HttpWatch概述
HttpWatch是IE和Firefox浏览器上的一款插件工具,用来捕获浏览过程中所产生的数据信息,并记录其相关日志文件。虽然HttpWatch 能通过手动来控制运行,但很多时候为了提高效率,对于一些重复执行的任务,比如性能测试需要自动化来完成,这样就可以使用HttpWatch来配合自动化 测试性能来自动获取其相关数据信息,从而使得HttpWatch也能自动化进行操作。因此为了更好的配合自动化测试,HttpWatch插件专门提供自动 化接口类程序,以便外部程序来自动化获取其已经存在的数据信息。HttpWatch中提供了大约三十种以上的自动化接口,但只有四个主要的类用于控制 HttpWatch插件。
下图就是描述了这个四个类与浏览器之间的关系:
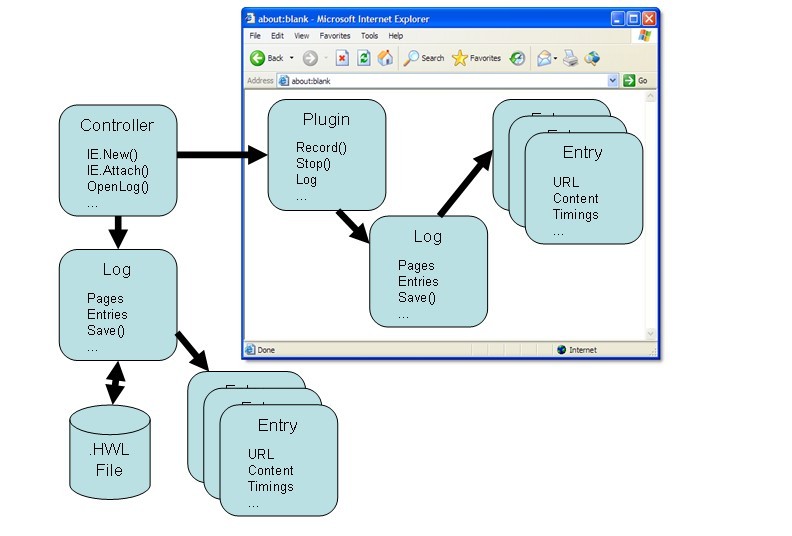
四个主要的自动化接口类分别如下描述:
控制类(Controller Class)
HttpWatch的控制出发点就是控制类,一个自动化客户端使用它来创建一个HttpWatch插件实例,或者是打开一个已经存在的实例文件。
插件类(Plugin Class)
HttpWatch分别为IE和Firefox提供了插件类,它主要是针对Http协议交互提供启动和停止方法去控制 HttpWatch的录制功能,另外还提供了一些方法和属性去管理和配置自动化录制方式。其中插件类中的“GotoURL”方法可以用于重定向浏览任何指 定的URL地址。另外一些属性则是为了说明客户端中哪些网页是否已经加载完成,哪些请求是否是当前的录制请求。日志中的属性信息可以说明录制请求是否已经 达到录制的标准。
日志类(Log Class)
通过插件去访问日志对象,获取日志信息,这些日志信息就是HttpWatch录制过程记录的请求和响应信息。日志类提供了许多 属性和方法,并且允许对这些录制的数据信息进行检索和保存,或者以多种格式导出等等。另外,可以通过这个控制类的一个“OpenLog”方法打开一个日志 文件,并且返回这个日志文件的相应的说明信息,这个说明信息包括的就是录制过中的请求和响应文件信息。
属性类(Entry Class)
每个日志文件都包含一个属性列表,且这个属性列表中包括详细的HTTP交互信息。这些内容具体包括请求的资源信息和一些返回的信息。这个请求和响应属性信息提供了访问头文件和Cookies文件,这些信息都是在与服务器发生交互过程中产生的。
Ruby自动化控制HttpWatch
首先,在httpwatch中调用Ruby,必须要安装ruby工具包
其次通过Ruby去访问httpwatch需要调用ruby的相关库文件,httpwatch自动化库中已经包含了一个com组建,为了使用ruby去访问它就需要引入“win32ole”库文件,通常在代码中添加以下声明即可:
Require ‘win32ole’
第三,关于与httpwatch插件的交互
需要先创建一个控制类,通过控制类来创建它的实例。通过httpwatch接口直接创建控制类如下:
controller = WIN32OLE.new('HttpWatch.Controller')
接下来就是需要去创建一个浏览器的实例对象,这个浏览器的实例对象包括IE和Firefox两种,且分别对这两种类型浏览器都 给予支持。而这两种对象都有两个方法为:New和Attach。这个New方法是用来创建一个新的实例,这个新的实例类型必须与这个浏览器对象中插件类型 想一致。而Attach方法则表示可以创建一个新的实例并且可以嵌入已经创建过的另外一些组件。两种方法均返回的是httpwatch插件对象。
下面这段代码表示创建一个新的IE实例,并嵌入了httpwatch插件组件:
controller = WIN32OLE.new('HttpWatch.Controller')
plugin = controller.IE.New()
关于Firefox的新实例和组件如下:
controller = WIN32OLE.new('HttpWatch.Controller')
plugin = controller.Firefox.New()
关于Attach方法在IE和Firefox浏览器实例中使用是不同的,IE实例需要依赖IE IWebBrowser2接口,如下所示代码段:
