这个爬虫集训课第三章的作业讲得是Scrapy
课程主要是使用Scrapy + Redis实现分布式爬虫
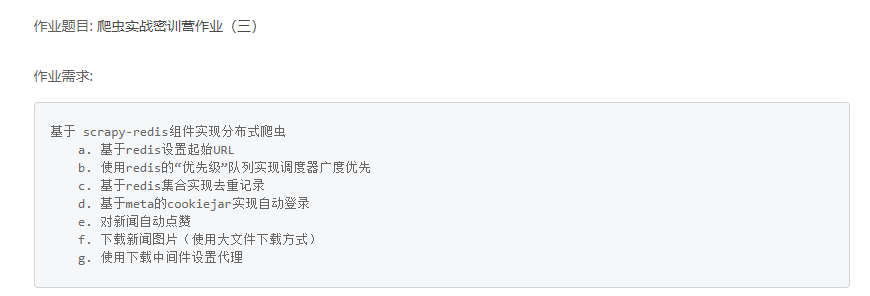
惯例贴一下作业:
Python爬虫可以使用Requests库来进行简单爬虫的编写,但是Requests的性能很差,一个请求耗时在2秒左右,毫无性能。
当然也可以使用gevent和asyncio来实现协程提升性能。但是要实现分布式爬虫的话,还是要用Scrapy, Scrapy内部是使用的
twisted实现的异步功能。
贴下作业目录。

下边记录下作业完成中遇到的问题
作业实现过程:
1、windows10安装python3.6.6
2、安装虚拟环境 python -m venv scrapy_venv
3、激活虚拟环境
因为PowerShell默认不允许执行*.ps1脚本文件,所以首先需要开启权限。
以管理员身份启动PowerShell,并执行Set-ExecutionPolicy RemoteSigned。
PS C:WINDOWSsystem32> Set-ExecutionPolicy RemoteSigned
执行策略更改
执行策略可帮助你防止执行不信任的脚本。更改执行策略可能会产生安全风险,如
http://go.microsoft.com/fwlink/?LinkID=135170 中的 about_Execution_Policies
帮助主题所述。是否要更改执行策略?
[Y] 是(Y) [A] 全是(A) [N] 否(N) [L] 全否(L) [S] 暂停(S) [?] 帮助
(默认值为“N”):Y
之后就会显示上面的选项,输入Y,再回车。
最后再启动...venvScriptsActivate.ps文件。
命令提示符开头显示(venv) PS ...即表示激活Python虚拟环境成功了!
4、在虚拟环境中使用pip install twisted, 之前windows上无法使用该命令安装twisted,可能官方维护了twisted包,现在可以直接使用pip进行安装。然后使用pip安装scrapy和scarpy-redis。(pip install pywin32)
5、使用scrapy startproject demo创建scrapy爬虫项目。
6、进入上一步创建的项目目录,使用scrapy genspider chouti chouti.com创scrapy爬虫。
7、使用pycharm打开项目,配置解释器。
注意:
windows上下载https图片失败,报错如下

这个问题在windows上折腾了好久,无解。
换到centos上之后,问题解决。