使用python来访问Hadoop HDFS存储实现文件的操作
原文:http://rfyiamcool.blog.51cto.com/1030776/1258292
在调试环境下,咱们用hadoop提供的shell接口测试增加删除查看,但是不利于复杂的逻辑编程

查看文件内容

用python访问hdfs是个很头疼的事情。。。。
这个是pyhdfs的库


1 import pyhdfs
2 fs = pyhdfs.connect("192.168.1.1", 9000)
3 pyhdfs.get(fs, "/rui/111", "/var/111")
4 f = pyhdfs.open(fs, "/test/xxx", "w")
5 pyhdfs.write(fs, f, "fuck�gfw
")
6 pyhdfs.close(fs, f)
7 pyhdfs.disconnect(fs)
pyhdfs的安装过程很吐血
1 svn checkout http://libpyhdfs.googlecode.com/svn/trunk/ libpyhdfs 2 cd libpyhdfs 3 cp /usr/lib/hadoop-0.20/hadoop-core-0.20.2-cdh3u0.jar lib/hadoop-0.20.1-core.jar 4 cp /usr/lib/hadoop-0.20/lib/commons-logging-1.0.4.jar lib/ 5 cp /usr/lib/libhdfs.so.0 lib/ 6 ln –s lib/libhdfs.so.0 lib/libhdfs.so 7 python setup.py install --prefix="/usr/local"
还有就是把 selinux也给关了 不然会出现莫名的问题
如果出现
/usr/lib/jvm/java-6-sun/include/jni.h:27:20: error: jni_md.h: No such file or directory
搜下find / -name jni.h
然后修改#include "jni_md.h" 为 #include "linux/jni_md.h"
这个是用pydoop的库
1 import pydoop.hdfs as hdfs
2 with hdfs.open('/user/myuser/filename') as f:
3 for line in f:
4 print(line)
我现在使用的方法是用subprocess ,哈哈,方法很搓吧,主要原因是我这边没有太多的性能估计,只是单纯的把mapreduce的接口给搞出来而已。
这么简单用用也还可以的~
需要把很多自己常用的指定都封装成库
1 cat = subprocess.Popen(["hadoop", "fs", "-cat", "/path/to/myfile"], stdout=subprocess.PIPE) 2 for line in cat.stdout: 3 print line
补充下(从视hadoop为儿戏到现在对mapreduce半斤八两,对我自己来说,还是有很大的进步的。所以关于hadoop python操作不能再用以前的方法啦。):
最近了解了更加方便的库,算是文档和利用最好的了。
pyhdfs是对libhdfs的python封装库. 它提供了一些常用方法来处理HDFS上的文件和目录, 比如读写文件, 枚举目录文件, 显示HDFS可用空间, 显示文件的复制块数等。
libhdfs 是HDFS的底层C函数库, 由hadoop官方提供, pyhdfs使用swig技术, 对libhdfs提供的绝大多数函数进行了封装, 目的是提供更简单的调用方式.
1 如何连接hadoop集群?
2 fs = hadoop.HadoopDFS("username","password","ugi",64310)
3 fs.disconnect()
4 如何获取当前工作目录?
5 fs = hadoop.HadoopDFS("username","password","ugi",64310)
6 print fs.getWorkingDirectory()
7 fs.disconnect()
8 如何更改当前工作目录?
9 fs = hadoop.HadoopDFS("username","password","ugi",64310)
10 print fs.setWorkingDirectory("/user/ns-lsp/logs")
11 fs.disconnect()
12 如果目录不存在setWorkingDirectory()返回-1,如果执行成功,返回0
13 如果目录不存在setWorkingDirectory()返回-1,如果执行成功,返回0
14 如何判断某个文件/目录是否存在?
15 fs = hadoop.HadoopDFS("username","password","ugi",64310)
16 print fs.pathExists("/user/ns-lsp/logs")
17 fs.disconnect()
18 文件/目录存在,返回0,如果不存在,返回-1
19 如何创建一个目录?
20 fs = hadoop.HadoopDFS("username","password","ugi",64310)
21 print fs.createDirectory("/user/ns-lsp/logs/cjj")
22 fs.disconnect()
23 如果目录已经存在,则返回-1,如果目录创建成功,返回0
24 如何获得当前默认块大小?
25 fs = hadoop.HadoopDFS("username","password","ugi",64310)
26 print fs.getDefaultBlockSize()
27 fs.disconnect()
28 如何获得当期目录下的文件/目录?
