PHP, Python, Node.js 哪个比较适合写爬虫?
按投票排序
按时间排序
35 个回答

主要看你定义的“爬虫”干什么用。
1、如果是定向爬取几个页面,做一些简单的页面解析,爬取效率不是核心要求,那么用什么语言差异不大。
当然要是页面结构复杂,正则表达式写得巨复杂,尤其是用过那些支持xpath的类库/爬虫库后,就会发现此种方式虽然入门门槛低,但扩展性、可维护性等都奇差。因此此种情况下还是推荐采用一些现成的爬虫库,诸如xpath、多线程支持还是必须考虑的因素。
2、如果是定向爬取,且主要目标是解析js动态生成的内容
此时候,页面内容是有js/ajax动态生成的,用普通的请求页面->解析的方法就不管用了,需要借助一个类似firefox、chrome浏览器的js引擎来对页面的js代码做动态解析。
此种情况下,推荐考虑casperJS+phantomjs或slimerJS+phantomjs ,当然诸如selenium之类的也可以考虑。
3、如果爬虫是涉及大规模网站爬取,效率、扩展性、可维护性等是必须考虑的因素时候
大规模爬虫爬取涉及诸多问题:多线程并发、I/O机制、分布式爬取、消息通讯、判重机制、任务调度等等,此时候语言和所用框架的选取就具有极大意义了。
PHP对多线程、异步支持较差,不建议采用。
NodeJS:对一些垂直网站爬取倒可以,但由于分布式爬取、消息通讯等支持较弱,根据自己情况判断。
Python:强烈建议,对以上问题都有较好支持。尤其是Scrapy框架值得作为第一选择。优点诸多:支持xpath;基于twisted,性能不错;有较好的调试工具;
此种情况下,如果还需要做js动态内容的解析,casperjs就不适合了,只有基于诸如chrome V8引擎之类自己做js引擎。
至于C、C++虽然性能不错,但不推荐,尤其是考虑到成本等诸多因素;对于大部分公司还是建议基于一些开源的框架来做,不要自己发明轮子,做一个简单的爬虫容易,但要做一个完备的爬虫挺难的。
像我搭建的微信公众号内容聚合的网站http://lewuxian.com就是基于Scrapy做的,当然还涉及消息队列等。可以参考下图:
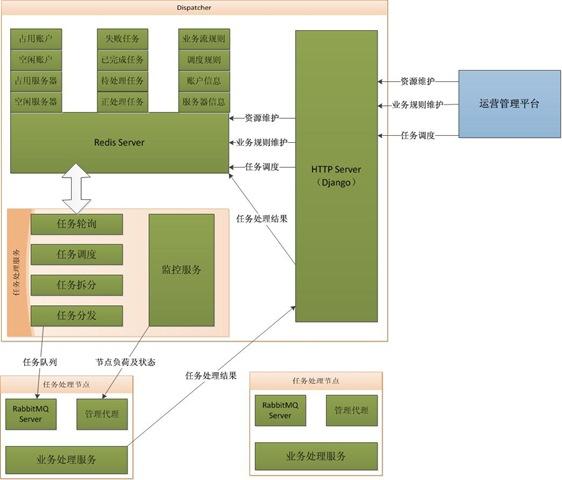
具体内容可以参考 一个任务调度分发服务的架构
1、如果是定向爬取几个页面,做一些简单的页面解析,爬取效率不是核心要求,那么用什么语言差异不大。
当然要是页面结构复杂,正则表达式写得巨复杂,尤其是用过那些支持xpath的类库/爬虫库后,就会发现此种方式虽然入门门槛低,但扩展性、可维护性等都奇差。因此此种情况下还是推荐采用一些现成的爬虫库,诸如xpath、多线程支持还是必须考虑的因素。
2、如果是定向爬取,且主要目标是解析js动态生成的内容
此时候,页面内容是有js/ajax动态生成的,用普通的请求页面->解析的方法就不管用了,需要借助一个类似firefox、chrome浏览器的js引擎来对页面的js代码做动态解析。
此种情况下,推荐考虑casperJS+phantomjs或slimerJS+phantomjs ,当然诸如selenium之类的也可以考虑。
3、如果爬虫是涉及大规模网站爬取,效率、扩展性、可维护性等是必须考虑的因素时候
大规模爬虫爬取涉及诸多问题:多线程并发、I/O机制、分布式爬取、消息通讯、判重机制、任务调度等等,此时候语言和所用框架的选取就具有极大意义了。
PHP对多线程、异步支持较差,不建议采用。
NodeJS:对一些垂直网站爬取倒可以,但由于分布式爬取、消息通讯等支持较弱,根据自己情况判断。
Python:强烈建议,对以上问题都有较好支持。尤其是Scrapy框架值得作为第一选择。优点诸多:支持xpath;基于twisted,性能不错;有较好的调试工具;
此种情况下,如果还需要做js动态内容的解析,casperjs就不适合了,只有基于诸如chrome V8引擎之类自己做js引擎。
至于C、C++虽然性能不错,但不推荐,尤其是考虑到成本等诸多因素;对于大部分公司还是建议基于一些开源的框架来做,不要自己发明轮子,做一个简单的爬虫容易,但要做一个完备的爬虫挺难的。
像我搭建的微信公众号内容聚合的网站http://lewuxian.com就是基于Scrapy做的,当然还涉及消息队列等。可以参考下图:
具体内容可以参考 一个任务调度分发服务的架构

