OkHttp是Android中包含的功能强大的HTTP客户端,此框架平时用的还挺多的,但是今天的主角是OkHttp的低层IO库——Okio,Okio是对java.io和java.nio的补充,使访问、存储和处理数据变得更加容易。 这里是它的官网:https://square.github.io/okio/ , 最开始它作为OKHttp的一个组件,现在可以独立使用它来解决一些IO问题,接下来的内容来自对Okio官网的文档以及一些代码示例。
ByteString与Buffer
Okio是围绕这两种类型构建的,它们将大量功能集成到了简单的API中:
ByteString 是一个不可变的字节序列,String的基础是字符,而ByteString就像是String的兄弟一样,它可以轻松将二进制数据视为某些值。这个类非常聪明:它知道如何对自己进行十六进制,base64和UTF-8编码和解码。
Buffer 是可变的字节序列。与ArrayList一样,无需预先设置缓冲区大小。以队列的方式读取和写入缓冲区:将数据写入末尾,然后从队列头部读取。没有必要去管理读取位置,范围或容量。
在内部,ByteString和Buffer做一些巧妙的事情来节省CPU和内存。 如果将UTF-8字符串编码为ByteString,它会缓存对该字符串的引用,以便以后进行解码时无需做任何工作。
缓冲区被实现为段的链表。当您将数据从一个缓冲区移到另一个缓冲区时,它会重新分配段的所有权,而不是跨缓冲区复制数据。这种方法对多线程程序特别有用:与网络请求相关的线程可以与工作线程交换数据,而无需任何复制或多余的操作。
Source与Sink
java.io中的一个优雅的设计是如何对流进行分层来处理加密和压缩等转换。同样的Okio有自己的stream类型:Source和Sink,分别类似于java的Inputstream和Outputstream,但是有一些关键区别:
- 超时(Timeout):流提供了对底层I/O超时机制的访问。与java.io的socket字节流不同,read()和write()方法都给予超时机制。
- 实现简单: Source只声明了三个方法:read()、close()和timeout()。没有像available()或单字节读取这样会导致性能下降问题。
- 使用方便:虽然source和sink中只有三个方法需要实现,但是调用方可以实现Bufferedsource和Bufferedsink接口,这两个接口提供了丰富API能够满足你所需要的一切。
- 字节流和字符流的处理没有直观的区别:因为它们都是数据。你可以以字节、UTF-8字符串、big-endian的32位整数、little-endian的短整数等任何你想要的形式进行读写;再也不需要InputStreamReader!
- 测试简单: Buffer类同时实现了BufferedSource和BufferedSink,因此测试代码简单明了。
Sources 和 Sinks分别与InputStream和OutputStream交互操作。你可以将任何Source看做InputStream ,也可以将任何InputStream当做Source。对于Sink和Outputstream也是如此。
Okio的使用示例
这是它的Maven方式依赖:
<dependency>
<groupId>com.squareup.okio</groupId>
<artifactId>okio</artifactId>
<version>2.9.0</version>
</dependency>
1、逐行读取文本
public void readLines(File file) throws IOException {
try (Source fileSource = Okio.source(file);
BufferedSource bufferedSource = Okio.buffer(fileSource)) {
while (true) {
String line = bufferedSource.readUtf8Line();
if (line == null) break;
System.out.println(line);
}
}
}
其中readUtf8Line()这个API读取所有数据,直到下一行分隔符 、 或文件末尾。它以字符串形式返回该数据,并在最后省略定界符。当遇到空行时,该方法将返回一个空字符串。 如果没有更多要读取的数据,它将返回null,所以使用for来代替while(true)也是OK的,这样的写法会让程序更加紧凑:
public void readLines(File file) throws IOException {
try (BufferedSource source = Okio.buffer(Okio.source(file))) {
