一、哈夫曼树的概念和定义
什么是哈夫曼树?
让我们先举一个例子。
判定树:
if(score<60)
cout<<"Bad"<<endl;
else if(score<70)
cout<<"Pass"<<endl
else if(score<80)
cout<<"General"<<endl;
else if(score<90)
cout<<"Good"<<endl;
else
cout<<"Very good!"<<endl;
下面我们就利用哈夫曼树寻找一棵最佳判定树,即总的比较次数最少的判定树。
第一种构造方式:
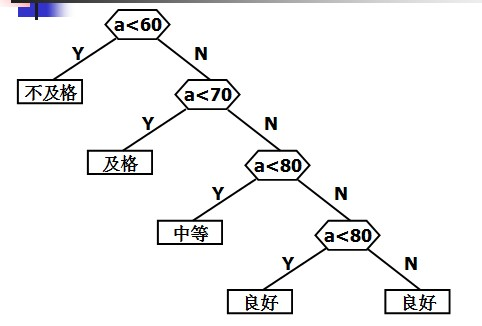
第二种构造方式:

这两种方式,显然后者的判定过程的效率要比前者高。在也没有别地判定过程比第二种方式的效率更高。
定义哈夫曼树之前先说明几个与哈夫曼树有关的概念:
- 路径: 树中一个结点到另一个结点之间的分支构成这两个结点之间的路径。
- 路径长度:路径上的分枝数目称作路径长度。
- 树的路径长度:从树根到每一个结点的路径长度之和。
- 结点的带权路径长度:在一棵树中,如果其结点上附带有一个权值,通常把该结点的路径长度与该结点上的权值 之积称为该结点的带权路径长度(weighted path length)
- 权值就是定义的路径上面的值。可以这样理解为节点间的距离。通常指字符对应的二进制编码出现的概率。至于霍夫曼树中的权值可以理解为:权值大表明出现概率大!一个结点的权值实际上就是这个结点子树在整个树中所占的比例.
-
树的带权路径长度:如果树中每个叶子上都带有一个权值,则把树中所有叶子的带权路径长度之和称为树的带权路径长度。
设某二叉树有n个带权值的叶子结点,则该二叉树的带权路径长度记为:
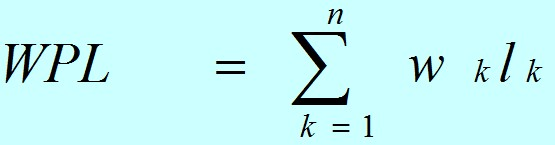 (公式中,Wk为第k个叶子结点的权值;Lk为该结点的路径长度。)
(公式中,Wk为第k个叶子结点的权值;Lk为该结点的路径长度。)
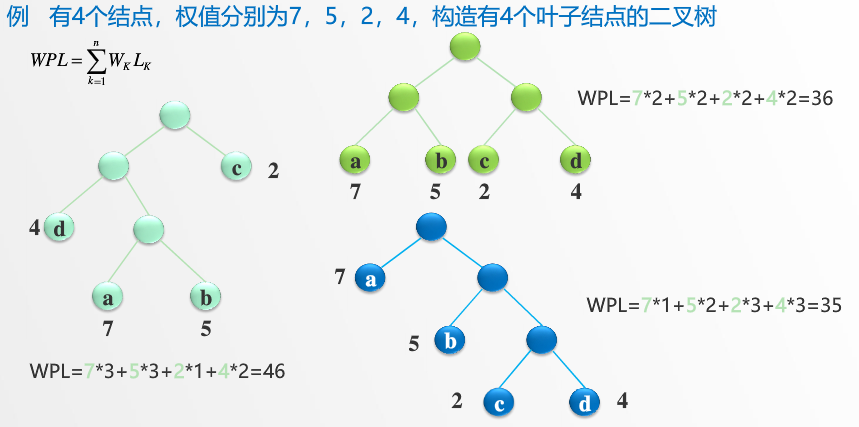
二、哈夫曼树的构造

注意:哈夫曼树并不唯一,但带权路径长度一定是相同的。
下面演示了用Huffman算法构造一棵Huffman树的过程:
(1)8个结点的权值大小如下:

