相信每一个刚刚入门神经网络(现在叫深度学习)的同学都一定在反向传播的梯度推导那里被折磨了半天。在各种机器学习的课上明明听得非常明白,神经网络无非就是正向算一遍Loss,反向算一下每个参数的梯度,然后大家按照梯度更新就好了。问题是梯度到底怎么求呢?课上往往举的是标量的例子,可是一到你做作业的时候就发现所有的东西都是vectorized的,一个一个都是矩阵。矩阵的微分操作大部分人都是不熟悉的,结果使得很多人在梯度的推导这里直接选择死亡。我曾经就是其中的一员,做CS231n的Assignment 1里面那几个简单的小导数都搞得让我怀疑人生。
我相信很多人都看了不少资料,比如CS231n的讲师Karpathy推荐的这一篇矩阵求导指南http://cs231n.stanford.edu/vecDerivs.pdf,但是经过了几天的折磨以后,我发现事实上根本就不需要去学习这些东西。在神经网络中正确计算梯度其实非常简单,只需要把握好下面的两条原则即可。这两条原则非常适合对矩阵微分不熟悉的同学,虽然看起来并不严谨,但是有效。
1. 用好维度分析,不要直接求导
神经网络中求梯度,第一原则是:如果你对矩阵微分不熟悉,那么永远不要直接计算一个矩阵对另一个矩阵的导数。我们很快就可以看到,在神经网络中,所有的矩阵对矩阵的导数都是可以通过间接的方法,利用求标量导数的那些知识轻松求出来的。而这种间接求导数的方法就是维度分析。我认为维度分析是神经网络中求取梯度最好用的技巧,没有之一。用好维度分析,你就不用一个一个地去分析矩阵当中每个元素究竟是对谁怎么求导的,各种求和完了以后是左乘还是右乘,到底该不该转置等等破事,简直好用的不能再好用了。这一技巧在Karpathy的Course Note上也提到了一点。
什么叫维度分析?举一个最简单的例子。设某一层的Forward Pass为,X是NxD的矩阵,W是DxC的矩阵,b是1xC的矩阵,那么score就是一个NxC的矩阵。现在上层已经告诉你L对score的导数是多少了,我们求L对W和b的导数。
我们已经知道一定是一个NxC的矩阵(因为Loss是一个标量,score的每一个元素变化,Loss也会随之变化),那么就有
现在问题来了,score是一个矩阵,W也是个矩阵,矩阵对矩阵求导,怎么求啊?如果你对矩阵微分不熟悉的话,到这里就直接懵逼了。于是很多同学都出门右转去学习矩阵微分到底怎么搞,看到那满篇的推导过程就感到一阵恶心,之后就提前走完了从入门到放弃,从深度学习到深度厌学的整个过程。
其实我们没有必要直接求score对W的导数,我们可以利用另外两个导数间接地把算出来。首先看看它是多大的。我们知道
一定是DxC的(和W一样大),而
是NxC的,哦那你瞬间就发现了
一定是DxN的,因为(DxN)x(NxC)=>(DxC),并且你还发现你随手写的这个式子右边两项写反了,应该是
。
那好,我们已经知道了是DxN的,那就好办了。既然score=XW+b,如果都是标量的话,score对W求导,本身就是X;X是NxD的,我们要DxN的,那就转置一下呗,于是我们就得出了:
完事了。
你看,我们并没有直接去用诸如这种细枝末节的一个一个元素求导的方式推导
,而是利用
再加上熟悉的标量求导的知识,就把这个矩阵求导给算出来了。这就是神经网络中求取导数的正确姿势。
为什么这一招总是有效呢?这里的关键点在于Loss是一个标量,而标量对一个矩阵求导,其大小和这个矩阵的大小永远是一样的。那么,在神经网络里,你永远都可以执行这个“知二求一”的过程,其中的“二”就是两个Loss对参数的导数,另一个是你不会求的矩阵对矩阵的导数。首先把你没法直接求的矩阵导数的大小给计算出来,然后利用你熟悉的标量求导的方法大概看看导数长什么样子,最后凑出那个目标大小的矩阵来就好了。
那呢?我们来看看,
是NxC的,
是1xC的,
看起来像1,那聪明的你肯定想到
其实就是1xN个1了,因为(1xN)x(NxC)=>(1xC)。其实这也就等价于直接对d_score的第一维求个和,把N降低成1而已。
多说一句,这个求和是怎么来的?原因实际上在于所谓的“广播”机制。你会发现,XW是一个NxC的矩阵,但是b只是一个1xC的矩阵,按理说,这俩矩阵形状不一样,是不能相加的。但是我们都知道,实际上我们想做的事情是让XW的每一行都加上b。也就是说,我们把b的第一维复制了N份,强行变成了一个NxC的矩阵,然后加在了XW上(当然这件事实际上是numpy帮你做的)。那么,当你要回来求梯度的时候,既然每一个b都参与了N行的运算,那就要把每一份的梯度全都加起来求个和的。因为求导法则告诉我们,如果一个变量参与了多个运算,那就要把它们的导数加起来。这里借用一下
的图,相信大家可以看得更明白。
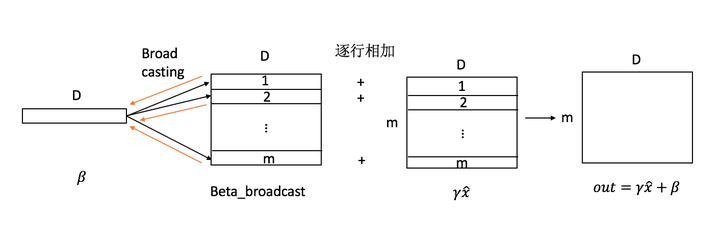
总之,不要试图在神经网络里面直接求矩阵对矩阵的导数,而要用维度分析间接求,这样可以为你省下很多不必要的麻烦。
2. 用好链式法则,不要一步到位
我曾经觉得链式法则简直就是把简单的问题搞复杂,复合函数求导这种东西高考的时候我们就都会了,还用得着一步一步地往下拆?比如,我一眼就能看出来
,还用得着先把
当成一个中间函数么?