for (String line; (line = source.readUtf8Line()) != null; ) {
System.out.println(line);
}
}
}
2、将字符串写入文本文件
上面我们使用了Source和BufferedSource来读取文件。在写入文件时,我们使用一个Sink和一个BufferedSink。他们有着异曲同工之处:功能更强大的API和更高的性能。
public void writeToFile(File file) throws IOException {
try (Sink fileSink = Okio.sink(file);
BufferedSink bufferedSink = Okio.buffer(fileSink)) {
bufferedSink.writeUtf8("Hello");
bufferedSink.writeUtf8("
");
bufferedSink.writeAll(Okio.source(new File("my.txt")));
}
}
3、UTF-8编码
在以上API中,可以看到Okio非常喜欢UTF-8。早期的计算机系统遇到了许多不兼容的字符编码:ISO-8859-1,ASCII,EBCDIC等。编写支持多种字符集的软件太糟糕了,我们甚至没有表情符号!今天,我们很幸运,全世界各地都已经在UTF-8上实现了标准化,而在遗留系统中很少使用其他字符集。
如果你需要其他字符集,则可以使用readString()和writeString()。 这些方法要求传入指定字符集的参数。 否则,可能会意外地创建只能由本地计算机读取的数据,大多数程序应该仅使用writeUtf8()这类方法。
尽管每当我们在I/O中读写字符串时都使用UTF-8,但当它们在内存中时,Java字符串会使用过时的字符编码UTF-16。这是一种错误的编码方式,因为它对大多数字符使用16位字符,但有些字符不合适。 特别是,大多数表情符号使用两个Java字符。这是有问题的,因为String.length()返回一个令人惊讶的结果:UTF-16字符数而不是字体原本的字符数量:
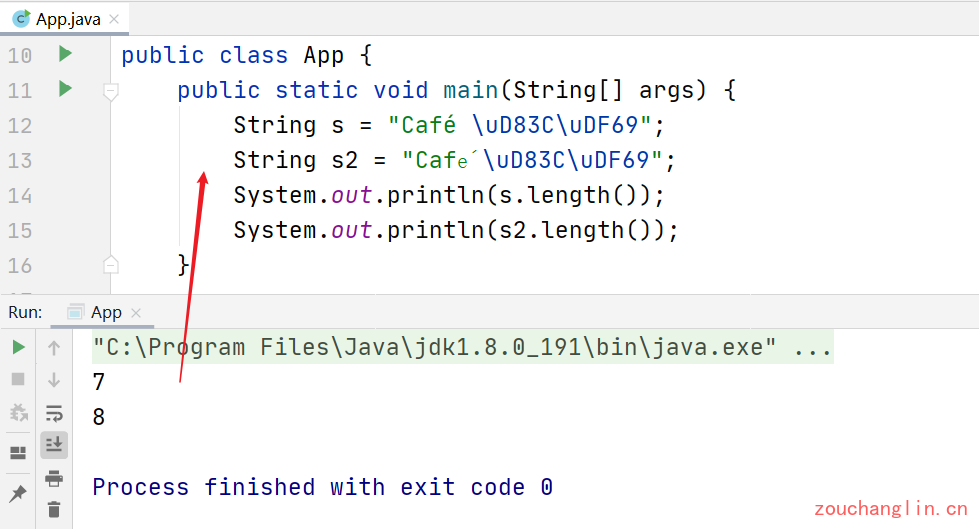
String s1 = "Café uD83CuDF69";
String s2 = "Café uD83CuDF69";
System.out.println(s.length());
System.out.println(s2.length());
在大多数情况下,Okio可以让你忽略这些问题并专注于数据。但是当你需要它们时,可以使用方便的API处理低级UTF-8字符串。使用Utf8.size()来计算将字符串编码为UTF-8所需的字节数(但是并不会真正去做一次编码操作)。这在诸如协议缓冲区中处理固定长度前缀的时候非常方便。
使用BufferedSource.readUtf8CodePoint()读取一个Codepoint,并使BufferedSink.writeUtf8CodePoint()写入一个Codepoint。
4、序列化和反序列化
Okio喜欢测试。该库本身已经过严格的测试,我们发现一种非常有用的模式是"黄金价值"测试,此类测试的目的是确认当前程序可以安全地解码使用程序的早期版本编码的数据。
我们将通过使用Java序列化对值进行编码来说明这一点。尽管我们必须否认Java序列化是一个糟糕的编码系统,并且大多数程序应该更喜欢JSON或protobuf之类的其他格式!无论如何,这是一个获取对象,对其进行序列化并以ByteString返回结果的方法:
private ByteString serialize(Object o) throws IOException {
Buffer buffer = new Buffer();
try (ObjectOutputStream objectOut = new ObjectOutputStream(buffer.outputStream())) {
objectOut.writeObject(o);
}
return buffer.readByteString();
}
这里使用Buffer对象代替Java的ByteArrayOutputstream,然后从buffer中获得输出流对象,并通过ObjectOutputStream写入对象到buffer缓冲区当中,当你向Buffer中写数据时,总是会写到缓冲区的末尾。最后,通过buffer对象的readByteString()从缓冲区读取一个ByteString对象,这会从缓冲区的头部开始读取,readByteString()方法可以指定要读取的字节数,如果不指定,则读取全部内容。
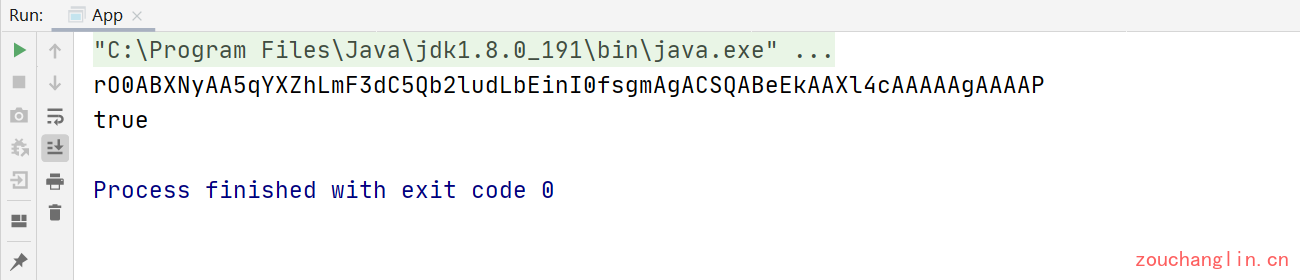
