一、列表
[]表示列表,用','进行分隔,list有序 能够进行索引 切片 (in append extend count index insert pop remove,reverse sort copy)
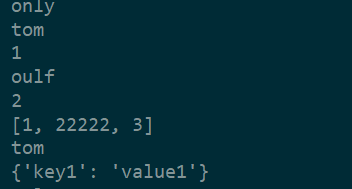
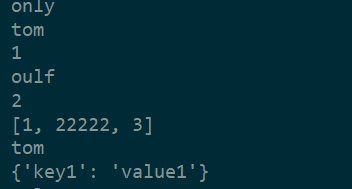
temp_ls = ['only', 'tom',1,'oulf',2,[1,22222,3],'tom',{'key1':'value1'}]
# 取列表中的嵌套列表,方法1
tyd = (temp_ls[5])
print(tyd[1])
# 取列表中的嵌套列表,方法2:
print((temp_ls[5])[1])

# 遍历列表方法1:用固定循环遍历 for
for i in temp_ls:
print(i)
# 遍历列表方法2:用非固定循环遍历while
len_temp_ls = len(temp_ls)
j = 0
while j<len_temp_ls:
print(temp_ls[j])
j +=1
# 列表拼接
temp_ls_1 = ['wow']
print(temp_ls + temp_ls_1)

# 列表删除
del(temp_ls[4])
print(temp_ls)

# 判断某个字符串是否在该列表中
if 'tom' in temp_ls:
print('YES')
else:
print('NO')

# 列表的添加append,将ts作为一个对象,添加到列表temp_ls中值得后面
ts = ['dds','dff','sd']
temp_ls.append(ts)
print(temp_ls)

# 列表的添加extend,把ts作为一个对象,将这个对象中的所有字符串一个一个添加到列表temp_ls中值得后面
temp_ls.extend(ts)
print(temp_ls)

# 统计列表中某个字符串出现的次数,count
print(temp_ls.count('tom'))
# 取出列表中值得索引index,当某个值存在多个时,只取出的是第一个
print(temp_ls.index('tom'))
# pop删除列表中最后一个元素,并且有返回删除的值
temp_ls.pop()
print(temp_ls.pop())
print(temp_ls)

# remove除列表中某一个元素,并且有返回删除的值
temp_ls.remove('dds')
print(temp_ls)
# insert向列表中插入元素,需要指定具体插入的位置
temp_ls.insert(2,'wcr')
print(temp_ls)

# reverse反向输入列表中的所有值
tp = [4,4,1,5,9,0]
tp.reverse()
print(tp)
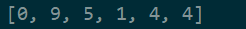
# srot给列表进行排序,只能对同数据类型的列表进行排序,当列表中存在字符串、数字、嵌套列表等,不能用sort进行对列表排序
tp.sort()
print(tp)

# 对列表进行反向排序
tp.sort(reverse=True)
print(tp)

print("-----------------------------------元组-------------------------------------------------")
# 二、元组tuple
用()表示,创建后不可以修改,也是有序类型
t = (32,'ab','dd',55,1)
# 判断某个元素是否存在元组中
if 'ab' in t:
print("i存在元组t中")
else:
print("i不存在元组t中")

# 元组也可以进行循环遍历
for i in t:
print(i)

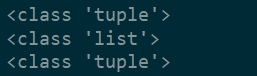
print(type(t))
print(type([]))
print(type((43,))) # 当存在1个值时,需要在这个值后面加一个,这样才能是tuple
print("-----------------------------------集合-------------------------------------------------")
# 三、集合set
用{}表示 set 无序类型、不可以切片,不能用索引取值,可以做两个集合的交集、并集、差集;可以判断是否存在in
s1 = {}
print(s1)
s = {3,45,'sdd','d3',33}
print(type(s))

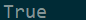
print((3 in s))
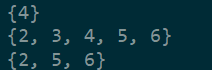
print({2,4,5,6}-{2,3,5,6}) # 差集
print({2,4,5,6}|{2,3,5,6}) # 并集
print({2,4,5,6}&{2,3,5,6}) # 交集
s1 = {3,4,5,7,8}
s2 = {4,5,6,7,9}
print(s1.difference(s2))
print(s1.union(s2))

print("-----------------------------------字典-------------------------------------------------")
# 四、字典dict
用{} 无序类型,键:值
d = {'name': 'tom', 'age': '20', 'class': '2班'}
country = {'中国': '北京', '美国': '华盛顿', '日本': '东京'}
print(country['中国'])
print(country.get('英国'))
print(country.get('日本')) # get方法访问字典