不幸的是,在神经网络里面,你会发现事情没那么容易。上面的这些推导只在标量下成立,如果w,x和b都是矩阵的话,我们很容易就感到无从下笔。还举上面这个例子,设,我们要求
,那么我们直接就可以写出
L对H的导数,是反向传播当中上一层会告诉你的,但问题是H对W的导数怎么求呢?
如果你学会了刚才的维度分析法,那么你可能会觉得是一个DxN的矩阵。然后就会发现没有任何招可以用了。事实上,卡壳的原因在于,
根本不是一个矩阵,而是一个4维的tensor。对这个鬼玩意的运算初学者是搞不定的。准确的讲,它也可以表示成一个矩阵,但是它的大小并不是DxN,而且它和
的运算也不是简单的矩阵乘法,会有向量化等等的过程。有兴趣的同学可以参考这篇文章,里面有一个例子讲解了如何直接求这个导数:矩阵求导术(下)。
这是一个刚学完反向传播的初学者很容易踩到的陷阱:试图不设中间变量,直接就把目标参数的梯度给求出来。如果这么去做的话,很容易在中间碰到这种非矩阵的结构,因为理论上矩阵对矩阵求导求出来是一个4维tensor,不是我们熟悉的二维矩阵。除非你完全掌握了上面那篇reference当中的数学技巧,不然你就只能干瞪眼了。
但是,如果你不直接求取对W的导数,而把当做一个中间变量的话,事情就简单的多了。因为如果每一步求导都只是一个简单二元运算的话,那么即使是矩阵对矩阵求导,求出来也仍然是一个矩阵,这样我们就可以用维度分析法往下做了。
设,则有
利用维度分析:dS是NxC的,dH是NxC的,考虑到,那么容易想到
也是NxC的,也就是
,这是一个element-wise的相乘;所以
;
再求,用上一部分的方法,很容易求得
,所以就求完了。
有了这些结果,我们不妨回头看看一开始的那个式子:,如果你错误地认为
是一个DxN的矩阵的话,再往下运算:
我们已经知道,这两个矩阵一个是NxC的,一个是DxN的,无论怎么相乘,也得不出DxN的矩阵。矛盾就是出在H对W的导数其实并不是一个矩阵。但是如果使用链式法则运算的话,我们就可以避开这个复杂的tensor,只使用矩阵运算和标量求导就搞定神经网络中的梯度推导。
借助这两个技巧,已经足以计算任何复杂的层的梯度。下面我们来实战一个:求Softmax层的梯度。
Softmax层往往是输出层,其Forward Pass公式为:
,
,
假设输入X是NxD的,总共有C类,那么W显然应该是DxC的,b是1xC的。其中就是第i个样本预测的其正确class的概率。关于softmax的知识在这里就不多说了。我们来求Loss关于W, X和b的导数。为了简便起见,下面所有的d_xxx指的都是Loss对xxx的导数。
我们首先把Loss重新写一下,把P代入进去:
不要一步到位,我们把前面一部分和后面一部分分开看。设, rowsum就是每一行的score指数和,因此是Nx1的,那么就有
先看d_score,其大小与score一样,是NxC的。你会发现如果扔掉前面的1/N不看,d_score其实就是一堆0,然后在每一行那个正确的class那里为-1;写成python代码就是
d_score = np.zeros_like(score)
d_score[range(N),y] -= 1然后看d_rowsum,其实就是,非常简单。
现在我们关注,需要注意的是我们不要直接求
是什么,两个都是矩阵,不好求;相反,我们求
是多少。我们会发现上面我们求了一个d_score,这里又求了一个d_score,这说明score这个矩阵参与了两个运算,这是符合这里Loss的定义的。求导法则告诉我们,当一个变量参与了两部分运算的时候,把这两部分的导数加起来就可以了。
这一部分的d_score就很好求了:
,左边是NxC的,右边已知的是Nx1的,那么剩下的有可能是1xC的,也有可能是NxC的。这个时候就要分析一下了。我们会发现右边应该是NxC的,因为每一个score都只影响一个rowsum的元素,因此我们不应该求和。NxC的矩阵就是
自己,所以我们就很容易得出:
# 实际上,d_rowsum往往是一个长度为N的一位数组,因此我们先用np.newaxis把它的shape由N升维到Nx1,
# 这样就可以使用广播机制(Nx1 * NxC)
# 然后用乘号做element wise相乘。
d_score += d_rowsum[:, np.newaxis] * (np.exp(score))
d_score /= N #再把那个1/N给补上这样我们就完成了对score的求导,之后score对W, X和b的求导,相信你也就会了。
当然,如果你注意一下的话,你会发现其实第二部分的那个式子就是P矩阵。不过如果你没有注意到这一点也无所谓,用这套方法也可以求出d_score是多少。
利用同样的方法,现在看看那个卡住无数人的Batch Normalization层的梯度推导,是不是也感到不那么困难了?
希望本文可以为刚刚入门神经网络的同学提供一些帮助,如有错漏欢迎指出。
谢谢!