稍微谈谈我的使用感受,PHP不会,用过Python和Node.js。
简单的定向爬取:
Python + urlib2 + RegExp + bs4
或者
Node.js + co,任一一款dom框架或者html parser + Request + RegExp 撸起来也是很顺手。
对我来说上面两个选择差不多是等价的,但主要我JS比较熟,现在选择Node平台会多一些。
上规模的整站爬取:
Python + Scrapy
如 果说上面两个方案里DIY 的 spider是小米加步枪,那Scrapy简直就是重工加农炮,好用到不行,自定义爬取规则,http错误处理,XPath,RPC,Pipeline机 制等等等。而且,由于Scrapy是基于Twisted实现的,所以同时兼顾有非常好的效率,相对来说唯一的缺点就是安装比较麻烦,依赖也比较多,我还算 是比较新的osx,一样没办法直接pip install scrapy
另外如果在spider中引入xpath的话,再在chrome上安装xpath的插件,那么解析路径一目了然,开发效率奇高。
简单的定向爬取:
Python + urlib2 + RegExp + bs4
或者
Node.js + co,任一一款dom框架或者html parser + Request + RegExp 撸起来也是很顺手。
对我来说上面两个选择差不多是等价的,但主要我JS比较熟,现在选择Node平台会多一些。
上规模的整站爬取:
Python + Scrapy
如 果说上面两个方案里DIY 的 spider是小米加步枪,那Scrapy简直就是重工加农炮,好用到不行,自定义爬取规则,http错误处理,XPath,RPC,Pipeline机 制等等等。而且,由于Scrapy是基于Twisted实现的,所以同时兼顾有非常好的效率,相对来说唯一的缺点就是安装比较麻烦,依赖也比较多,我还算 是比较新的osx,一样没办法直接pip install scrapy
另外如果在spider中引入xpath的话,再在chrome上安装xpath的插件,那么解析路径一目了然,开发效率奇高。

PHP和js天生不是干这个的;python有比较完善的框架,但我没用过不太清楚;不过nodejs倒是可以拿来谈谈,因为看知乎的数据就是用node抓的。
估计和我一样在Windows开发、部署到linux服务器的人不少。nodejs在这时就有个很突出的优点:部署方便、跨平台几乎无障碍,相比之下python……简直让人脱层皮。
解析页面用的是cheerio,全兼容jQuery语法,熟悉前端的话用起来爽快之极,再也不用折腾烦人的正则了;
操作数据库直接用mysql这个module就行,该有的功能全有;
爬 取效率么,其实没有真正做过压力测试,因为我抓的是知乎,线程稍多一点瓶颈就跑到带宽上。而且它也不是真多线程而是异步,最后带宽全满(大约几百线程、 10MB/s左右)时,CPU也不过50%左右,这还只是一个linode最低配主机的CPU。况且平时我限制了线程和抓取间隔,简直不怎么消耗性能;
最后是代码,异步编程最头疼的是掉进callback地狱,根据自己实际情况写个多线队列的话,也不比同步编程麻烦太多就是了。
估计和我一样在Windows开发、部署到linux服务器的人不少。nodejs在这时就有个很突出的优点:部署方便、跨平台几乎无障碍,相比之下python……简直让人脱层皮。
解析页面用的是cheerio,全兼容jQuery语法,熟悉前端的话用起来爽快之极,再也不用折腾烦人的正则了;
操作数据库直接用mysql这个module就行,该有的功能全有;
爬 取效率么,其实没有真正做过压力测试,因为我抓的是知乎,线程稍多一点瓶颈就跑到带宽上。而且它也不是真多线程而是异步,最后带宽全满(大约几百线程、 10MB/s左右)时,CPU也不过50%左右,这还只是一个linode最低配主机的CPU。况且平时我限制了线程和抓取间隔,简直不怎么消耗性能;
最后是代码,异步编程最头疼的是掉进callback地狱,根据自己实际情况写个多线队列的话,也不比同步编程麻烦太多就是了。