29 fs = hadoop.HadoopDFS("username","password","ugi",64310)
30 print fs.listDirectory("/user/ns-lsp/logs")
31 fs.disconnect()
32 如何移动一个文件/目录?
33 同一HDFS内移动文件:
34 fs = hadoop.HadoopDFS("username","password","ugi",64310)
35 print fs.move("/user/ns-lsp/logs/cjj","/user/ns-lsp/logs/cjj_new")
36 fs.disconnect()
37 不同HDFS之间移动文件:
38 target_fs = hadoop.HadoopDFS("username","password","ugi",64310)
39 fs = hadoop.HadoopDFS("username","password","ugi",64310)
40 print fs.move("/user/ns-lsp/logs/cjj","/user/ns-lsp/logs/cjj_new",target_fs)
41 fs.disconnect()
42 如何删除一个文件/目录?
43 fs = hadoop.HadoopDFS("username","password","ugi",64310)
44 print fs.delete("/user/ns-lsp/logs/cjj_new")
45 fs.disconnect()
46 如何重命名一个文件/目录?
47 fs = hadoop.HadoopDFS("username","password","ugi",64310)
48 print fs.rename("/user/ns-lsp/logs/cjj","/user/ns-lsp/logs/cjj1")
49 fs.disconnect()
50 如何修改一个文件/目录的权限?
51 fs = hadoop.HadoopDFS("username","password","ugi",64310)
52 print fs.chmod("/user/ns-lsp/logs/cjj",7)
53 fs.disconnect()
54 如何文件块所在的服务器名?
55 有时我们需要查找某些文件块所在的服务器名是什么,可以如下使用:
56 fs = hadoop.HadoopDFS("username","password","ugi",64310)
57 print fs.getHosts("/user/ns-lsp/logs/cjj/a",0,1)
58 fs.disconnect()
59 返回包含服务器名的列表.
60 $ python gethosts.py
61 ['xxxx']
62 如何获取一个文件/目录的信息?
63 fs = hadoop.HadoopDFS("username","password","ugi",64310)
64 pathinfo = fs.getPathInfo("/user/ns-lsp/logs/cjj")
65 fs.disconnect()
66 getPathInfo()返回一个hdfsFileInfo类。
67 如何指定文件的备份数?
68 fs = hadoop.HadoopDFS("username","password","ugi",64310)
69 print fs.setReplication("/user/ns-lsp/logs/cjj/a",3)
70 fs.disconnect()
71 如何打开一个文件,并读取数据?
72 要操作文件,需要创建一个HadoopFile对象,并利用read()方法读取数据.
73 fs = hadoop.HadoopDFS("username","password","ugi",64310)
74 fh = hadoop.HadoopFile(fs,'/user/ns-lsp/logs/cjj/a')
75 print fh.read()
76 fh.close()
77 fs.disconnect()
HDFS写入和读取流程
一、HDFS
HDFS全称是Hadoop Distributed System。HDFS是为以流的方式存取大文件而设计的。适用于几百MB,GB以及TB,并写一次读多次的场合。而对于低延时数据访问、大量小文件、同时写和任意的文件修改,则并不是十分适合。
