窗口函数
语法中<>中的内容不可省略,[]中的内容可以省略。即PARTIION BY和框架可以省略,ORDER BY 不可以省略。框架对汇总范围进行限定。
(ROWS | RANGE) BETWEEN (UNBOUNDED | [num]) PRECEDING AND ([num] PRECEDING | CURRENT ROW | (UNBOUNDED | [num]) FOLLOWING)
(ROWS | RANGE) BETWEEN CURRENT ROW AND (CURRENT ROW | (UNBOUNDED | [num]) FOLLOWING)
(ROWS | RANGE) BETWEEN [num] FOLLOWING AND (UNBOUNDED | [num]) FOLLOWING窗口函数实操
先创建一张产品表
create table PRODUCT
(
PRODUCT_ID NUMBER(4),
PRODUCT_NAME VARCHAR2(50),
PRODUCT_TYPE VARCHAR2(50),
SALE_PRICE NUMBER(4)
)
插入数据
insert into PRODUCT (PRODUCT_ID, PRODUCT_NAME, PRODUCT_TYPE, SALE_PRICE)
values (1, '叉子', '厨房用具', 500);
insert into PRODUCT (PRODUCT_ID, PRODUCT_NAME, PRODUCT_TYPE, SALE_PRICE)
values (2, '擦菜板', '厨房用具', 880);
insert into PRODUCT (PRODUCT_ID, PRODUCT_NAME, PRODUCT_TYPE, SALE_PRICE)
values (3, '菜刀', '厨房用具', 3000);
insert into PRODUCT (PRODUCT_ID, PRODUCT_NAME, PRODUCT_TYPE, SALE_PRICE)
values (4, '高压锅', '厨房用具', 6800);
insert into PRODUCT (PRODUCT_ID, PRODUCT_NAME, PRODUCT_TYPE, SALE_PRICE)
values (5, 'T恤衫', '衣服', 1000);
insert into PRODUCT (PRODUCT_ID, PRODUCT_NAME, PRODUCT_TYPE, SALE_PRICE)
values (6, '运动T恤', '衣服', 4000);
insert into PRODUCT (PRODUCT_ID, PRODUCT_NAME, PRODUCT_TYPE, SALE_PRICE)
