向传播的CPU和GPU函数,非常棒的一个教程。
- 最后,建议学习一下基本的GPU Cuda编程,虽然Caffe中已经把Cuda函数封装起来了,用起来很方便,但有时还是需要使用kernel函数等Cuda接口的函数。这里有一个入门的视频教程,讲得挺不错的NVIDIA CUDA初级教程视频。
本文只涉及Caffe结构的相关问题,不涉及具体实现技巧等细节。
==============================================================
1. 初识Caffe
1.1. Caffe相对与其他DL框架的优点和缺点:
优点:
- 速度快。Google Protocol Buffer数据标准为Caffe提升了效率。
- 学术论文采用此模型较多。不确定是不是最多,但接触到的不少论文都与Caffe有关(R-CNN,DSN,最近还有人用Caffe实现LSTM)
- 曾更新过重要函数接口。有人反映,偶尔会出现接口变换的情况,自己很久前写的代码可能过了一段时间就不能和新版本很好地兼容了。(现在更新速度放缓,接口逐步趋于稳定,感谢 评论区王峰的建议)
- 对于某些研究方向来说的人并不适合。这个需要对Caffe的结构有一定了解,(后面提到)。
回答里面有人说熟悉Blob,Layer,Net,Solver这样的几大类,我比较赞同。我基本是从这个顺序开始学习的,这四个类复杂性从低到高,贯穿了整个Caffe。把他们分为三个层次介绍。
- Blob:是基础的数据结构,是用来保存学习到的参数以及网络传输过程中产生数据的类。
- Layer:是网络的基本单元,由此派生出了各种层类。修改这部分的人主要是研究特征表达方向的。
- Net:是网络的搭建,将Layer所派生出层类组合成网络。Solver:是Net的求解,修改这部分人主要会是研究DL求解方向的。
==============================================================
2. Caffe进阶
2.1. Blob:
Caffe支持CUDA,在数据级别上也做了一些优化,这部分最重要的是知道它主要是对protocol buffer所定义的数据结构的继承,Caffe也因此可以在尽可能小的内存占用下获得很高的效率。(追求性能的同时Caffe也牺牲了一些代码可读性)
在更高一级的Layer中Blob用下面的形式表示学习到的参数:
vector<shared_ptr<Blob<Dtype> > > blobs_;
以及Layer所传递的数据形式,后面还会涉及到这里:
vector<Blob<Dtype>*> ⊥
vector<Blob<Dtype>*> *top
2.2.1. 5大Layer派生类型
Caffe十分强调网络的层次性,也就是说卷积操作,非线性变换(ReLU等),Pooling,权值连接等全部都由某一种Layer来表示。具体来说分为5大类Layer
- NeuronLayer类 定义于neuron_layers.hpp中,其派生类主要是元素级别的运算(比如Dropout运算,激活函数ReLu,Sigmoid等),运算均为同址计算(in-place computation,返回值覆盖原值而占用新的内存)。
- LossLayer类 定义于loss_layers.hpp中,其派生类会产生loss,只有这些层能够产生loss。
- 数据层 定义于data_layer.hpp中,作为网络的最底层,主要实现数据格式的转换。
- 特征表达层(我自己分的类)定义于vision_layers.hpp(为什么叫vision这个名字,我目前还不清楚),实现特征表达功能,更具体地说包含卷积操作,Pooling操作,他们基本都会产生新的内存占用(Pooling相对较小)。
- 网络连接层和激活函数(我自己分的类)定义于common_layers.hpp,Caffe提供了单个层与多个层的连接,并在这个头文件中声明。这里还包括了常用的全连接层InnerProductLayer类。
在Layer内部,数据主要有两种传递方式,正向传导(Forward)和反向传导(Backward)。Forward和Backward有CPU和GPU(部分有)两种实现。Caffe中所有的Layer都要用这两种方法传递数据。
virtual void Forward(const vector<Blob<Dtype>*> &bottom,
vector<Blob<Dtype>*> *top) = 0;
virtual void Backward(const vector<Blob<Dtype>*> &top,
const vector<bool> &propagate_down,
vector<Blob<Dtype>*> *bottom) = 0;
layers {
bottom: "decode1neuron" // 该层底下连接的第一个Layer
bottom: "flatdata" // 该层底下连接的第二个Layer
top: "l2_error" // 该层顶上连接的一个Layer
name: "loss" // 该层的名字
type: EUCLIDEAN_LOSS // 该层的类型
loss_weight: 0
}
loss
vector<Dtype> loss_;
learnable parameters
vector<shared_ptr<Blob<Dtype> > > blobs_;
2.3. Net:
Net用容器的形式将多个Layer有序地放在一起,其自身实现的功能主要是对逐层Layer进行初始化,以及提供Update( )的接口(更新网络参数),本身不能对参数进行有效地学习过程。
vector<shared_ptr<Layer<Dtype> > > layers_;
vector<Blob<Dtype>*>& Forward(const vector<Blob<Dtype>* > & bottom,
Dtype* loss = NULL);
void Net<Dtype>::Backward();
2.4. Solver
这个类中包含一个Net的指针,主要是实现了训练模型参数所采用的优化算法,它所派生的类就可以对整个网络进行训练了。
shared_ptr<Net<Dtype> > net_;
virtual void ComputeUpdateValue() = 0;
ComputeUpdateValue();
net_->Update();
==============================================================
至此,从底层到顶层对Caffe的主要结构都应该有了大致的概念。为了集中重点介绍Caffe的代码结构,文中略去了大量Caffe相关的实现细节和技巧,比如Layer和Net的参数如何初始化,proto文件的定义,基于cblas的卷积等操作的实现(cblas实现卷积这一点我的个人主页GanYuFei中的《Caffe学习笔记5-BLAS与boost::thread加速》有介绍)等等就不一一列举了。
整体来看Layer部分代码最多,也反映出Caffe比较重视丰富网络单元的类型,然而由于Caffe的代码结构高度层次化,使得某些研究以及应用(比如研究类似非逐层连接的神经网络这种复杂的网络连接方式)难以在该平台实现。这也就是一开始说的一个不足。
另外,Caffe基本数据单元都用Blob,使得数据在内存中的存储变得十分高效,紧凑,从而提升了整体训练能力,而同时带来的问题是我们看见的一些可读性上的不便,比如forward的参数也是直接用Blob而不是设计一个新类以增强可读性。所以说性能的提升是以可读性为代价的。
最后一点也是最重要的一点,我从Caffe学到了很多。第一次看的C++项目就看到这么好的代码,实在是受益匪浅,在这里也感谢作者贾扬清等人的贡献。
深度学习源码解读-ch1-JSON is awesome - 黑客与画家 - 知乎专栏
深度学习源码解读-ch2-Caffe is coming - 黑客与画家 - 知乎专栏
深度学习源码解读-ch3-Caffe is brewing - 黑客与画家 - 知乎专栏
深度学习源码解读-ch4-Caffe 中的设计模式 - 黑客与画家 - 知乎专栏