BeautifulSoup里的find()0和find_all()可能是你最常用的两个函数。借助她们,你可以通过标签的不同属性轻松地过滤HTML页面,查找需要的标签组或者单个标签。
find_all(tag, attributes, recursive, text, limit, keywords)
find_all(标签、属性、递归、文本、限制、关键词)
find(tag, attributes, recursive, text, keywords)
95%的时间里都只需要使用前2个参数:tag和attributes,即标签和属性。
参数attributes用一个python字典封装一个标签的若干属性和对应的属性值。例如,下面的函数会返回HTML文档中绿色的span标签;
.find_all('span',{'class':'green'}
网页链接:http://www.pythonscraping.com/pages/warandpeace.html
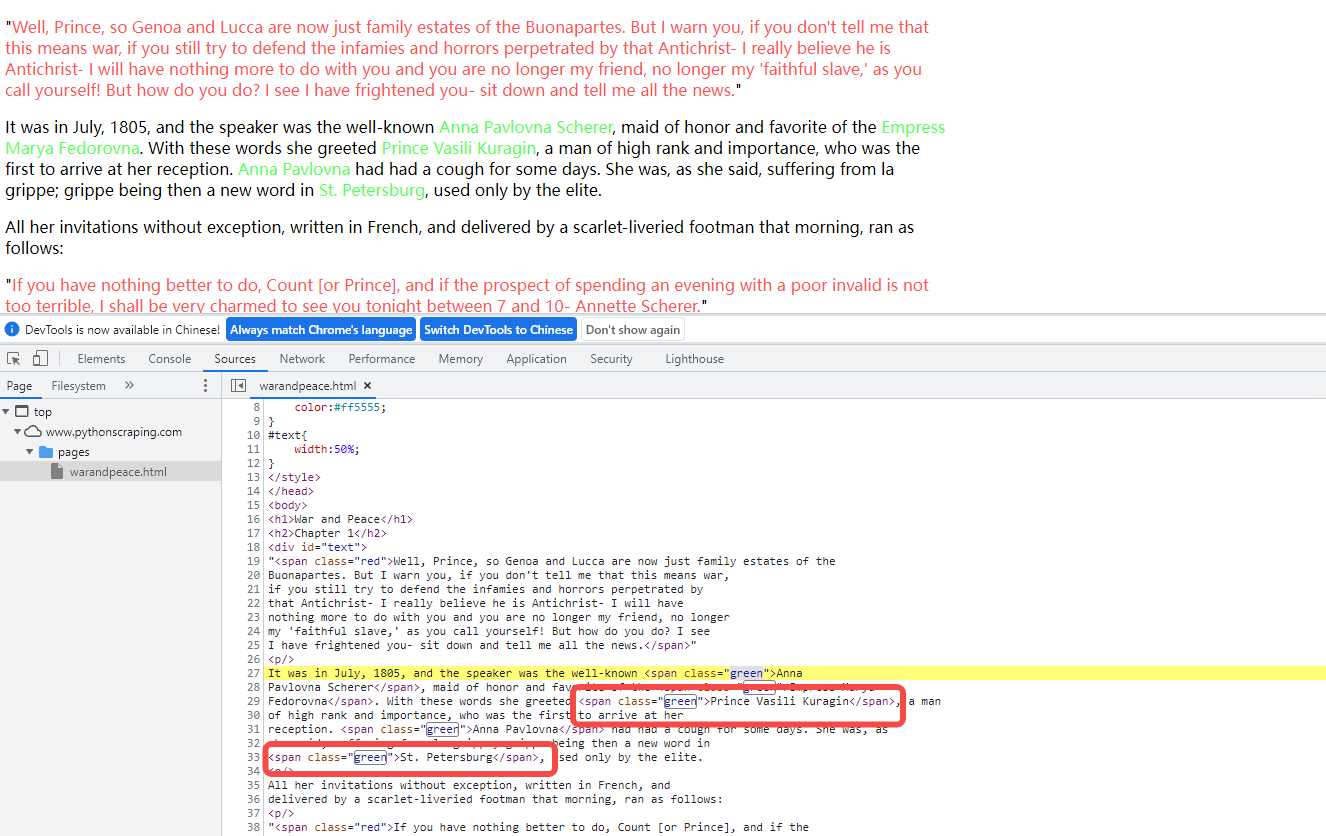
通过BeautifulSoup对象,我们可以用find_all函数提取只包含在<span class="green">...</span>标签里的文字,这样就会得到一个人物名称的python列表。
from urllib.request import urlopen from bs4 import BeautifulSoup html = urlopen('http://www.pythonscraping.com/pages/warandpeace.html') bs = BeautifulSoup(html.read(),'html.parser') nameList = bs.find_all('span',{'class':'green'}) for name in nameList: print(name.get_text())