我们利用上面的方法将一个对象进行序列化,并得到的ByteString对象按照base64格式进行输出:
Point point = new Point(8, 15);
ByteString pointBytes = serialize(point);
System.out.println(pointBytes.base64());
rO0ABXNyAA5qYXZhLmF3dC5Qb2ludLbEinI0fsgmAgACSQABeEkAAXl4cAAAAAgAAAAP
Okio将这个字符串称之为Golden Value,接下来,我们尝试将这个字符串(Golden Value)反序列化为一个Point对象,首先转回ByteString对象:
public static void main(String[] args) throws Exception {
Point point = new Point(8, 15);
ByteString pointBytes = new App().serialize(point);
String base64 = pointBytes.base64();
System.out.println(base64);
ByteString byteString = ByteString.decodeBase64(base64);
Point other = (Point) new App().deserialize(byteString);
System.out.println(other.equals(point)); // true
}
private Object deserialize(ByteString byteString) throws IOException, ClassNotFoundException {
Buffer buffer = new Buffer();
buffer.write(byteString);
try (ObjectInputStream objectIn = new ObjectInputStream(buffer.inputStream())) {
Object result = objectIn.readObject();
if (objectIn.read() != -1) throw new IOException("Unconsumed bytes in stream");
return result;
}
}
private ByteString serialize(Object o) throws IOException {
Buffer buffer = new Buffer();
try (ObjectOutputStream objectOut = new ObjectOutputStream(buffer.outputStream())) {
objectOut.writeObject(o);
}
return buffer.readByteString();
}
这样我们可以在不破坏兼容性的情况下更改对象的序列化方式。
这个序列化与Java原生的序列化有一个明显的区别就是GodenValue可以在不同客户端之间兼容(只要序列化和反序列化的Class是相同的)。什么意思呢,比如我在PC端使用Okio序列化一个User对象生成的GodenValue字符串,这个字符串你拿到手机端照样可以反序列化出来User对象。
5、将字节流写入文件
编码二进制文件与编码文本文件没有什么不同。Okio使用相同的BufferedSink和BufferedSource字节。这对于同时包含字节和字符数据的二进制格式非常方便。写入二进制数据比写入文本更危险,因为如果你犯了错误,通常很难诊断,避免这样的错误需要注意以下几点:
- 每个字段的宽度:即字节的数量。Okio没有释放部分字节的机制。如果你需要的话,需要自己在写操作之前对字节进行shift和mask运算。
- 每个字段的字节序:所有多字节的字段都具有结束符:字节的顺序是从最高位到最低位(大字节 big endian),还是从最低位到最高位(小字节 little endian)。Okio中针对小字节排序的方法都带有Le的后缀;而没有后缀的方法默认是大字节排序的。
- 有符号和无符号: Java没有无符号的基础类型(除了char!)因此,在应用程序层经常会遇到这种情况。为方便使用,Okio的writeByte() 和 writeShort()方法可以接受int类型。你可以直接传递一个无符号字节像255,Okio会做正确的处理。
| 方法 | 宽度 | 字节排序 | 值 | 编码后的值 |
|---|---|---|---|---|
| writeByte | 1 | 3 | 03 |
|
| writeShort | 2 | big | 3 | 00 03 |