values (7, '圆珠笔', '办公用品', 100);
insert into PRODUCT (PRODUCT_ID, PRODUCT_NAME, PRODUCT_TYPE, SALE_PRICE)
values (8, '打孔器', '办公用品', 500);
结果表如图

其中:
range between unbounded preceding and current row 指定计算当前行开始、当前行之前的所有值;
rows between 1 preceding and current row 指定计算当前行的前一行开始,其范围一直延续到当前行;
range between current row and unbounded following 指定计算从当前行开始,包括它后面的所有行;
rows between current row and 1 following 指定计算当前行和它后面的一行;
1)可以作为窗口函数的聚合函数。
- sum求和(累计值)
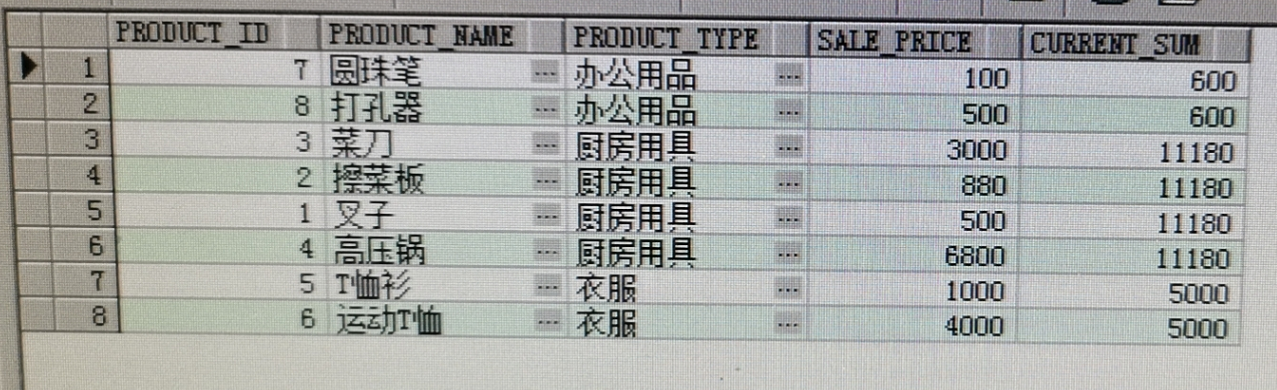
--1.0 先从最基本的来,以product_type分层,得到如下结果,current_sum是把同一个product_type的sale_price加起来作为一列
SELECT product_id, product_name, product_type, sale_price,
SUM(sale_price) OVER (PARTITION BY product_type ) AS current_sum FROM Product;
--2.0 order+ range BETWEEN UNBOUNDED PRECEDING and current row 的练习
SELECT product_id, product_name, product_type, sale_price,
SUM(sale_price) OVER ( ORDER BY sale_price ) AS current_sum
FROM Product;
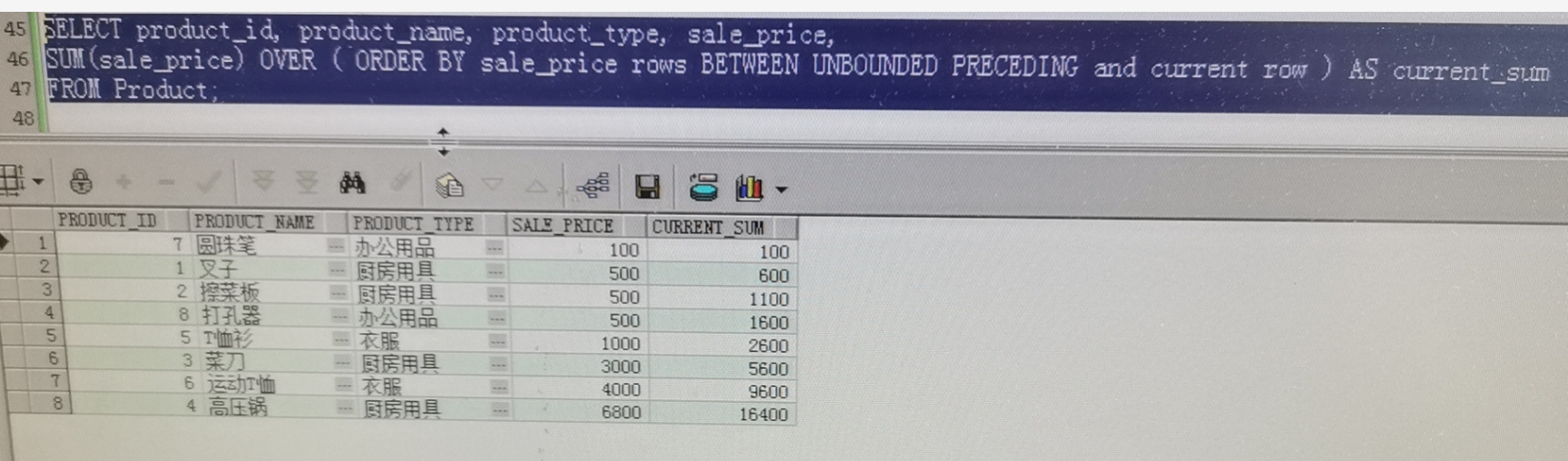
# 上边语句和下边语句结果相同
SELECT product_id, product_name, product_type, sale_price,
SUM(sale_price) OVER ( ORDER BY sale_price range BETWEEN UNBOUNDED PRECEDING and current row ) AS current_sum
FROM Product;