(2)从19,21,2,3,6,7,10,32中选择两个权小结点。选中2,3。同时算出这两个结点的和5。
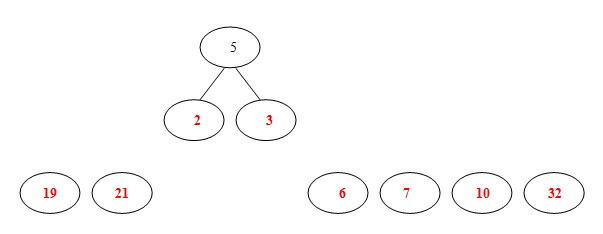
(3)从19,21,6,7,10,32,5中选出两个权小结点。选中5,6。同时计算出它们的和11。
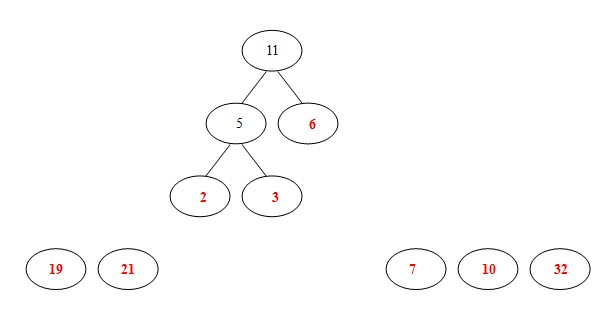
(4)从19,21,7,10,32,11中选出两个权小结点。选中7,10。同时计算出它们的和17。
(BTW:这时选出的两个数字都不是已经构造好的二叉树里面的结点,所以要另外开一棵二叉树;或者说,如果两个数的和正好是下一步的两个最小数的其中的一个,那么这个树直接往上生长就可以了,如果这两个数的和比较大,不是下一步的两个最小数的其中一个,那么就并列生长。)
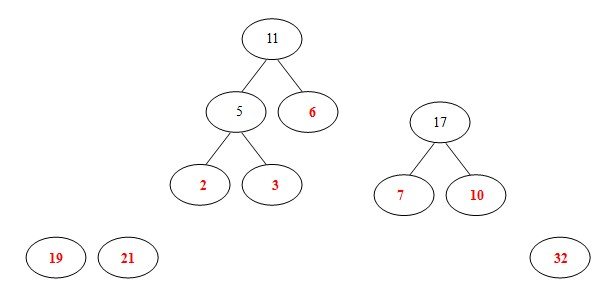
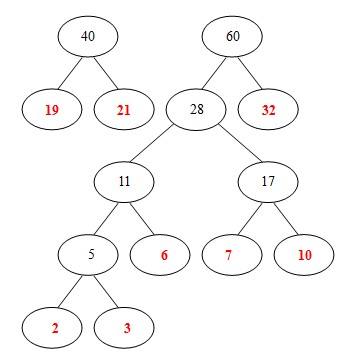
(5)从19,21,32,11,17中选出两个权小结点。选中11,17。同时计算出它们的和28。
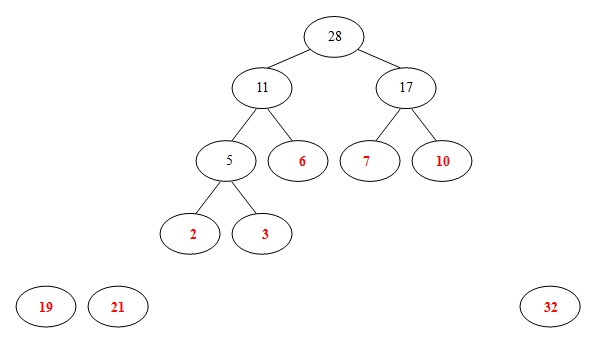
(6)从19,21,32,28中选出两个权小结点。选中19,21。同时计算出它们的和40。另起一颗二叉树。
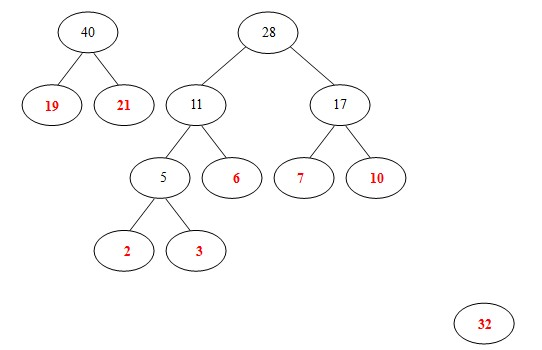
(7)从32,28, 40中选出两个权小结点。选中28,32。同时计算出它们的和60。
(8)从 40, 60中选出两个权小结点。选中40,60。同时计算出它们的和100。 好了,此时哈夫曼树已经构建好了。
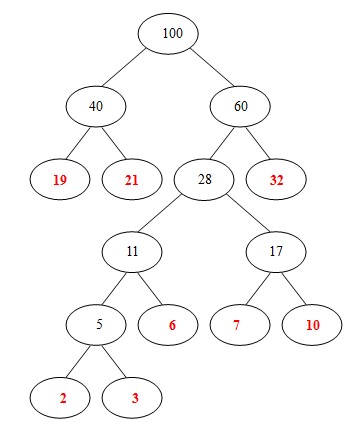
哈夫曼树又称为最优二叉树,它的节点总数和二叉树相同为2n-1,n为叶子节点个数。
三、哈夫曼树的在编码中的应用

参考:https://www.cnblogs.com/13224ACMer/p/4706174.html