Kenneth Ma、知乎用户、知乎用户
等人赞同
一点一点做解答吧:
另外,最近在我的专栏总结一些Python编写爬虫的经验,如果有兴趣欢迎围观指正。
专栏地址:http://zhuanlan.zhihu.com/xlz-d
1.对页面的解析能力关于这一条,基本上就是靠特定语言的第三方包来完成 网页的解析。如果要从零开始自己实现一个HTML解析器,难度和时间上的阻碍都是很大的。而对于复杂的基于大量Javascript运算生成的网页或者请 求,则可以通过调度浏览器环境来完成。这一条上,Python是绝对胜任的。
2.对数据库的操作能力(mysql)对数据库的操作能力上,Python有官方及第三方的连接库。另外,对于爬虫抓取的数据,存储在NoSQL型数据库个人认为更加合适。
3.爬取效率确实脚本语言的运算速度不高,但是相对于特定网站反爬虫机制强度以及网络IO的速度,这几门语言的速度诧异都可以忽略不计,而在于开发者的水平。如果利用好发送网络请求的等待时间处理另外的事情(多线程、多进程或者协程),那么各语言效率上是不成问题的。
4.代码量这一点上Python是占有优势的,众所周知Python代码简洁著称,只要开发者水平到位,Python代码可以像伪代码一样简洁易懂,且代码量较低。
推荐语言时说明所需类库或者框架,谢谢。Python: requests + MongoDB + BeautifulSoup
比如:python+MySQLdb+urllib2+re
ps:其实我不太喜欢用python(可能是在windows平台的原因,需要各种转字符编码,而且多线程貌似很鸡肋。)由于GIL的存在,Python的多线程确实没有利用到多核的优势,对此你可以使用多进程解决。但是对于爬虫,更多的时间在于网络IO的等待上,所以直接使用协程即可很好地提升抓取速度。
另外,最近在我的专栏总结一些Python编写爬虫的经验,如果有兴趣欢迎围观指正。
专栏地址:http://zhuanlan.zhihu.com/xlz-d

python有scapy,专门用来做爬虫的一个框架

我用 PHP Node.js Python 写过抓取脚本,简单谈一下吧。
首先PHP。先说优势:网上抓取和解析html的框架一抓一 大把,各种工具直接拿来用就行了,比较省心。缺点:首先速度/效率很成问题,有一次下载电影海报的时候,由于是crontab定期执行,也没做优化,开的 php进程太多,直接把内存撑爆了。然后语法方面也很拖沓,各种关键字 符号 太多,不够简洁,给人一种没有认真设计过的感觉,写起来很麻烦。
Node.js。 优点是效率、效率还是效率,由于网络是异步的,所以基本如同几百个进程并发一样强大,内存和CPU占用非常小,如果没有对抓取来的数据进行复杂的运算加 工,那么系统的瓶颈基本就在带宽和写入MySQL等数据库的I/O速度。当然,优点的反面也是缺点,异步网络代表你需要callback,这时候如果业务 需求是线性了,比如必须等待上一个页面抓取完成后,拿到数据,才能进行下一个页面的抓取,甚至多层的依赖关系,那就会出现可怕的多层callback!基 本这时候,代码结构和逻辑就会一团乱麻。当然可以用Step等流程控制工具解决这些问题。
最后说Python。如果你对效率没有极端的要求,那么推荐用Python!首先,Python的语法很简洁,同样的语句,可以少敲很多次键盘。然后,Python非常适合做数据的处理,比如函数参数的打包解包,列表解析,矩阵处理,非常方便。
自己最近也在弄一个Python的数据抓取处理工具包,还在修改完善中,欢迎star:yangjiePro/cutout - GitHub
首先PHP。先说优势:网上抓取和解析html的框架一抓一 大把,各种工具直接拿来用就行了,比较省心。缺点:首先速度/效率很成问题,有一次下载电影海报的时候,由于是crontab定期执行,也没做优化,开的 php进程太多,直接把内存撑爆了。然后语法方面也很拖沓,各种关键字 符号 太多,不够简洁,给人一种没有认真设计过的感觉,写起来很麻烦。
Node.js。 优点是效率、效率还是效率,由于网络是异步的,所以基本如同几百个进程并发一样强大,内存和CPU占用非常小,如果没有对抓取来的数据进行复杂的运算加 工,那么系统的瓶颈基本就在带宽和写入MySQL等数据库的I/O速度。当然,优点的反面也是缺点,异步网络代表你需要callback,这时候如果业务 需求是线性了,比如必须等待上一个页面抓取完成后,拿到数据,才能进行下一个页面的抓取,甚至多层的依赖关系,那就会出现可怕的多层callback!基 本这时候,代码结构和逻辑就会一团乱麻。当然可以用Step等流程控制工具解决这些问题。
最后说Python。如果你对效率没有极端的要求,那么推荐用Python!首先,Python的语法很简洁,同样的语句,可以少敲很多次键盘。然后,Python非常适合做数据的处理,比如函数参数的打包解包,列表解析,矩阵处理,非常方便。
自己最近也在弄一个Python的数据抓取处理工具包,还在修改完善中,欢迎star:yangjiePro/cutout - GitHub