ieBrowser = WIN32OLE.new('InternetExplorer.Application')
ieBrowser.Visible = true # Required to see the new window
control = WIN32OLE.new('HttpWatch.Controller')
plugin = controller.IE.Attach(ieBrowser)
相比IE,Firefox需要配置文件名才能运行实例,如下:
controller = WIN32OLE.new('HttpWatch.Controller')
plugin = controller.Firefox.Attach('FirefoxProfileName')
所有的返回对象都是插件对象类型,且能被控制类所调用。
录制
首先你的浏览器实例中必须嵌入HttpWatch插件,这个时候你的应用程序将包含控制类和插件对 象。一般情况下,我们在使用httpwatch进行录制之前需要配置很多功能,此时说到是过滤器,过滤器一般用于精确查找我们想要的信息,从而去掉那些不 需要的信息。然后一般在没有特定需求和目标的时候,将默认关闭过滤器设置。代码段如下:
plugin.Log.EnableFilter(false)
在录制之前需要清空httpwatch的日志信息和浏览器的缓存信息。代码段如下:
plugin.Clear()
接下来我们可以开始录制了,代码段如下:
plugin.Record()
当页面发生加载产生http协议流量信息时,此时录制机制才会记录这些过程。关于如何驱动浏览器进行页面加载,有如下三种方法:
1、通过浏览器自身的接口来驱动,如IE中的IWebBrowser2
2、通过设计框架来驱动,如Watir、WatiN等
3、调用插件对象自身的方法”GotoURL”
通常我们使用第三中方法,因为它是插件的内置方法,可以方便测试网页加载的正确性和度量页面的性能。而且该方法可以很好的控制由于页面加载而导致的连接超时等问题,如下代码段:
myUrl = 'http://www.example.com'
plugin.GotoUrl( myUrl )
control.Wait( plugin, -1 ) # don't return until the page loads
录制完页面请求过程之后就需要停止录制,就需要调用插件对象的stop方法了,并且还要关闭浏览器,调用插件对象的CloseBrowser方法。
Watir驱动浏览器
关于Watir的下载和安装请详细见《自动化测试框架设计理解文档V3.0》。
通过watir来调用httpwatch插件需要引入watir库文件,代码段如下:
require 'win32ole'
require 'watir'
# Open the IE browser using Watir
ie = Watir::IE.new
# Attach HttpWatch
control = WIN32OLE.new('HttpWatch.Controller')
plugin = control.Attach(ie.ie)
# Start recording
plugin.Record()
保存日志文件
当录制运行完之后,需要保存当前的运行日志,代码段如下:
plugin.Log.Save('c:\\mylogfiles\\mylogfile.hwl')
打开日志文件
当需要访问日志的时候,就需要调用插件对象中的方法OpenLog,代码段如下:
# You always need to create an instance of Controller to use the HttpWatch Automation
controller = WIN32OLE.new('HttpWatch.Controller')
# Open the log file and keep a reference to the returned Log object
log = controller.OpenLog("c:\\temp\\test.hwl")
# Access the data in the log file using properties of the log object
printf "The log file contains %d entries", log.Entries.Count