
一、参考
二、doc values
2.1 倒排索引的优势
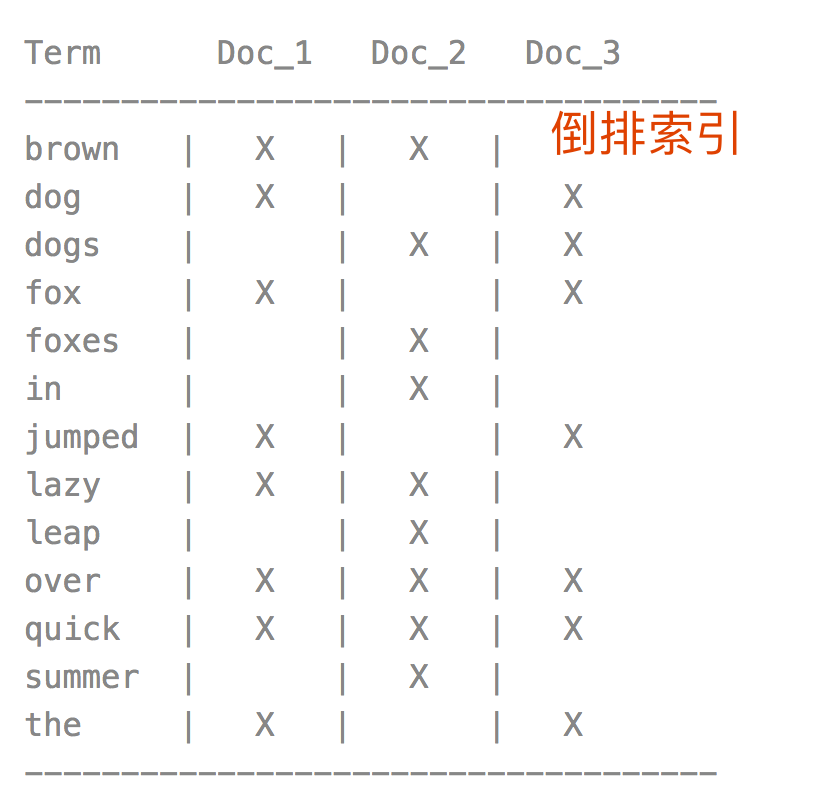
在于查找包含某个项的文档, 搜索使用倒排索引查找文档
2.2 数据结构

聚合使用一个叫 doc values 的数据结构, 倒排索引将词项映射到包含它们的文档,doc values 将文档映射到它们包含的词项
2.3 使用场景
Doc values 可以使聚合更快、更高效并且内存友好, 任何需要查找某个文档包含的值的操作都必须使用它。
Doc values 的存在是因为倒排索引只对某些操作是高效的
(1) 聚合操作收集和聚合 doc values 里的数据
(2) 排序
(3) 访问字段值的脚本
(4) 父子关系处理
2.4 写入
Doc Values 是在索引时与 倒排索引 同时生成, 也就是说 Doc Values 和 倒排索引 一样,基于 Segement 生成并且是不可变的
同时 Doc Values 和 倒排索引 一样序列化到磁盘,这样对性能和扩展性有很大帮助
Doc Values 本质上是一个序列化的 列式存储, 列式存储 适用于聚合、排序、脚本等操作
2.5 内存使用
Doc Values 通过序列化把数据结构持久化到磁盘,我们可以充分利用操作系统的内存,而不是 JVM 的 Heap
(1)当 working set 远小于系统的可用内存,系统会自动将 Doc Values 驻留在内存中,使得其读写十分快速
(2)当 working set 远大于可用内存时,系统会根据需要从磁盘读取 Doc Values,然后选择性放到分页缓存中
很显然,这样性能会比在内存中差很多,但是它的大小就不再局限于服务器的内存了。如果是使用 JVM 的 Heap 来实现那么只能是因为 OutOfMemory 导致程序崩溃了。
2.6 禁用
可以通过禁用特定字段的 Doc Values 。这样不仅节省磁盘空间,也许会提升索引的速度
Doc Values 默认对所有字段启用,除了 analyzed strings
也就是下面的数据,都会默认开启
(1) 数字
(2) 地理坐标
(3) 日期
(4) IP
(5) 不分析( not_analyzed )字符类型
因为 Doc Values 默认启用,你可以选择对你数据集里面的大多数字段进行聚合和排序操作
# (1) 创建索引,指定字段 session_id 只能查询(默认index: true),不保存doc values(doc_values: false, 默认值为true)
PUT yz_index
{
"mappings": {
"properties": {
"session_id": {
"type": "keyword",
"doc_values": false
}
}
}
}
# (2) 写入数据
POST yz_index/_doc
{
"session_id": "5f6dcd9221d20b41e16149cca96bfa20"
}
# (3) 查询正常
GET yz_index/_search
# 查询返回
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "yz_index",
"_type" : "_doc",
"_id" : "LQ-tYHcB0oopJCSjEmVl",
"_score" : 1.0,
"_source" : {
"session_id" : "5f6dcd9221d20b41e16149cca96bfa20"
}
}
]
}
}
# (4) 因为没有doc_values, 导致聚合失败
GET yz_index/_search
{
"aggs": {
"NAME": {
"terms": {
"field": "session_id",
"size": 10
}
}
}
}
# 聚合请求的返回值
{
"error" : {
"root_cause" : [
{
"type" : "illegal_argument_exception",
"reason" : "Can't load fielddata on [session_id] because fielddata is unsupported on fields of type [keyword]. Use doc values instead."
}
],
"type" : "search_phase_execution_exception",
"reason" : "all shards failed",
"phase" : "query",
"grouped" : true,
"failed_shards" : [
{
"shard" : 0,
"index" : "yz_index",
"node" : "Pclb86mySAOhJbGbQ7Rj3g",
"reason" : {
"type" : "illegal_argument_exception",
"reason" : "Can't load fielddata on [session_id] because fielddata is unsupported on fields of type [keyword]. Use doc values instead."