注:默认框架为 range BETWEEN UNBOUNDED PRECEDING and current row
结论:相同的sale_price会有相同的current_sum;同时sum的合是上面的所有sale_price的合加上所有本相同的sale_price的合
--3.0 ORDER + rows BETWEEN UNBOUNDED PRECEDING and current row
SELECT product_id, product_name, product_type, sale_price,
SUM(sale_price) OVER ( ORDER BY sale_price rows BETWEEN UNBOUNDED PRECEDING and current row ) AS current_sum
FROM Product;
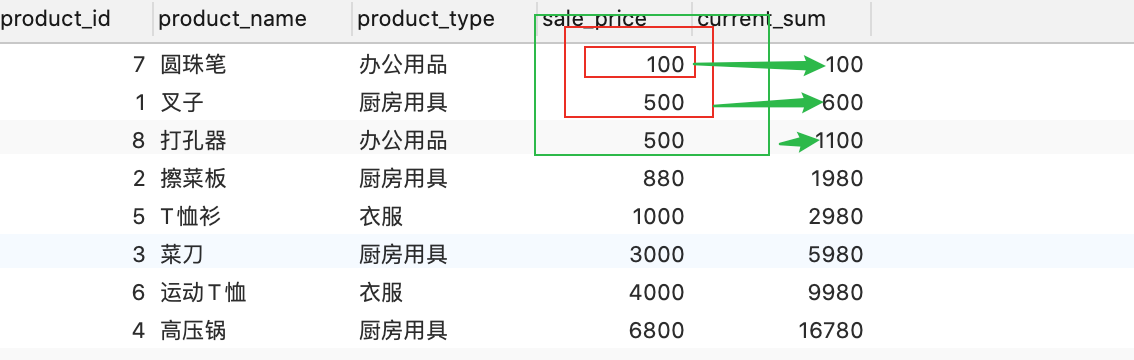
结论:单纯的从上到下的sale_price相加得到sum
row和range的区别是rows按照行进行计算,如当求第一行的时候,求和为第一行-第一行,当求第二行的时候,求和为第一行-第二行;
而range是按照值进行计算,如sale_price, 当sale_price=100,求和范围为100-100,当sale_price=500,求和范围为100-500。
然后把厨房用品擦菜板880改成了500,为了验证上面的结论,结果如下
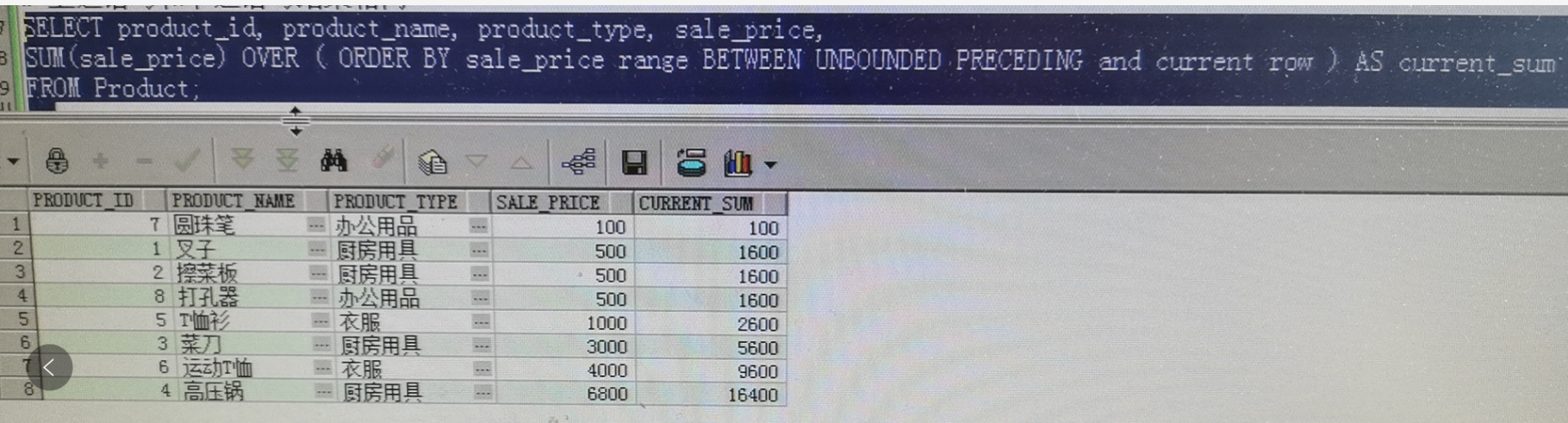
综上得到的结论:
range与rows的区别是,前者类似分组的相加,只要是相同的sale_price就相加起来,得到相同的sum
rows是行的维度,只是简单的一行一行的相加
同时最终的sum是相同的
--4.0 PARTITION + order+ range +BETWEEN UNBOUNDED PRECEDING and current row 的练习
SELECT product_id, product_name, product_type, sale_price,
SUM(sale_price) OVER (PARTITION BY product_type ORDER BY sale_price range BETWEEN UNBOUNDED PRECEDING and current row ) AS current_sum
FROM Product;
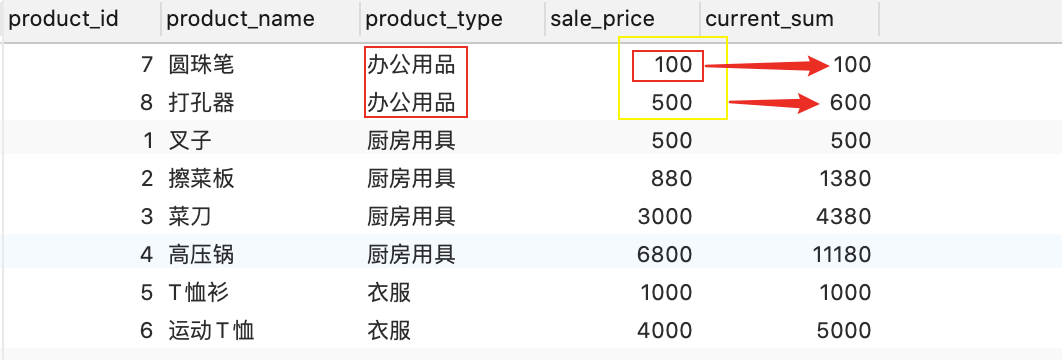
结论:PARTITION 与 ORDER同时存在且是两列的话,可以理解为在PARTITION同一组的相互相加,不带非同PARTITION的玩,sum求和是同一组的从上到下依次,遇到新的PARTITION重新相加求和
