1.下载地址
https://dist.apache.org/repos/dist/release/hadoop/common/
我们这里用的版本是:hadoop-2.7.7.tar.gz
2.创建安装目录
我们在Centos环境中的opt目录创建install文件夹(用来存放压缩包)和soft文件夹(用来存放解压之后的文件):
cd /opt
mkdir install soft
3.下载rz(用来向Linux Centos传送文件)和sz命令:
yum install -y lrzsz
接着进入install目录:cd /opt/install
然后输入rz命令 选中我们刚才下载的hadoop-2.7.7.tar.gz 传输完毕后我们在instal目录输入ll命令就可以看到hadoop-2.7.7.tar.gz
4.解压hadoop-2.7.7.tar.gz
输入命令:tar -zxvf hadoop-2.7.7.tar.gz
解压成功后我们会在install目录看到一个hadoop-2.7.7文件,这就是我们需要的东西,接下来移动一下位置,把它移到 opt目录的soft文件夹中:mv hadoop-2.7.7 /opt/soft
进入soft目录: cd /opt/soft
移到完成后我在这给hadoop-2.7.7改了个名字:mv hadoop-2.7.7 hadoop2.7
5.配置环境变量
进入etc目录的profile文件:vi /etc/profile

在尾行添加如下命令:
HADOOP_HOME=/opt/soft/hadoop2.7
PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
图中多了jdk的环境变量,因为hadoop是由java编写的,配置jdk环境是必不可少的,在这里就不演示jdk的安装了
6.修改hadoop配置文件
①修改hadoop-env.sh
进入hadoop2.7目录: cd /opt/soft/hadoop2.7
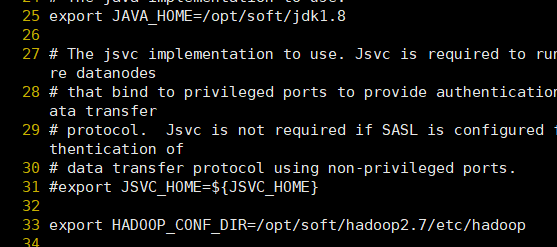
编辑配置文件hadoop-env.sh: vi etc/hadoop/hadoop-env.sh
修改25行(这里修改的是jdk的位置): export JAVA_HOME=/opt/soft/jdk1.8
修改33行(这里修改的是hadoop的位置): export HADOOP_CONF_DIR=/opt/soft/hadoop2.7/etc/hadoop
②修改core-site.xml配置文件
vi etc/hadoop/core-site.xml
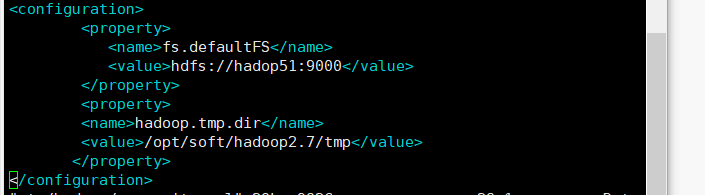
在尾末添加:
<configuration>
<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadop51:9000</value>
</property>
<!-- 指定hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/soft/hadoop2.7/tmp</value>
</property>
</configuration>
注意这里的hadop51是主机名,可以在 vi /etc/hostname中修改
③修改hdfs-site.xml配置文件
vim etc/hadoop/hdfs-site.xml

在尾末添加:
<configuration>
<!-- 指定HDFS副本的数量 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
④修改mapred-site.xml配置文件
这个配置文件一般没有,但是有个模板,名字是:mapred-site.xml.templat

我们把模板复制一遍:
进入etc目录下单hadoop文件夹: cd etc/hadoop
复制: scp mapred-site.xml.template mapred-site.xml
修改配置文件:vi mapred-site.xml

在尾末添加:
<!-- 指定mr运行在yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
⑤修改yarn-site.xml配置文件
vi yarn-site.xml
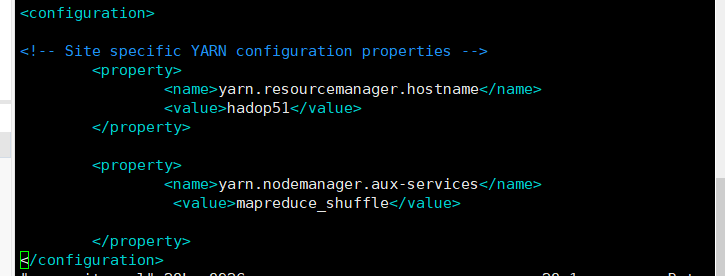
在尾末添加
<!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadop51</value>
</property>
<!-- reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
注意这里的hadop51是主机名,可以在 vi /etc/hostname中修改(和之前的一致,修改过可以省略)
⑥修改slaves文件
vi slaves

修改为自己的主机名
至此配置文件修改完毕,注意这些配置文件都在 /opt/soft/hadoop2.7/etc/hadoop目录下
7.格式化文件系统:
hadoop namenode -format
8.配置免密通信:
如果不配置免密通信每次启动Hadoop都要输入很多次密码,很麻烦。
输入命令: ssh-keygen
之后一直回车 可以看到类似图形:
在输入命令: ssh-copy-id hadop51
注意这里的hadop51是主机名
9.启动和关闭Hadoop
启动: start-all.sh
关闭: stop-all.sh
10.web端查看是否启动成功
http://192.168.31.54:50070 #查看NameNode的状态
http://192.168.31.54:50075 #查看DataNode的状态
http://192.168.31.54:50090 #查看SecondaryNameNode的状态