}
}
],
"caused_by" : {
"type" : "illegal_argument_exception",
"reason" : "Can't load fielddata on [session_id] because fielddata is unsupported on fields of type [keyword]. Use doc values instead.",
"caused_by" : {
"type" : "illegal_argument_exception",
"reason" : "Can't load fielddata on [session_id] because fielddata is unsupported on fields of type [keyword]. Use doc values instead."
}
}
},
"status" : 400
}
三、 fielddata
3.1 数据结构
doc values 不生成分析的字符串,然而,这些字段仍然可以使用聚合,那怎么可能呢?
答案是一种被称为 fielddata 的数据结构
3.2 存储
与 doc values 不同,
fielddata 构建和管理 100% 在内存中,常驻于 JVM 内存堆;
fielddata 结构不会在索引时创建。相反,它是在查询运行时,动态填充;
这意味着它本质上是不可扩展的,有很多边缘情况下要提防
3.3 高基数内存的影响
(High-Cardinality Memory Implications)
避免分析字段的另外一个原因就是:高基数字段在加载到 fielddata 时会消耗大量内存。
分析的过程会经常(尽管不总是这样)生成大量的 token,这些 token 大多都是唯一的。
这会增加字段的整体基数并且带来更大的内存压力
3.4 查看使用情况
# (1) 创建索引,启用fielddata(默认text类型字段,)
PUT yz_index
{
"settings": {
"number_of_replicas": 0
},
"mappings": {
"properties": {
"f1": {
"type": "text",
"fielddata": true
}
}
}
}
# (2) 查看索引的fielddata 缓存数据,此时刚创建索引,没有查询,所有缓存数据为0
GET yz_index/_stats/fielddata?pretty&human
# 返回值
{
"_shards" : {
"total" : 1,
"successful" : 1,
"failed" : 0
},
"_all" : {
"primaries" : {
"fielddata" : {
"memory_size" : "0b",
"memory_size_in_bytes" : 0,
"evictions" : 0
}
},
"total" : {
"fielddata" : {
"memory_size" : "0b",
"memory_size_in_bytes" : 0,
"evictions" : 0
}
}
},
"indices" : {
"yz_index" : {
"uuid" : "fmWv-YKhRG2uAnMBbxQHyg",
"primaries" : {
"fielddata" : {
"memory_size" : "0b",
"memory_size_in_bytes" : 0,
"evictions" : 0
}
},
"total" : {
"fielddata" : {
"memory_size" : "0b",
"memory_size_in_bytes" : 0,
"evictions" : 0
}
}
}
}
}
# (3)添加文档
POST yz_index/_doc
{
"f1": "hello world"
}
POST yz_index/_doc
{
"f1": "hello sunshine"
}
# (4)聚合查询
GET yz_index/_search
{
"size": 0,
"aggs": {
"NAME": {
"terms": {
"field": "f1",
"size": 10
}
}
}
}
# 聚合查询返回值
{
"took" : 604,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"NAME" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "hello",
"doc_count" : 2
},
{
"key" : "sunshine",
"doc_count" : 1
},
{
"key" : "world",
"doc_count" : 1
}
]
}
}
}
# (5)再次查看fielddata内存使用
GET yz_index/_stats/fielddata?pretty&human
# 返回值,因为已经有聚合查询,使用到fielddata,所以fielddata有内存占用
{
"_shards" : {
"total" : 1,
"successful" : 1,
"failed" : 0
},
