正则表达式
前面十项,仅仅是想尽各种办法,突破各种常见限制,从而可以顺利访问网站,接下来的问题就是如何从一大堆html代码中提取我们需要的内容,主要介绍十分强大的正则表达式。
了解正则表达式

正则表达式是用来匹配字符串非常强大的工具,在其他编程语言中同样有正则表达式的概念,Python同样不例外,利用了正则表达式,我们想要从返回的页面内容提取出我们想要的内容就很容易了。

正则表达式的语法规则
下面是Python中正则表达式的一些匹配规则:

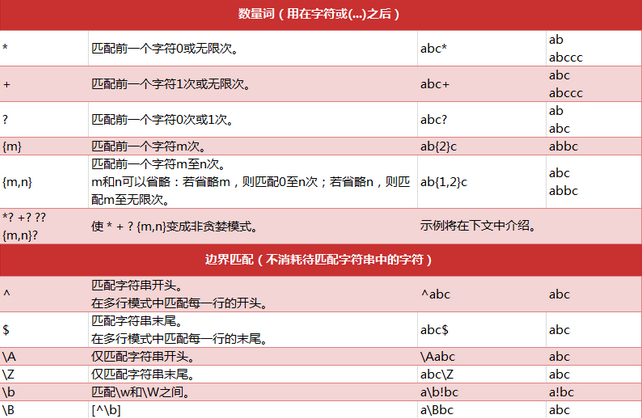
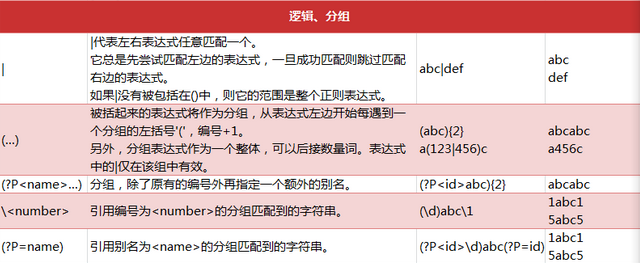

正则表达式相关注解
数量词的贪婪模式与非贪婪模式
正则表达式通常用于在文本中查找匹配的字符串。Python里数量词默认是贪婪的(在少数语言里可能是默认非贪婪),总是尝试匹配尽可能多的字符;非贪婪的则相反,总是尝试匹配尽可能少的字符。例如:正则表达式“ab*”如果用于查找“abbbc”,将找到“abbb”。而如果使用非贪婪的数量词“ab*?”,将找到“a”。我们一般使用非贪婪模式来提取。
反斜杠问题
与大多数编程语言相同,正则表达式里使用“”作为转义字符,这就可能造成反斜杠困扰。假如你需要匹配文本中的字符“”,那么使用编程语言表示的正则表达式里将需要4个反斜杠“\\”:前面两个和后面两个分别用于在编程语言里转义成反斜杠,转换成两个反斜杠后再在正则表达式里转义成一个反斜杠。
Python里的原生字符串很好地解决了这个问题,这个例子中的正则表达式可以使用r”\”表示。同样,匹配一个数字的“\d”可以写成r”d”。
Python Re模块
Python自带了re模块,它提供了对正则表达式的支持。主要用到的方法列举如下:
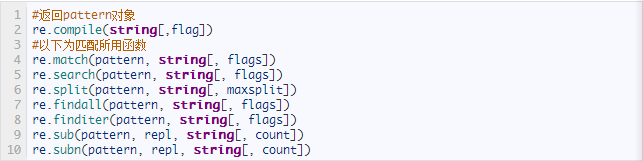
介绍这几个方法之前,我们先来介绍一下pattern的概念,pattern可以理解为一个匹配模式,那么我们怎么获得这个匹配模式呢?很简单的,我们需要利用re.compile方法就可以。例如:

在参数中我们传入了原生字符串对象,通过compile方法编译生成一个pattern对象,然后我们利用这个对象来进行进一步的匹配。
另外还有另一个参数flags,在这里解释一下这个参数的含义:
参数flag是匹配模式,取值可以利用按位或运算符‘|’表示同时生效,比如re.I | re.M。
可选值有:

