原版论文是《Mastering the game of Go with deep neural networks and tree search》,有时间的还是建议读一读,没时间的可以看看我这篇笔记凑活一下。网上有一些分析AlphaGo的文章,但最经典的肯定还是原文,还是踏踏实实搞懂AlphaGo的基本原理我们再来吹牛逼吧。
需要的一些背景
对围棋不了解的,其实也不怎么影响,因为只有feature engineering用了点围棋的知识。这里有一篇《九张图告诉你围棋到底怎么下》可以简单看看。
对深度学习不怎么了解的,可以简单当作一个黑盒算法。但机器学习的基础知识还是必备的。没机器学习基础的估计看不太懂。
“深度学习是机器学习的一种,它是一台精密的流水线,整头猪从这边赶进去,香肠从那边出来就可以了。”- 1
- 1
蒙特卡罗方法
蒙特卡罗算法:采样越多,越近似最优解;
拉斯维加斯算法:采样越多,越有机会找到最优解;
举个例子,假如筐里有100个苹果,让我每次闭眼拿1个,挑出最大的。于是我随机拿1个,再随机拿1个跟它比,留下大的,再随机拿1个……我每拿一次,留下的苹果都至少不比上次的小。拿的次数越多,挑出的苹果就越大,但我除非拿100次,否则无法肯定挑出了最大的。这个挑苹果的算法,就属于蒙特卡罗算法——尽量找好的,但不保证是最好的。
作者:苏椰
链接:https://www.zhihu.com/question/20254139/answer/33572009- 1
- 2
- 3
- 4
- 5
- 6
- 1
- 2
- 3
- 4
- 5
- 6
蒙特卡罗树搜索(MCTS)
网上的文章要不拿蒙特卡罗方法忽悠过去;要不笼统提一下,不提细节;要不就以为只是树形的随机搜索,没啥好谈。但MCTS对于理解AlphaGo还是挺关键的。
MCTS这里的采样,是指一次从根节点到游戏结束的路径访问。只要采样次数够多,我们可以近似知道走那条路径比较好。貌似就是普通的蒙特卡罗方法?但对于树型结构,解空间太大,不可能完全随机去采样,有额外一些细节问题要解决:分支节点怎么选(宽度优化)?不选比较有效的分支会浪费大量的无谓搜索。评估节点是否一定要走到底得到游戏最终结果(深度优化)?怎么走?随机走?
基本的MCTS有4个步骤Selection,Expansion,Simulation,Backpropagation(论文里是backup,还以为是备份的意思),论文里state,action,r(reward),Q 函数都是MCTS的术语。 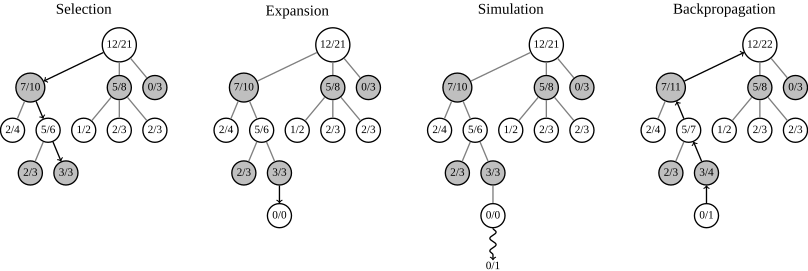
图片展示了如何更新节点的胜率,选择胜率大的分支进行搜索(7/10->5/6->3/3),到了3/3叶子节点进行展开选择一个action,然后进行模拟,评估这个action的结果。然后把结果向上回溯到根节点。来自维基百科
具体的细节,可以参考UCT(Upper Confidence Bound for Trees) algorithm – the most popular algorithm in the MCTS family。从维基百科最下方那篇论文截的图。原文有点长,这里点到为止,足够理解AlphaGO即可。N是搜索次数,控制exploitation vs. exploration。免得一直搜那个最好的分支,错过边上其他次优分支上的好机会。