| writeInt | 4 | big | 3 | 00 00 00 03 |
| writeLong | 8 | big | 3 | 00 00 00 00 00 00 00 03 |
| writeShortLe | 2 | little | 3 | 03 00 |
| writeIntLe | 4 | little | 3 | 03 00 00 00 |
| writeLongLe | 8 | little | 3 | 03 00 00 00 00 00 00 00 |
| writeByte | 1 | Byte.MAX_VALUE | 7f |
|
| writeShort | 2 | big | Short.MAX_VALUE | 7f ff |
| writeInt | 4 | big | Int.MAX_VALUE | 7f ff ff ff |
| writeLong | 8 | big | Long.MAX_VALUE | 7f ff ff ff ff ff ff ff |
| writeShortLe | 2 | little | Short.MAX_VALUE | ff 7f |
| writeIntLe | 4 | little | Int.MAX_VALUE | ff ff ff 7f |
| writeLongLe | 8 | little | Long.MAX_VALUE | ff ff ff ff ff ff ff 7f |
下面的示例代码是按照 BMP文件格式 对文件进行编码:
void encode(Bitmap bitmap, BufferedSink sink) throws IOException {
int height = bitmap.height();
int width = bitmap.width();
int bytesPerPixel = 3;
int rowByteCountWithoutPadding = (bytesPerPixel * width);
int rowByteCount = ((rowByteCountWithoutPadding + 3) / 4) * 4;
int pixelDataSize = rowByteCount * height;
int bmpHeaderSize = 14;
int dibHeaderSize = 40;
// BMP Header
sink.writeUtf8("BM"); // ID.
sink.writeIntLe(bmpHeaderSize + dibHeaderSize + pixelDataSize); // File size.
sink.writeShortLe(0); // Unused.
sink.writeShortLe(0); // Unused.
sink.writeIntLe(bmpHeaderSize + dibHeaderSize); // Offset of pixel data.
// DIB Header
sink.writeIntLe(dibHeaderSize);
sink.writeIntLe(width);
sink.writeIntLe(height);
sink.writeShortLe(1); // Color plane count.
sink.writeShortLe(bytesPerPixel * Byte.SIZE);
sink.writeIntLe(0); // No compression.
sink.writeIntLe(16); // Size of bitmap data including padding.
sink.writeIntLe(2835); // Horizontal print resolution in pixels/meter. (72 dpi).
sink.writeIntLe(2835); // Vertical print resolution in pixels/meter. (72 dpi).
sink.writeIntLe(0); // Palette color count.
sink.writeIntLe(0); // 0 important colors.
// Pixel data.
for (int y = height - 1; y >= 0; y--) {
for (int x = 0; x < width; x++) {
sink.writeByte(bitmap.blue(x, y));
sink.writeByte(bitmap.green(x, y));
sink.writeByte(bitmap.red(x, y));
}
// Padding for 4-byte alignment.