"_all" : {
"primaries" : {
"fielddata" : {
"memory_size" : "520b",
"memory_size_in_bytes" : 520,
"evictions" : 0
}
},
"total" : {
"fielddata" : {
"memory_size" : "520b",
"memory_size_in_bytes" : 520,
"evictions" : 0
}
}
},
"indices" : {
"yz_index" : {
"uuid" : "fmWv-YKhRG2uAnMBbxQHyg",
"primaries" : {
"fielddata" : {
"memory_size" : "520b",
"memory_size_in_bytes" : 520,
"evictions" : 0
}
},
"total" : {
"fielddata" : {
"memory_size" : "520b",
"memory_size_in_bytes" : 520,
"evictions" : 0
}
}
}
}
}
3.5 默认大小与更新
# (1) 查看默认 fielddata 配置
GET _cluster/settings?include_defaults&flat_settings
# 返回值中包含fielddata部分
{
"defaults": {
"indices.breaker.fielddata.limit": "40%",
"indices.breaker.fielddata.overhead": "1.03",
"indices.breaker.fielddata.type": "memory",
"indices.fielddata.cache.size": "-1b"
}
}
(1) indices.fielddata.cache.size
控制为 fielddata 分配的堆空间大小, 默认情况下,设置都是 unbounded ,Elasticsearch 永远都不会从 fielddata 中回收数据
当你发起一个查询,分析字符串的聚合将会被加载到 fielddata,如果这些字符串之前没有被加载过
fielddata 不是临时缓存。它是驻留内存里的数据结构,必须可以快速执行访问,而且构建它的代价十分高昂。如果每个请求都重载数据,性能会十分糟糕
不过如果采用默认设置,旧索引的 fielddata 永远不会从缓存中回收! fieldata 会保持增长直到 fielddata 发生断熔,这样我们就无法载入更多的 fielddata。
为了防止发生这样的事情,可以通过在 config/elasticsearch.yml 文件中增加配置为 fielddata 设置一个上限:
indices.fielddata.cache.size: 20%
注意:无法动态配置 cache size
# 无法动态配置 cache size
PUT /_cluster/settings
{
"persistent" : {
"indices.fielddata.cache.size" : "20%"
}
}
# 返回值
{
"error" : {
"root_cause" : [
{
"type" : "illegal_argument_exception",
"reason" : "persistent setting [indices.fielddata.cache.size], not dynamically updateable"
}
],
"type" : "illegal_argument_exception",
"reason" : "persistent setting [indices.fielddata.cache.size], not dynamically updateable"
},
"status" : 400
}
(2) indices.breaker.fielddata.limit
fielddata 断路器默认设置堆的 40% 作为 fielddata 大小的上限
断路器的限制可以在文件 config/elasticsearch.yml 中指定,可以动态更新一个正在运行的集群:
# 动态配置fielddata熔断器的数值
PUT /_cluster/settings
{
"persistent" : {
"indices.breaker.fielddata.limit" : "41%"
}
}
3.6 过滤
3.7 慎重使用
Most users who want to do more with text fields use multi-field mappings by having both a text field for full text searches, and an unanalyzed keyword field for aggregations, as follows
PUT my-index-000001
{
"mappings": {
"properties": {
"my_field": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword"
}
}
}
}
}
}