===================
- MIN、MAX、AVG、COUNT
-
SELECT product_id, product_name, product_type, sale_price, MIN(sale_price) OVER ( PARTITION BY product_type ORDER BY sale_price ) AS current_min, MAX(sale_price) OVER ( PARTITION BY product_type ORDER BY sale_price ) AS current_max, AVG(sale_price) OVER ( PARTITION BY product_type ORDER BY sale_price ) AS current_avg, COUNT(sale_price) OVER ( PARTITION BY product_type ORDER BY sale_price ) AS current_count
注:默认框架为range BETWEEN UNBOUNDED PRECEDING and current row*,range是按照值进行计算的,以count来进行讲述,第一组第一行count计算的范围为sale_price值,就是100-100的就一个值,计数1;第一组第二行count计算的范围为100-500,计数2;第二组第一行count计算的范围为500-500,计数2。后续类似。
2)专用窗口函数
- RANK----------DENSE_RANK----ROW_NUMBER
- 不连续排序 ----连续排序 ----------行号
SELECT product_id, product_name, product_type, sale_price,
rank() OVER ( PARTITION BY product_type ORDER BY sale_price rows BETWEEN 2 PRECEDING and current row ) AS current_rk,
dense_rank() OVER ( PARTITION BY product_type ORDER BY sale_price ) AS current_drk,
row_number() OVER ( PARTITION BY product_type ORDER BY sale_price ) AS current_rn
FROM Product;

注:rank函数排序是可以跳跃的,dense_rank函数排序是顺序的,row_number函数排序是按照行数。
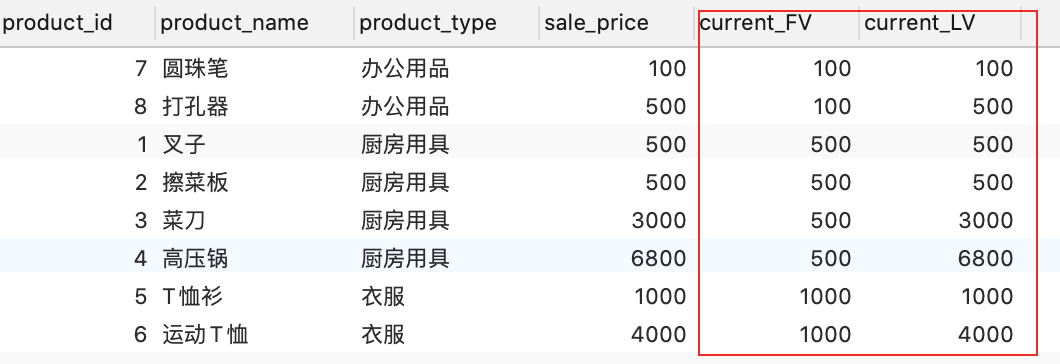
