
一、参考
二、lucene
2.1 是什么
(1) software library for search
(2) open source
(3) not a complete application
(4) set of java classes
(5) active user and developer communities
(6) widely used, e.g, IBM and Microsoft.
2.2 架构
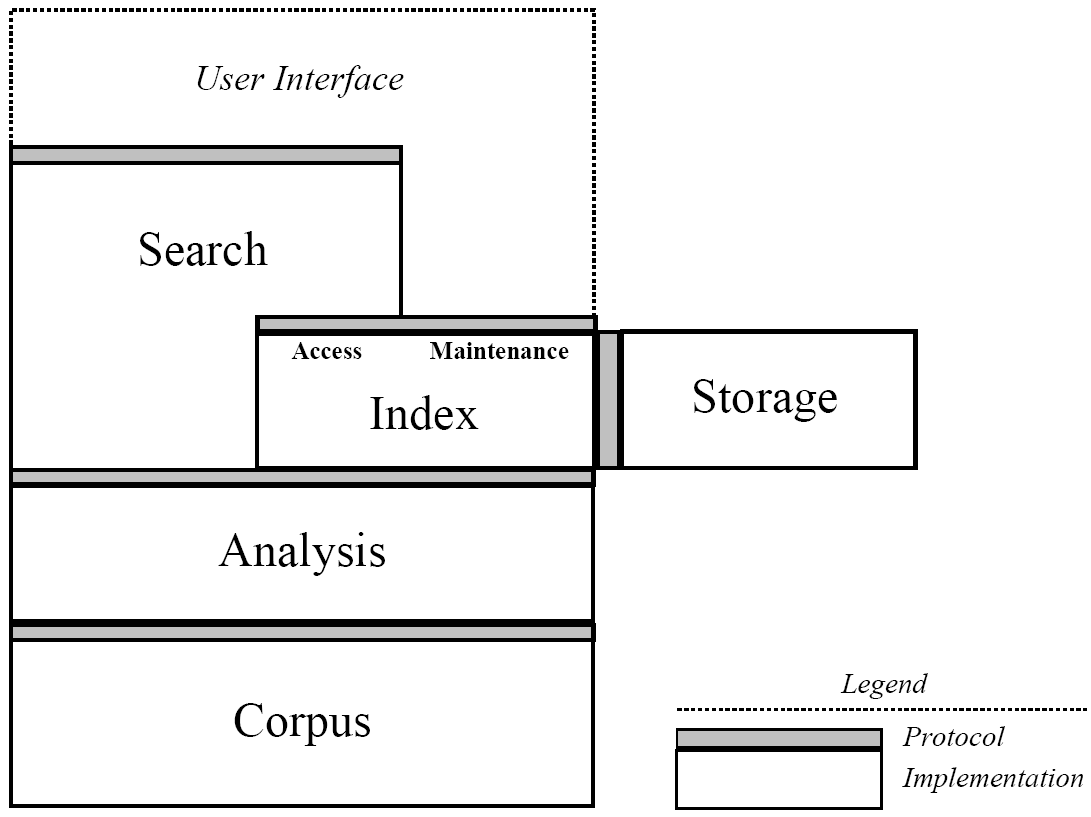
2.3 接口
(1) org.apache.lucene.document
(2) org.apache.lucene.analysis
(3) org.apache.lucene.index
(4) org.apache.lucene.search
三、document 包
3.1 document
Document: A Document is a sequence of Fields.
3.2 field
Field: A Field is a <name, value> pair.
name is the name of the field, e.g., title, body, subject, date, etc.
value is text. Field values may be stored, indexed or analyzed (and, now, vectored)
3.3 示例
public Document makeDocument(File f) throws FileNotFoundException {
Document doc = new Document();
doc.add(new Field("path", f.getPath(), Store.YES, Index.TOKENIZED));
doc.add(new Field("modified",
DateTools.timeToString(f.lastModified(), Resolution.MINUTE),
Store.YES, Index.UN_TOKENIZED));
// Reader implies Store.NO and Index.TOKENIZED
doc.add(new Field("contents", new FileReader(f)));
return doc;
}

