View Code
View Code

1 #!/usr/bin/env python 2 #coding=utf-8 3 import urllib 4 import re 5 def gethtml(url): 6 page = urllib.urlopen(url) 7 html = page.read() 8 page.close() 9 return html 10 def getweather(html): 11 reg = '<a title=.*?>(.*?)</a>.*?<span>(.*?)</span>.*?<b>(.*?)</b>' 12 weatherlist = re.compile(reg).findall(html) 13 return weatherlist 14 getml = gethtml('http://sd.weather.com.cn/index.shtml') 15 list_all = getweather(getml) 16 for i in list_all: 17 print i[0],i[1],i[2] 18 # for item in i: 19 # print item
代码很简单没什么好说的,主要就是正则匹配和乱码问题。
抓下来的页面是utf-8的 但是由于findall返回的是列表 如果直接输出列表 列表中有字符串的话会有乱码。
试过先转unicode再转gb2312也不可以。i.decode(‘utf-8′).encode(‘gb2312′)
单个输出就没问题了。
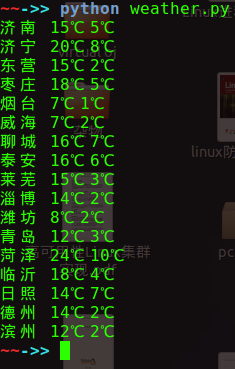
运行截图