AlphaGo

四大组件。最后只直接用了其中3个,间接用其中1个。
Policy Network (Pσ)
Supervised learning(SL)学的objective是高手在当前棋面(state)选择的下法(action)。Pσ=(a|s)
要点
1. 从棋局中随机抽取棋面(state/position)
2. 30 million positions from the KGS Go Server (KGS是一个围棋网站)。数据可以说是核心,所以说AI战胜人类还为时尚早,AlphaGo目前还是站在人类expert的肩膀上前进。
3. 棋盘当作19*19的黑白二值图像,然后用卷积层(13层)。比图像还好处理。rectifier nonlinearities
3. output all legal moves
4. raw input的准确率:55.7%。all input features:57.0%。后面methods有提到具体什么特征。需要一点围棋知识,比如liberties是气的意思
Fast Rollout Policy (Pπ)
linear softmax + small pattern features 。对比前面Policy Network,
- 非线性 -> 线性
- 局部特征 -> 全棋盘
准确率降到24.2%,但是时间3ms-> 2μs。前面MCTS提到评估的时候需要走到底,速度快的优势就体现出来了。
Reinforcement Learning of Policy Networks (Pρ)
要点
- 前面policy networks的结果作为初始值ρ=μ
- 随机选前面某一轮的policy network来对决,降低过拟合。
- zt=±1是最后的胜负。决出胜负之后,作为前面每一步的梯度优化方向,赢棋就增大预测的P,输棋就减少P。
- 校正最终objective是赢棋,而原始的SL Policy Networks预测的是跟expert走法一致的准确率。所以对决结果80%+胜出SL。
跟Pachi对决,胜率从原来当初SL Policy Networks的11%上升到85%,提升还是非常大的。
Reinforcement Learning of Value Networks (vθ)
判断一个棋面,黑或白赢的概率各是多少。所以参数只有s。当然,你枚举一下a也能得到p(a|s)。不同就是能知道双方胜率的相对值
- using policy p for both players (区别RL Policy Network:前面随机的一个P和最新的P对决)
- vθ(s)≈vPρ(s)≈v∗(s) 。v∗(s) 是理论上最优下法得到的分数。显然不可能得到,只能用我们目前最强的Pρ算法来近似。但这个要走到完才知道,只好再用Value Network vθ(s)来学习一下了。
Δθ∝∂vθ(s)∂θ(z−vθ(s))
(上面式子应该是求min(z−vθ(s))2,转成max就可以去掉求导的负号)因为前序下法是强关联的,输入只有一个棋子不同,z是最后结果,一直不变,所以直接这么算会overfitting。变成直接记住结果了。解法就是只抽取game中的position,居然生成了30 million distinct positions。那就是有这么多局game了。
| MSE | training set | test set |
|---|---|---|
| before | 0.19 | 0.37 |
| after | 0.226 | 0.234 |
AlphaGo与其他程序的对比。AlphaGo上面提到的几个组件之间对比。这几个组件单独都可以用来当AI,用MCTS组装起来威力更强。(kyu:级,dan:段)

MCTS 组装起来前面的组件
结构跟标准的MCTS类似。

每次MCTS simulation选择
我自己补了个常数C,写到一起容易看点。
V(θL)是叶子节点的评估值,Q是多次模拟后的期望V(θL)。有趣的是实验结果λ=0.5是最好的
- value network vθ
- fast rollout走到结束的结果zL
最开始还没expand Q是0,那SL的Pσ 就是prior probabilities。Pσ还能起到减少搜索宽度的作用,普通点得分很低。比较难被select到。有趣的结论是,比较得出这里用SL比RL的要好!!模仿人类走棋的SL结果更适合MCTS搜索,因为人类选择的是 a diverse beam of promising moves。而RL的学的是最优的下法(whereas RL optimizes
for the single best move)。所以人类在这一点暂时获胜!不过另一方面,RL学出来的value networks在评估方面效果好。所以各有所长。
搜索次数N一多会扣分, 鼓励exploration其他分支。
summary
整体看完,感觉AlphaGo实力还是挺强的。在机器学习系统设计和应用方面有很大的参考意义。各个组件取长补短也挺有意思。
了解了AlphaGo之后,再去看别人的分析就比较有感觉了,比如fb同样弄围棋的 @田渊栋 的 AlphaGo的分析 - 远东轶事 - 知乎专栏