for (int p = rowByteCountWithoutPadding; p < rowByteCount; p++) {
sink.writeByte(0);
}
}
}
代码中对文件按照BMP的格式写入二进制数据,这会生成一个bmp格式的图片文件,BMP格式要求每行以4字节开始,所以代码中加了很多0来做字节对齐。
编码其他二进制的格式非常相似。一些值得注意的点:
- 使用Golden values编写测试,对于确认程序的预期结果可以使调试更容易。
- 使用
Utf8.size()方法计算编码字符串的字节长度。这对于length-prefixed格式必不可少。 - 使用
Float.floatToIntBits()和Double.doubleToLongBits()来编码浮点型的数值。
6、使用Socket进行通信
通过网络发送和接收数据有点像文件的读写。Okio使用BufferedSink对输出进行编码,使用BufferedSource对输入进行解码。与文件一样,网络协议可以是文本、二进制或两者的混合。但是网络和文件系统之间也有一些实质性的区别。
当你有一个文件对象,你只可以选择读或者写,但是网络与之不同的是可以同时进行读和写!在有一些协议中,处理这个问题的方式是轮流的进行:写入请求、读取响应、重复以上操作。你可以用一个单线程来实现这种协议。而在其他协议中,你可以同时进行读写。通常你需要一个专门的线程来读取数据。对于写入数据,你可以使用专门线程或者使用synchronized,以便多个线程可以共享一个Sink。Okio的流在并发情况下使用是不安全的。
对于Okio的Sinks缓冲区,必须手动调用flush()来传输数据,以最小化I/O操作。通常,面向消息的协议会在每条消息之后刷新。注意,当缓冲数据超过某个阈值时,Okio将自动刷新。但这只是为了节省内存,不能依赖它进行协议交互。
Okio是基于java.io.socket建立连接的,当你通过socket创建服务器或客户端后,可以使用Okio.source(Socket)进行读取,使用Okio.sink(Socket)进行写入,这些API也同样适用于SSLSocket。
在任意线程中想要取消socket连接可以调用Socket.close()方法,这将导致sources 和 sinks 对象立即抛出IOException而失败。Okio中可以为所有的socket操作配置超时限制,但并不需要你去调用Socket的方法来设置超时:Source和Sink会提供超时的接口,即使对流进行了装饰,此API仍然有效。
Okio官方Demo中编写了一个 简单的Socket代理服务 来示例完整的网络交互操作,下面是其中的部分代码截取:
private void handleSocket(final Socket fromSocket) {
try {
final BufferedSource fromSource = Okio.buffer(Okio.source(fromSocket));
final BufferedSink fromSink = Okio.buffer(Okio.sink(fromSocket));
//..............
//..................
} catch (IOException e) {
.....
}
}
可以看到通过Socket创建sources 和 sinks的方式与通过文件创建的方式一样,都是先通过Okio.source()拿到Socket对应的Source或Sink对象,然后通过Okio.buffer()获取对应的装饰者缓冲对象。在Okio中,一旦你为Socket对象创建了Source 或者 Sink,那么你就不能再使用InputStream或OutputStream了。
Buffer buffer = new Buffer();
for (long byteCount; (byteCount = source.read(buffer, 8192L)) != -1; ) {
sink.write(buffer, byteCount);
sink.flush();
}
以上代码中,循环从source中读取数据写入到sink当中,并调用flush()进行刷新,如果你不需要每次写数据都进行flush(),那么for循环里的两句可以使用BufferedSink.writeAll(Source)一行代码来代替。
你会发现,在read()方法中传递了一个8192作为读取的字节数,其实这里可以传任何数字,但是Okio更喜欢用8 kib,因为这是Okio在单个系统调用中所能处理的最大值。大多数时候应用程序代码不需要处理这样的限制!