四、analysis 包
4.1 Analyzer
An Analyzer is a TokenStream factory.
4.2 TokenStream
A TokenStream is an iterator over Tokens.
input is a character iterator (Reader)
4.3 Token
A Token is tuple <text, type, start, length, positionIncrement>
text (e.g., “pisa”).
type (e.g., “word”, “sent”, “para”).
start & length offsets, in characters (e.g, <5,4>)
positionIncrement (normally 1)
4.4 实现
standard TokenStream implementations are:
Tokenizers, which divide characters into tokens and
TokenFilters, e.g., stop lists, stemmers, etc.
4.5 示例
public class ItalianAnalyzer extends Analyzer {
private Set stopWords = StopFilter.makeStopSet(new String[] {"il", "la", "in"};
public TokenStream tokenStream(String fieldName, Reader reader) {
TokenStream result = new WhitespaceTokenizer(reader);
result = new LowerCaseFilter(result);
result = new StopFilter(result, stopWords);
result = new SnowballFilter(result, "Italian");
return result;
}
}
五、index 包
5.1 Term
Term is <fieldName, text>
5.2 Maps
index maps Term → <df, <docNum,
e.g., “content:pisa” → <2, <2, <14>>, <4, <2, 9>>>
<
2, // df
<2, <14>>, // <docNum, <position>
<4, <2, 9>> // <docNum, <position>
>
5.3 示例
IndexWriter writer = new IndexWriter("index", new ItalianAnalyzer());
File[] files = directory.listFiles();
for (int i = 0; i < files.length; i++) {
writer.addDocument(makeDocument(files[i]));
}
writer.close();
六、倒排索引策略
6.1 batch-based
Some Inverted Index Strategies
use file-sorting algorithms (textbook)
fastest to build
fastest to search
slow to update
6.2 b-tree based
b-tree based: update in place
optimizations for dynamic inverted index maintenance
fast to search
update/build does not scale
complex implementation
6.3 segment based
segment based: lots of small indexes (Verity)
fast to build
fast to update
slower to search
七、Index Algorithm
7.1 two basic algorithms
two basic algorithms:
-
make an index for a single document
-
merge a set of indices
7.2 incremental algorithm
maintain a stack of segment indices
create index for each incoming document
push new indexes onto the stack
let b=10 be the merge factor; M=∞
for (size = 1; size < M; size *= b) {
if (there are b indexes with size docs on top of the stack) {
pop them off the stack;
merge them into a single index;
push the merged index onto the stack;
} else {
break;
}
}
7.3 optimization
single-doc indexes kept in RAM, saves system calls
7.4 notes
(1) average b*logb(N)/2 indexes
N=1M, b=2 gives just 20 indexes
fast to update and not too slow to search
(2) batch indexing w/ M=∞, merge all at end
equivalent to external merge sort, optimal
(3) segment indexing w/ M<∞
7.5 diagram
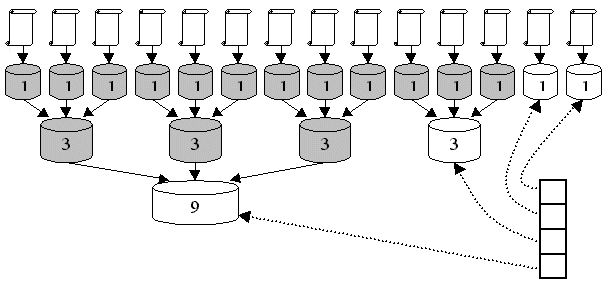
b = 3
11 documents indexed
stack has four indexes
grayed indexes have been deleted
5 merges have occurred
八、Compression
8.1 keys
For keys in Term -> ... map

8.2 values
For values in Term -> ... map

8.3 VInt 示例
VInt Encoding Example

九、search 包
9.1 primitive queries
primitive queries:
(1) TermQuery: match docs containing a Term
(2) PhraseQuery: match docs w/ sequence of Terms
(3) BooleanQuery: match docs matching other queries.
e.g., +path:pisa +content:“Doug Cutting” -path:nutch
9.2 derived queries
PrefixQuery,
WildcardQuery,
etc.
9.3 new
SpansQuery
9.4 示例
Query pisa = new TermQuery(new Term("content", "pisa"));
Query babel = new TermQuery(new Term("content", "babel"));
PhraseQuery leaningTower = new PhraseQuery();
leaningTower.add(new Term("content", "leaning"));
leaningTower.add(new Term("content", "tower"));
BooleanQuery query = new BooleanQuery();
query.add(leaningTower, Occur.MUST);
query.add(pisa, Occur.SHOULD);
query.add(babel, Occur.MUST_NOT);
9.5 Search Algorithms

9.6 Disjunctive Search Algorithm
described in
space optimizations for total ranking
since all postings must be processed:
goal is to minimize per-posting computation
merges postings through a fixed-size array of accumulator buckets
performs boolean logic with bit masks
scales well with large queries
9.7 conjunctive search algorithm

Algorithm:
use linked list of pointers to doc list
initially sorted by doc
loop
if all are at same doc, record hit
skip first to-or-past last and move to end of list
十、Scoring
10.1 similarity

10.2 Phrase Scoring
approximate phrase IDF with sum of terms
compute actual tf of phrase
slop penalizes slight mismatches by edit-distance