爬虫大作业
1.选一个自己感兴趣的主题。
2.用python 编写爬虫程序,从网络上爬取相关主题的数据。
3.对爬了的数据进行文本分析,生成词云。
4.对文本分析结果进行解释说明。
5.写一篇完整的博客,描述上述实现过程、遇到的问题及解决办法、数据分析思想及结论。
本次的大数据作业呢,是把我们爬取到的网页数据生成词云,在python中生成词云往往用到的就是使用 词云包wordcloud .
但是我们安装wordcloud的时候会遇到问题:
在Windows电脑终端使用pip install wordcloud并不能直接安装wordcloud
首先我们先来解决几个可能会遇到的问题:
我们在使用在cmd中使用pip install wordcloud总会出现如下面这种缺失东西情况:
这是我在网上看的安装教程:https://blog.csdn.net/th_num/article/details/77095075
https://blog.csdn.net/llx1026/article/details/77478895
首先查看自己的python版本

这时候需要读者前往一下链接http://www.lfd.uci.edu/~gohlke/pythonlibs/#wordcloud,在该链接下找到合适自己的wordcloud版本,下载到python安装目录下,然后打开电脑cmd终端,使用cd/d切换到wordcloud安装包文件夹下,在终端输入:pip install wordcloud-1.4.1-cp36-cp36m-win_amd64.whl

如果遇到pip版本的问题则需要先进行pip更新,之后再安装,如下图所示:

这样即可完成wordcloud安装!!!
安装完后你还需要在python-pycharm里setting。
如果实在是不行的话,这是wordcloud的包:
链接:https://pan.baidu.com/s/1HeuEtxgf_u23_zP31h_6NA 密码:38k2
把下载好的包,拷到:软件(Python-pycharm)下,你的工程项目里面的 venvLibsite-packages 这里面。就行了。
以下是我是爬取网易-云计算社区问答的词云:
#coding=utf-8#coding=utf-8 # -*- coding : UTF-8 -*- import requests from bs4 import BeautifulSoup import re import jieba from wordcloud import WordCloud import matplotlib.pyplot as plt import pickle from wordcloud import WordCloud,STOPWORDS,ImageColorGenerator def getKeynews(content): content = ''.join(re.findall('[u4e00-u9fa5]', content)) # 通过正则表达式选取中文字符数组,拼接为无标点字符内容 # 去掉重复的字符生成集合 newSet = set(jieba._lcut(content)) #划分内容 newDict = {} #定义字典 for i in newSet: newDict[i] = content.count(i) deleteList, keynews = [], [] for i in newDict.keys(): if len(i) < 2: deleteList.append(i) #去掉单音无意义字符 for i in deleteList: del newDict[i] dictList = list(newDict.items()) dictList.sort(key=lambda item: item[1], reverse=True) # 排序 for dict in dictList: keynews.append(dict[0]) return keynews # 将词云写入到文件 def writeFilekeynews(keywords): f = open('Filekeynews', 'a', encoding='utf-8') for word in keywords: f.write(" "+word) f.close() #将回答内容写入文件 def writeFilecontent(contnet): f = open('Filecontent.txt', 'a', encoding='utf-8') f.write(" "+contnet) f.close() def getWordCloud(): keynewsTowordcloud = open('keyword.txt', 'r', encoding='utf-8').read() print(keynewsTowordcloud) # text = pickle.load(keynewsTowordcloud) backgroud_Image = plt.imread('bg.jpg') wc = WordCloud(background_color='white', # 设置背景颜色 mask=backgroud_Image, # 设置背景图片 stopwords=STOPWORDS, max_words=80, # 设置最大现实的字数 font_path='C:WindowsFontsAdobeKaitiStd-Regular.otf', # 设置字体格式,如不设置显示不了中文 max_font_size=80, # 设置字体最大值 random_state=30, # 设置有多少种随机生成状态,即有多少种配色方案 ) wc.generate(keynewsTowordcloud) image_colors = ImageColorGenerator(backgroud_Image) wc.recolor(color_func=image_colors) plt.imshow(wc) plt.axis('off') plt.show() def getDetail(newsUrl): #对每个li下的回答内容进行保存获取 resd = requests.get(newsUrl) resd.encoding = 'utf-8' soupd = BeautifulSoup(resd.text, 'html.parser') content = soupd.select('.cnt-qs')[0].text writeFilecontent(content) keynews = getKeynews(content) writeFilekeynews(keynews) def Get_Pageurl(url): res = requests.get(url) res.encoding = 'utf-8' soup = BeautifulSoup(res.text, 'html.parser') for new in soup.select('.m-ask-item')[0].select('.item'): theUrl= new.select('.tlt.tlt-1')[0].select('a')[0]['href'] #获取每个li标签下的url url = 'https://sq.163yun.com' + theUrl getDetail(url) url = 'https://sq.163yun.com/ask/search?current=1&keywords=5LqR6K6h566X' #网易云问答的网站 resd = requests.get(url) resd.encoding = 'utf-8' soup1 = BeautifulSoup(resd.text, 'html.parser') Get_Pageurl(url) #获取每个li标签下的url for i in range(2, 3): Get_Pageurl('https://sq.163yun.com/ask/search?current={}&keywords=5LqR6K6h566X'.format(i)) getWordCloud()
结果如下:
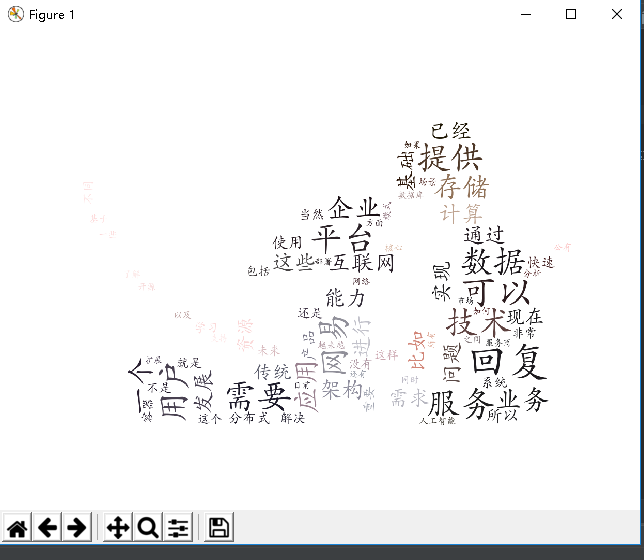
对文本分析结果进行解释说明。
以上就是分词后进行词云统计的结果,首先是爬取相关数据,之后保存到文本中,再对文本进行分词处理,最后运用wordcloud包进行词云生成。
问题:
wordcloud包安装时的问题,以及一些陌生的库的使用。
方法:找同学帮忙,上网搜索问题原因所在。