二、练习
1、冒泡排序
# _*_ coding: utf-8 _*_
import sys
import importlib
importlib.reload(sys)
'''
冒泡排序:
0.如果遇到相等的值不进行交换,那这种排序方式是稳定的排序方式。
1.原理:比较两个相邻的元素,将值大的元素交换到右边
2.思路:依次比较相邻的两个数,将比较小的数放在前面,比较大的数放在后面。
(1)第一次比较:首先比较第一和第二个数,将小数放在前面,将大数放在后面。
(2)比较第2和第3个数,将小数 放在前面,大数放在后面。
......
(3)如此继续,知道比较到最后的两个数,将小数放在前面,大数放在后面,重复步骤,直至全部排序完成
(4)在上面一趟比较完成后,最后一个数一定是数组中最大的一个数,所以在比较第二趟的时候,最后一个数是不参加比较的。
(5)在第二趟比较完成后,倒数第二个数也一定是数组中倒数第二大数,所以在第三趟的比较中,最后两个数是不参与比较的。
(6)依次类推,每一趟比较次数减少依次
3.算法分析:
(1)由此可见:N个数字要排序完成,总共进行N-1趟排序,每i趟的排序次数为(N-i)次,所以可以用双重循环语句,外层控制循环多少趟,内层控制每一趟的循环次数
(2)冒泡排序的优点:每进行一趟排序,就会少比较一次,因为每进行一趟排序都会找出一个较大值。如上例:第一趟比较之后,排在最后的一个数一定是最大的一个数,
第二趟排序的时候,只需要比较除了最后一个数以外的其他的数,同样也能找出一个最大的数排在参与第二趟比较的数后面,第三趟比较的时候,只需要比较除了最后两个数以外的其他的数,
以此类推……也就是说,没进行一趟比较,每一趟少比较一次,一定程度上减少了算法的量。
'''
num = [4,7,11,2,49,23,43,99,9]
print("列表排序'**前**'的值:{}".format(num))
# 方法1
for i in range(0,len(num)-1):
for j in range(0, len(num)-1-i):
if num[j] > num[j+1]:
temp = num[j+1]
num[j+1] = num[j]
num[j] = temp
print("列表排序后的值:{}".format(num))
# 方法2
for i in range(0,len(num)-1):
for j in range(0, len(num)-1-i):
if num[j] > num[j+1]:
num[j], num[j+1] = num[j+1], num[j] # a,b=b,a
print("列表排序'**后**'的值:{}".format(num))

2、利用Python语言,采用字典的方式对应月份和天数,采用选择结构和循环结构解决如下问题:输入某月某日,判断这一天是一年的第几天?
输出“这是年度第XX天”,
如若日期输入错误,则输出“error”。具体要求如下:
(1)创建python_day02_lx.py新文件并保存;
(2)采用字典的方式对应月份和天数;
(3)依次弹出对话“请输入月份:”和“请输入日期:”
(4)采用条件判断结构区分所输入日期是否正确,如果错误,输出“error”;
(5)如若输入日期正确,采用循环结构计算天数,输出“这是年度第XX天”;
# _*_ coding: utf-8 _*_
import sys
import importlib
importlib.reload(sys)
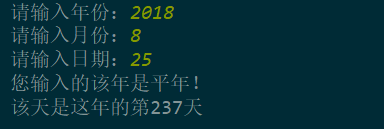
year = eval(input("请输入年份:"))
month = eval(input("请输入月份:"))
day = eval(input("请输入日期:"))
flag = 0 # 判断flag是否为平年还是闰年,flag=0为平年,flag=1是闰年
# 判断是否为闰年
if year < 9999 and month <= 13 and day < 32:
if (year%400== 0):
flag = 1
print("您输入的该年是闰年!")
elif (year%100!=0 and year%4== 0):
flag = 1
print("您输入的该年是闰年!")
else:
flag = 0
print("您输入的该年是平年!")
else:
print("输入错误:请重新输入年份!")
try:
if flag == 1:
ms = [31, 29, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31]
elif flag == 0:
ms = [31, 28, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31]
else:
print("日期输入错误!")
except:
print("ERROR!")
data = 0
# 先遍历前面几个月
for i in range(0, month-1):
data +=ms[i] # data=data+ms[i]
data +=day # data=data+day
# print("该天是这年的第%d天"%data)
print("该天是这年的第{0}天".format(data))
3、完数
完全数:如果一个数恰好等于它的因子之和,则称该数为“完全数” [1] 。各个小于它的约数(真约数,列出某数的约数,去掉该数本身,剩下的就是它的真约数)的和等于它本身的自然数叫做完全数(Perfect number),又称完美数或完备数。
例如:第一个完全数是6,它有约数1、2、3、6,除去它本身6外,其余3个数相加,1+2+3=6。第二个完全数是28,它有约数1、2、4、7、14、28,除去它本身28外,其余5个数相加,1+2+4+7+14=28。
第三个完全数是496,有约数1、2、4、8、16、31、62、124、248、496,除去其本身496外,其余9个数相加,1+2+4+8+16+31+62+124+248=496。
后面的完全数还有8128、33550336等等。
# _*_ coding: utf-8 _*_
import sys
import importlib
importlib.reload(sys)
'''
真因子是指除了它本身以外的因子,真因子包括1在内,应该是除了它本身以外的其他约数
约数,又称因数bai。整数a除以整数b(b≠0) 除得的商正好是整数而没有余数,我们就说a能被b整除,或b能整除a。a称为b的倍数,b称为a的约数。
'''
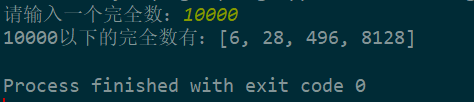
m = int(input("请输入一个完全数:"))
def PerfectNum(m):
a = [] # 定义一个存储数据的列表
for i in range(1, m):
s = 0
# print(i)
for j in range(1, i):
if i % j == 0: # 整数i除以整数j,商=0没有余数,j是i的约数,即真因子
s += j # 所得的真因子j相加,赋给s
# print(s)
if i == s: # 当真因子相加的s=完全数i
a.append(i) # 把完全数i添加到存储数据的a中
return a
if __name__ == '__main__':
k = PerfectNum(m)
print("{}以下的完全数有:{}".format(m, k))