写爬虫我用过PHP、Python,JS写爬虫还没见过,Node.js不了解。
1.对页面的解析能力基本没区别,大家都支持正则,不过Python有些傻瓜拓展,用起来会方便很多;
2.对数据库的操作能力的话,PHP对MySQL有原生支持,Python需要添加MySQLdb之类的lib,不过也不算麻烦;
3.爬取效率的话,都支持多线程,效率我倒是没感觉有什么区别,基本上瓶颈只在网络上了。不过严谨的测试我没做过,毕竟我没有用多种语言实现同一种功能的习惯,不过我倒是感觉PHP好像还要快一些?
4.代码量的话,爬虫这种简单的东西基本没什么区别,几十行的事,如果加上异常处理也就百来行,或者麻烦点异常的Mark下来,等下重爬等等的处理,也就几百行,大家都没什么区别。
不过Python如果不把lib算进去的话显然是最少的。
 说到性能的话,爬虫和性能基本不搭边,是不用考虑的事情。
在我开爬虫的时候,将近30Mbps的爬取效率下,用PHP Command
Line做的爬虫,CPU占用也不过3-5%,内存消耗大概15-20MiB(Core 2 Duo
P8700——有些历史的老U了,爬虫是50线程,每个线程含10个正则提取、1个JSON解析、2个数据库Insert操作 (百万级别数据的IF
NOT EXIST )、40个左右的各种异常判断)——瓶颈应该只有网络。
说到性能的话,爬虫和性能基本不搭边,是不用考虑的事情。
在我开爬虫的时候,将近30Mbps的爬取效率下,用PHP Command
Line做的爬虫,CPU占用也不过3-5%,内存消耗大概15-20MiB(Core 2 Duo
P8700——有些历史的老U了,爬虫是50线程,每个线程含10个正则提取、1个JSON解析、2个数据库Insert操作 (百万级别数据的IF
NOT EXIST )、40个左右的各种异常判断)——瓶颈应该只有网络。
在你没G口的情况下,不用管什么性能,随便挑一个都一样,自己熟悉的就好。
 我开爬虫那几天,大概爬了270GiB左右的数据。
我开爬虫那几天,大概爬了270GiB左右的数据。
PHP写爬虫还好,我写过一个,用PHP Command Line下运行。用Curl_multi 50线程并发,一天能抓大概60万页,依网速而定,我是用的校园网所以比较快,数据是用正则提取出来的。
Curl是比较成熟的一个lib,异常处理、http header、POST之类都做得很好,重要的是PHP下操作MySQL进行入库操作比较省心。
不过在多线程Curl(Curl_multi)方面,对于初学者会比较麻烦,特别是PHP官方文档在Curl_multi这方面的介绍也极为模糊。
Python写爬虫一个最大的好处是比较傻瓜,Requests之类的lib功能上和Curl相当,但是如果只是做简单的爬虫,易用性比较好,而且有Beautiful Soup这样的傻瓜lib,确实是非常适合用来做爬虫。
不过编码可能的确是个令初学者头疼的问题,我觉得PHP可能还更好一点,事实上如果不是团队要求,我自己做着玩的爬虫,我都是用PHP写的。
JavaScript我觉得像一个在虚拟机里的虚拟机,抛开性能不谈。我是没见过有人拿这个写爬虫的。
- 它首先是在一个沙箱里跑的,对于操作数据库或者本地文件,会比较麻烦,没有原生接口,我因为没用过这个做爬虫,也没去研究过有什么其他方案。
- 对于DOM树的解析,除了效率比较低下,内存占用也比较大。
- 跨域的话,虽然在Chrome下可以通过 --disable-web-security来禁用,不过也是一件麻烦事。
- 总之JS要写爬虫,麻烦事是一大堆。
Node.js 我是真的没有用过。
1.对页面的解析能力基本没区别,大家都支持正则,不过Python有些傻瓜拓展,用起来会方便很多;