int addressType = fromSource.readByte() & 0xff;
int port = fromSource.readShort() & 0xffff;
Okio使用的是有符号类型,如byte和short,但通常协议需要的是无符号的值,而在Java中将有符号的值转换为无符号值的首选方式,就是通过是按位与&运算符。以下是字节、短整型和整型的转换清单:
| Type | Signed Range | Unsigned Range | Signed to Unsigned |
|---|---|---|---|
| byte | -128…127 | 0…255 | int u = s & 0xff; |
| short | -32,768…32,767 | 0…65,535 | int u = s & 0xffff; |
| int | -2,147,483,648…2,147,483,647 | 0…4,294,967,295 | long u = s & 0xffffffffL; |
Java中没有能够表示无符号的long型的基本类型。
7、哈希
哈希函数应用广泛,如HTTPS证书、Git提交、BitTorrent完整性检查和区块链块等都使用到加密散列, 良好地使用哈希可以提高应用程序的性能、隐私性、安全性和简单性。每个加密哈希函数接受一个可变长度的字节输入流,并生成一个长度固定的字符串值,称之为哈希值。哈希函数具有以下重要特性:
- 确定性:每个输入总是产生相同的输出。
- 统一:每个输出的字节字符串的可能性相同。很难找到或创建产生相同输出的不同输入对。即“碰撞”。
- 不可逆:知道输出并不能帮助你找到输入。
- 易于理解:哈希在很多环境中都已被实现并且被严格理解。
Okio支持一些常见的哈希函数:
- MD5:128位(16字节)加密哈希。它既不安全又是过时的,因为它的逆向成本很低!之所以提供此哈希,是因为它在安全性较低的系统中使用比较非常流行并且方便。
- SHA-1:160位(20字节)加密散列。最近的研究表明,创建SHA-1碰撞是可行的。考虑从sha-1升级到sha-256。
- SHA-256:256位(32字节)加密哈希。SHA-256被广泛理解,逆向操作成本较高。这是大多数系统应该使用的哈希。
- SHA-512:512位(64字节)加密哈希。逆向操作成本很高。
Okio可以从ByteString中生成加密哈希:
ByteString byteString = readByteString(new File("README.md"));
System.out.println(" md5: " + byteString.md5().hex());
System.out.println(" sha1: " + byteString.sha1().hex());
System.out.println("sha256: " + byteString.sha256().hex());
System.out.println("sha512: " + byteString.sha512().hex());
从Buffer中生成:
Buffer buffer = readBuffer(new File("README.md"));
System.out.println(" md5: " + buffer.md5().hex());
System.out.println(" sha1: " + buffer.sha1().hex());
System.out.println("sha256: " + buffer.sha256().hex());
System.out.println("sha512: " + buffer.sha512().hex());
从Source输入流得到哈希值:
try (HashingSink hashingSink = HashingSink.sha256(Okio.blackhole());
BufferedSource source = Okio.buffer(Okio.source(file))) {
source.readAll(hashingSink);
System.out.println("sha256: " + hashingSink.hash().hex());
}
从Sink输出流得到哈希值:
try (HashingSink hashingSink = HashingSink.sha256(Okio.blackhole());
BufferedSink sink = Okio.buffer(hashingSink);
Source source = Okio.source(file)) {
sink.writeAll(source);
sink.close(); // Emit anything buffered.
System.out.println("sha256: " + hashingSink.hash().hex());
}
Okio还支持HMAC(哈希消息认证代码),它结合了一个秘钥值和一个hash值。应用程序可以使用HMAC进行数据完整性和身份验证:
ByteString secret = ByteString.decodeHex("7065616e7574627574746572");
System.out.println("hmacSha256: " + byteString.hmacSha256(secret).hex());
同样样,你可以从ByteString, Buffer, HashingSource, 和HashingSink生成HMAC。注意,Okio没有为MD5实现HMAC。Okio使用Java的java.security.MessageDigest用于加密散列和javax.crypto.Mac 生成HMAC。
8、加密和解密
使用Okio.cipherSink(Sink,Cipher)或Okio.cipherSource(Source,Cipher)使用区块加密算法对Stream进行加密或解密。调用者负责使用算法,密钥和特定于算法的附加参数(如初始化向量)初始化加密或解密密码。 以下示例显示了AES加密的典型用法,其中key和iv参数都应为16个字节长度:
void encryptAes(ByteString bytes, File file, byte[] key, byte[] iv)
throws GeneralSecurityException, IOException {
Cipher cipher = Cipher.getInstance("AES/CBC/PKCS5Padding");
cipher.init(Cipher.ENCRYPT_MODE, new SecretKeySpec(key, "AES"), new IvParameterSpec(iv));
try (BufferedSink sink = Okio.buffer(Okio.cipherSink(Okio.sink(file), cipher))) {
sink.write(bytes);
}
}
ByteString decryptAesToByteString(File file, byte[] key, byte[] iv)
throws GeneralSecurityException, IOException {
Cipher cipher = Cipher.getInstance("AES/CBC/PKCS5Padding");
cipher.init(Cipher.DECRYPT_MODE, new SecretKeySpec(key, "AES"), new IvParameterSpec(iv));
try (BufferedSource source = Okio.buffer(Okio.cipherSource(Okio.source(file), cipher))) {
return source.readByteString();
}
}
以上就是对OKio官方文档的部分翻译,英文比较好的话可以参考官方文档:《Okio Reference》,关于Okio的具体实现细节等到后面的源码分析文章再详谈。