- FIRST_VALUE--------------------------------LAST_VALUE
- 返回组中数据窗口的第一个值-------------------返回组中数据窗口的最后一个值
SELECT product_id, product_name, product_type, sale_price,
FIRST_VALUE(sale_price) OVER ( PARTITION BY product_type ORDER BY sale_price ) AS current_FV,
LAST_VALUE(sale_price) OVER ( PARTITION BY product_type ORDER BY sale_price ) AS current_LV
FROM Product;
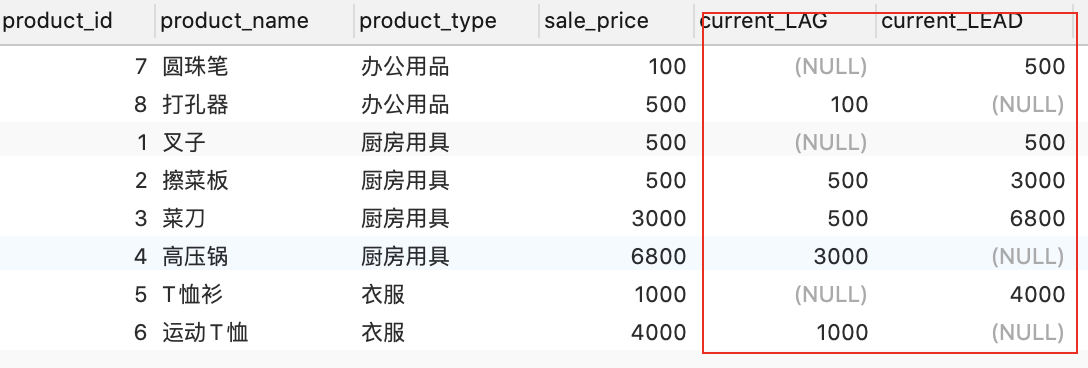
- LAG 、LEAD。
lag与lead函数是跟偏移量相关的两个分析函数,通过这两个函数可以在一次查询中取出同一字段的前N行的数据(lag)和后N行的数据(lead)作为独立的列,从而更方便地进行进行数据过滤。这种操作可以代替表的自联接,并且LAG和LEAD有更高的效率。
LAG(sale_price,1) 即代表前一行的数
LEAD(sale_price,1)即代表后一行的数
例如:lead(field, num, defaultvalue) field需要查找的字段,num往后查找的num行的数据,defaultvalue没有符合条件的默认值。
SELECT product_id, product_name, product_type, sale_price,
LAG(sale_price,1) OVER ( PARTITION BY product_type ORDER BY sale_price ) AS current_LAG,
LEAD(sale_price,1) OVER ( PARTITION BY product_type ORDER BY sale_price ) AS current_LEAD
FROM Product;
总结
窗口函数兼具GROUP BY 子句的分组功能和ORDER BY子句的排序功能,但是PARTITION BY子句跟GROUP BY 不具备汇总功能,也就说PARTITION BY子句不会减少行数。
通过PARTITION BY 分组后的记录集合称为窗口。此处的窗口并非“窗户”的意思,而是代表范围。这也是“窗口函数”名称的由来。
4个式子中才理解了第一个,还需要实践其他三个
原文:https://zhuanlan.zhihu.com/p/273846136,略有修改