2.对数据库的操作能力的话,PHP对MySQL有原生支持,Python需要添加MySQLdb之类的lib,不过也不算麻烦;
3.爬取效率的话,都支持多线程,效率我倒是没感觉有什么区别,基本上瓶颈只在网络上了。不过严谨的测试我没做过,毕竟我没有用多种语言实现同一种功能的习惯,不过我倒是感觉PHP好像还要快一些?
4.代码量的话,爬虫这种简单的东西基本没什么区别,几十行的事,如果加上异常处理也就百来行,或者麻烦点异常的Mark下来,等下重爬等等的处理,也就几百行,大家都没什么区别。
不过Python如果不把lib算进去的话显然是最少的。
说到性能的话,爬虫和性能基本不搭边,是不用考虑的事情。
在我开爬虫的时候,将近30Mbps的爬取效率下,用PHP Command
Line做的爬虫,CPU占用也不过3-5%,内存消耗大概15-20MiB(Core 2 Duo
P8700——有些历史的老U了,爬虫是50线程,每个线程含10个正则提取、1个JSON解析、2个数据库Insert操作 (百万级别数据的IF
NOT EXIST )、40个左右的各种异常判断)——瓶颈应该只有网络。在你没G口的情况下,不用管什么性能,随便挑一个都一样,自己熟悉的就好。
我开爬虫那几天,大概爬了270GiB左右的数据。
 知乎用户,高等弱智 http://ylsc633.com
知乎用户,高等弱智 http://ylsc633.com
用php里的curl抓取手机验证码平台里的号码
利用curl 爬取草liu 页面,并且自动下载图片
嗯,我喜欢草榴,python我还在看,个人觉得,python确实很强大,nodejs以后一定会看,
哦,php不支持多线程,所以只能利用服务器或者扩展来做,mab,我又不会了.........
算了,看会草榴去...
利用curl 爬取草liu 页面,并且自动下载图片
嗯,我喜欢草榴,python我还在看,个人觉得,python确实很强大,nodejs以后一定会看,
哦,php不支持多线程,所以只能利用服务器或者扩展来做,mab,我又不会了.........
算了,看会草榴去...
python
你列的其他3个,适合的应用场景都不对。
你列的其他3个,适合的应用场景都不对。

果断python,c++也ok

python更适宜写spider

明显是python。。。
这3个我都用过,差别非常明显。
python>node.js>php
这3个我都用过,差别非常明显。
python>node.js>php
Colliot
赞同
scala,java,爬ebay,一台机器并发量3000/s

python中scrapy,非常好用的一个爬虫框架

Colliot
赞同
没人用Java吗?……
知乎用户
go语言,而且有现成的项目

知乎用户
赞同
现在写爬虫的话应该一般都是用python 的,因为python 用起来太方便啦。而且还有那么多好用的工具可以安装,代码量非常少,但是功能却十分强大,一般用python 抓网页的话,我使用的是
requests 来发送请求获取数据,用beautiulSoap来分析DOM结构。
我的一个导购网站上面的信息就是用python 抓取的别的网站, 好货啦 http://haohuola.com
requests 来发送请求获取数据,用beautiulSoap来分析DOM结构。
我的一个导购网站上面的信息就是用python 抓取的别的网站, 好货啦 http://haohuola.com

python urllib beautsoup gevent 做过优酷视频爬取

虽然我没写过perl,但是我很多朋友都用这个进行抓取
我来回答这个问题
写回答…