目前HDFS支持的使用接口除了Java的还有,Thrift、C、FUSE、WebDAV、HTTP等。HDFS是以block-sized chunk组织其文件内容的,默认的block大小为64MB,对于不足64MB的文件,其会占用一个block,但实际上不用占用实际硬盘上的64MB,这可以说是HDFS是在文件系统之上架设的一个中间层。之所以将默认的block大小设置为64MB这么大,是因为block-sized对于文件定位很有帮助,同时大文件更使传输的时间远大于文件寻找的时间,这样可以最大化地减少文件定位的时间在整个文件获取总时间中的比例 。
二、HDFS的体系结构
构成HDFS主要是Namenode(master)和一系列的Datanode(workers)。Namenode是管理HDFS的目录树和相关的文件元数据,这些信息是以"namespace image"和"edit log"两个文件形式存放在本地磁盘,但是这些文件是在HDFS每次重启的时候重新构造出来的。Datanode则是存取文件实际内容的节点,Datanodes会定时地将block的列表汇报给Namenode。
由于Namenode是元数据存放的节点,如果Namenode挂了那么HDFS就没法正常运行,因此一般使用将元数据持久存储在本地或远程的机器上,或者使用secondary namenode来定期同步Namenode的元数据信息,secondary namenode有点类似于MySQL的Master/Salves中的Slave,"edit log"就类似"bin log"。如果Namenode出现了故障,一般会将原Namenode中持久化的元数据拷贝到secondary namenode中,使secondary namenode作为新的Namenode运行起来。
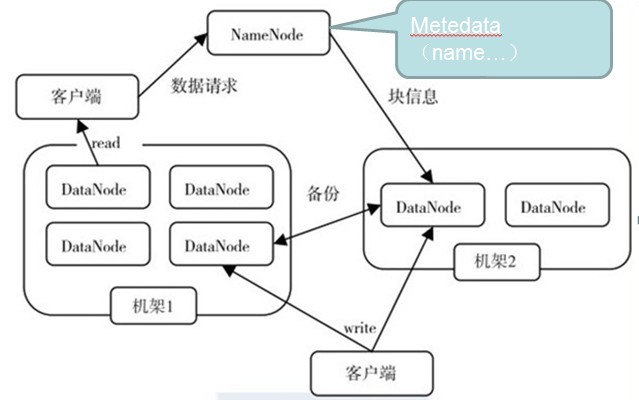
三、读写流程
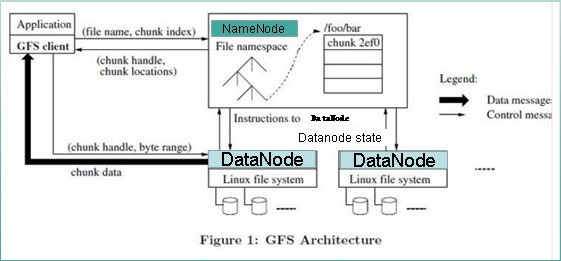
GFS论文提到的文件读取简单流程:
详细流程:
文件读取的过程如下:
- 使用HDFS提供的客户端开发库Client,向远程的Namenode发起RPC请求;
- Namenode会视情况返回文件的部分或者全部block列表,对于每个block,Namenode都会返回有该block拷贝的DataNode地址;
- 客户端开发库Client会选取离客户端最接近的DataNode来读取block;如果客户端本身就是DataNode,那么将从本地直接获取数据.
- 读取完当前block的数据后,关闭与当前的DataNode连接,并为读取下一个block寻找最佳的DataNode;
- 当读完列表的block后,且文件读取还没有结束,客户端开发库会继续向Namenode获取下一批的block列表。
- 读取完一个block都会进行checksum验证,如果读取datanode时出现错误,客户端会通知Namenode,然后再从下一个拥有该block拷贝的datanode继续读。
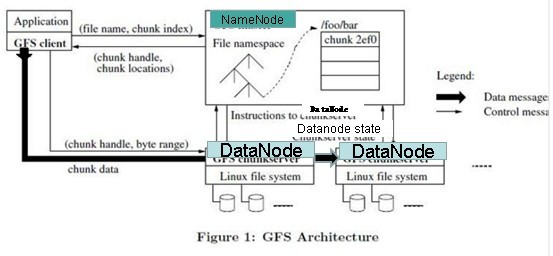
GFS论文提到的写入文件简单流程:
详细流程:
写入文件的过程比读取较为复杂:
- 使用HDFS提供的客户端开发库Client,向远程的Namenode发起RPC请求;
- Namenode会检查要创建的文件是否已经存在,创建者是否有权限进行操作,成功则会为文件创建一个记录,否则会让客户端抛出异常;
- 当客户端开始写入文件的时候,开发库会将文件切分成多个packets,并在内部以数据队列"data queue"的形式管理这些packets,并向Namenode申请新的blocks,获取用来存储replicas的合适的datanodes列表,列表的大小根据在Namenode中对replication的设置而定。
- 开始以pipeline(管道)的形式将packet写入所有的replicas中。开发库把packet以流的方式写入第一个datanode,该datanode把该packet存储之后,再将其传递给在此pipeline中的下一个datanode,直到最后一个datanode,这种写数据的方式呈流水线的形式。
- 最后一个datanode成功存储之后会返回一个ack packet,在pipeline里传递至客户端,在客户端的开发库内部维护着"ack queue",成功收到datanode返回的ack packet后会从"ack queue"移除相应的packet。
- 如果传输过程中,有某个datanode出现了故障,那么当前的pipeline会被关闭,出现故障的datanode会从当前的pipeline中移除,剩余的block会继续剩下的datanode中继续以pipeline的形式传输,同时Namenode会分配一个新的datanode,保持replicas设定的数量。