在刚才所说的另几个方法例如re.match里我们就需要用到这个pattern了,下面我们一一介绍。

Re.match(pattern,string[,flags])
这个方法将会从string(我们要匹配的字符串)的开头开始,尝试匹配pattern,一直向后匹配,如果遇到无法匹配的字符,立即返回None,如果匹配未结束已经到达string的末尾,也会返回None。两个结果均表示匹配失败,否则匹配pattern成功,同时匹配终止,不再对string向后匹配。下面我们通过一个例子解释一下:

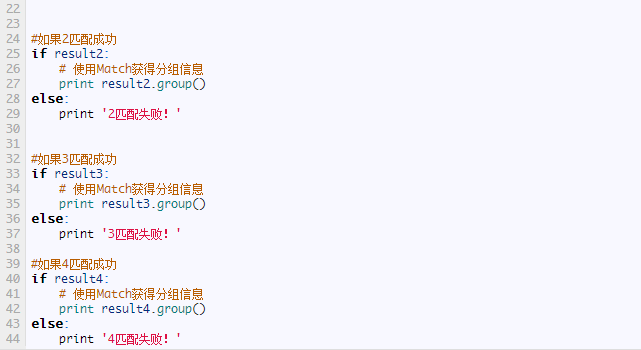
运行结果:

匹配分析
第一个匹配,pattern正则表达式为‘hello’,我们匹配的目标字符串string也为hello,从头至尾完全匹配,匹配成功。
第二个匹配,string为hello CQC,从string头开始匹配pattern完全可以匹配,pattern匹配结束,同时匹配终止,后面的o CQC不再匹配,返回匹配成功的信息。
第三个匹配,string为helo CQC,从string头开始匹配pattern,发现到‘o’时无法完成匹配,匹配终止,返回None。
第四个匹配,同第二个匹配原理,即使遇到了空格符也不会受影响。
我们还看到最后打印出了result.group(),这个是什么意思呢?下面我们说一下关于match对象的属性和方法。
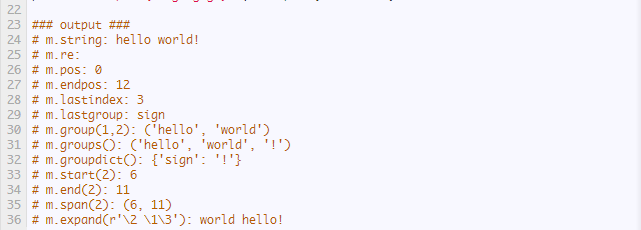
Match对象是一次匹配的结果,包含了许多关于此次匹配的信息,可以使用Match提供的可读属性或方法来获取这些信息。


下面我们用一个例子来体会一下

Re.search(pattern,string[,flags])
Search方法与match方法极其类似,区别在于match()函数只检测re是不是在string的开始位置匹配,search()会扫描整个string查找匹配,match()只有在0位置匹配成功的话才有返回,如果不是开始位置匹配成功的话,match()就会返回None。同样,search方法的返回对象同样match()返回对象的方法和属性。我们用一个例子感受一下:

Re.split(pattern,string[,maxsplit])
按照能够匹配的子串将string分割后返回列表。Maxsplit用于指定最大分割次数,不指定将全部分割。我们通过下面的例子感受一下。

Re.findall(pattern,string[,flags])
搜索string,以列表形式返回全部能匹配的子串。我们通过这个例子来感受一下。

Re.finditer(pattern,string[,flags])
搜索string,返回一个顺序访问每一个匹配结果(Match对象)的迭代器。我们通过下面的例子来感受一下:

Re.sub(pattern,repl,string[,count])
使用repl替换string中每一个匹配的子串后返回替换的字符串。当repl是一个字符串时,可以使用id或g、g引用分组,但不能使用编号0.当repl是一个方法时,这个方法应当只接受一个参数(Match对象),并返回一个字符串用于替换(返回的字符串中不能再引用分组)。Count用于指定最多替换次数,不指定时全部替换。

Re.subn(pattern,repl,string[,count])
返回(sub(repl,string[,count]),替换次数)。

Python Re模块的另一种使用方式
在上面我们介绍了7个工具方法,例如match,search等等,不过调用方式都是re.match,re.search的方式,其实还有另外一种调用方式,可以通过pattern.match,pattern.search调用,这样调用便不用将pattern作为第一个参数传入了,大家想怎样调用皆可。
函数API列表
