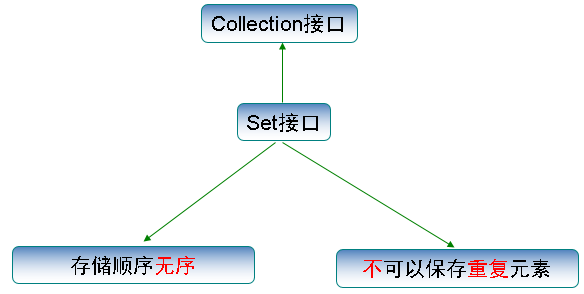
Set·无序,不重复
HashSet
特点:没有重复数据,数据不按存入的顺序输出。
HashSet由Hash表结构支持。不支持set的迭代顺序,不保证顺序。
但是Hash表结构查询速度很快。
创建集合使用代码:
Set<String> s = new HashSet<>();
代码演示:常用方法和遍历输出
import java.util.*;
public class TestHashSet {
public static void main(String[] args) {
m010赋值And遍历();
}
public static void m010赋值And遍历() {
System.out.println("=====赋值And遍历");
Set<String> s = new HashSet<>();
s.add("孙悟空");
s.add("小白龙");
s.add("猪八戒");
s.add("沙悟净");
s.add("孙悟空");
System.out.println("是否为空:" + s.isEmpty());
System.out.println("是否包含:" + s.contains("小白龙"));
System.out.println("移除:" + s.remove("小白龙"));
// (1)foreach:遍历set
for (String str : s) {
System.out.println(str);
}
// (2)迭代器:遍历set
Iterator<String> it = s.iterator();
while (it.hasNext()) {
String str = it.next();
System.out.println("Iterator : " + str);
}
// (3)*Java 8新增遍历方法
s.forEach(elm -> System.out.println("Lambda:" + elm));
}
}
Hash和Hash表
Hash
HashCode,是一个十进制整数,是对象的地址值(逻辑地址,不是物理地址)
Object类有一个方法,可以获取对象的Hash值。
public native int hashCode();
String重写了hashCode方法
public int hashCode() {
int h = hash;
if (h == 0 && value.length > 0) {
char val[] = value;
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}
hash = h;
}
return h;
}
以至于有些不同字符串的hashCode相等(字符串还是不等的,无论==还是equals):
System.out.println("重地".hashCode());
System.out.println("通话".hashCode());
System.out.println("--------------");
System.out.println("方面".hashCode());
System.out.println("树人".hashCode());
System.out.println("--------------");
System.out.println("儿女".hashCode());
System.out.println("农丰".hashCode());
System.out.println("--------------");
System.out.println("Ea".hashCode());
System.out.println("FB".hashCode());
Hash表
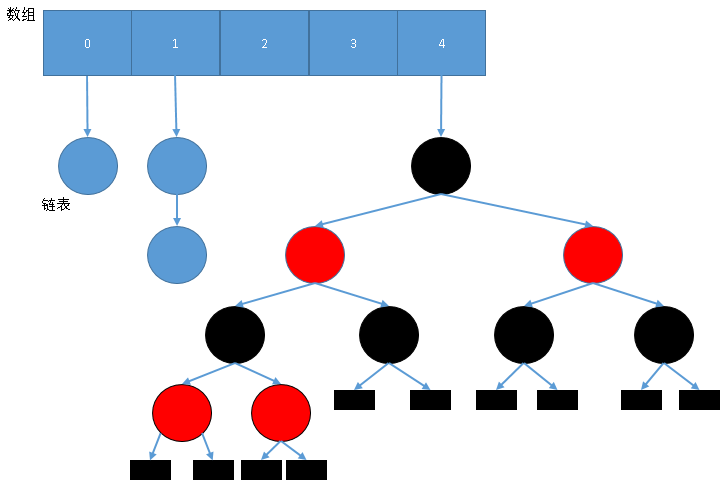
Java8之前:Hash表使用数组+链表;
Java8之后加入了红黑树,查询速度加快。
Hash表结构的示意图如下所示:
数组里存储的是HashCode。
HashCode相同的元素加入相同链表;
如果链表长度超过8,就转为红黑树以提高查询速度。
怎么才算重复?
HashSet中,元素不重复指“equals方法比较为true,且hashCode不同”。
下列示例代码中,只有equals为true、且hashCode相同的对象未重复存入Set中。
import java.util.*;
class A_equalsT {
public boolean equals(Object obj) {
return true;
}
}
class B_hash1 {
public int hashCode() {
return 1;
}
}
class C_hash2_equalsT {
public int hashCode() {
return 2;
}
public boolean equals(Object obj) {
return true;
}
}
public class TestSet怎么才算重复 {
public static void main(String[] args) {
Set<Object> _set = new HashSet<Object>();
_set.add(new A_equalsT());
_set.add(new A_equalsT());
_set.add(new B_hash1());
_set.add(new B_hash1());
_set.add(new C_hash2_equalsT());
_set.add(new C_hash2_equalsT());
for (Object object : _set) {
System.out.println(object);
}
}
}
运行结果:(C_hash2_equalsT只存入一份,说明被看作重复对象)
B_hash1@1
B_hash1@1
C_hash2_equalsT@2
A_equalsT@15db9742
A_equalsT@6d06d69c
HashSet存储自定义元素时,需要重写hashCode和equals方法,才能保证集合中对象的唯一性。
练习:
创建Student类,至少需要包含id、name。创建多个Student对象加入HashSet,如果学号(id)相同则不重复加入。
TreeSet
TreeSet支持两种排序方式,自然排序和定制排序。默认为自然排序,和HashSet的输出顺序不一样。
TreeSet使用红黑树存储元素(示例和下一小节一起)。
LinkedHashSet
Set也可以有序,这个LinkedHashSet就能按照输入顺序输出结果。
LinkedHashSet也是根据元素的hashCode值决定元素的存储位置,但是加了一条链表记录元素的存储顺序,这使得元素有序。
import java.util.HashSet;
import java.util.LinkedHashSet;
import java.util.Set;
import java.util.TreeSet;
public class TestTree{
public static void main(String[] args) {
m020各种Set();
}
private static void m020各种Set() {
System.out.println("|-HashSet:");
Set<String> _set;
_set = new HashSet<String>();
_set.add("B");
_set.add("A");
_set.add("1");
_set.add("2");
_set.add(null);
printSet(_set);
System.out.println("|-TreeSet不接受空值:");
_set = new TreeSet<String>();
_set.add("B");
_set.add("A");
_set.add("1");
_set.add("2");
// _set.add(null);
printSet(_set);
System.out.println("|-LinkedHashSet:有序");
_set = new LinkedHashSet<String>();
_set.add("B");
_set.add("A");
_set.add("1");
_set.add("2");
_set.add(null);
printSet(_set);
}
private static void printSet(Set<String> _set) {
for (String str : _set) {
System.out.print(str + " ");
}
System.out.println();
}
}
|-HashSet:
null A 1 B 2
|-TreeSet不接受空值:
1 2 A B
|-LinkedHashSet:有序
B A 1 2 null
Set的性能
HashSet综合效率最高,LinkedHashSet因为有链表,遍历时会更快一些。TreeSet因为要维护红黑树,效率较低。