系统调用的三层机制
用户态、内核态和中断
- 用户态。较低的执行级别,只能访问一部分内存,只能执行一部分指令。
- 内核态。高级执行级别,可以访问任意物理内存,可以执行特权指令。
- 中断。系统从用户态进入内核态的主要方式。有硬件中断和软中断。系统调用就是通过软中断进入内核态。
上下文切换
用户态切换到内核态时,就要把用户态寄存器上下文保存起来,同时要把内核态寄存器的值放到当前cpu中。int指令出发中断机制会在堆栈上保存一些寄存器的值,会保存(SAVE_ALL)用户态栈顶的值,当时的状态字(flag),当时的CS:EIP的值。同时会将内核态的这些寄存器的值加载到cpu。其中内核态CS:EIP指向中断处理程序的入口,如果是系统调用则指向system_call,当中断结束后执行restore_all和INTERRUPT_RETURN。
API和系统调用
API就是系统调用的库函数,是一个函数定义。系统调用是通过软中断向内核发出了中断请求,int指令的执行就会触发一个中断请求,一个API可能只对应一个系统调用,也可能由多个系统调用实现。
Linux中通过int $0x80来触发系统调用的执行,内核给每个系统调用一个编号,即系统调用号来指明是哪个系统调用,通过EAX寄存器传递。
无参数系统调用
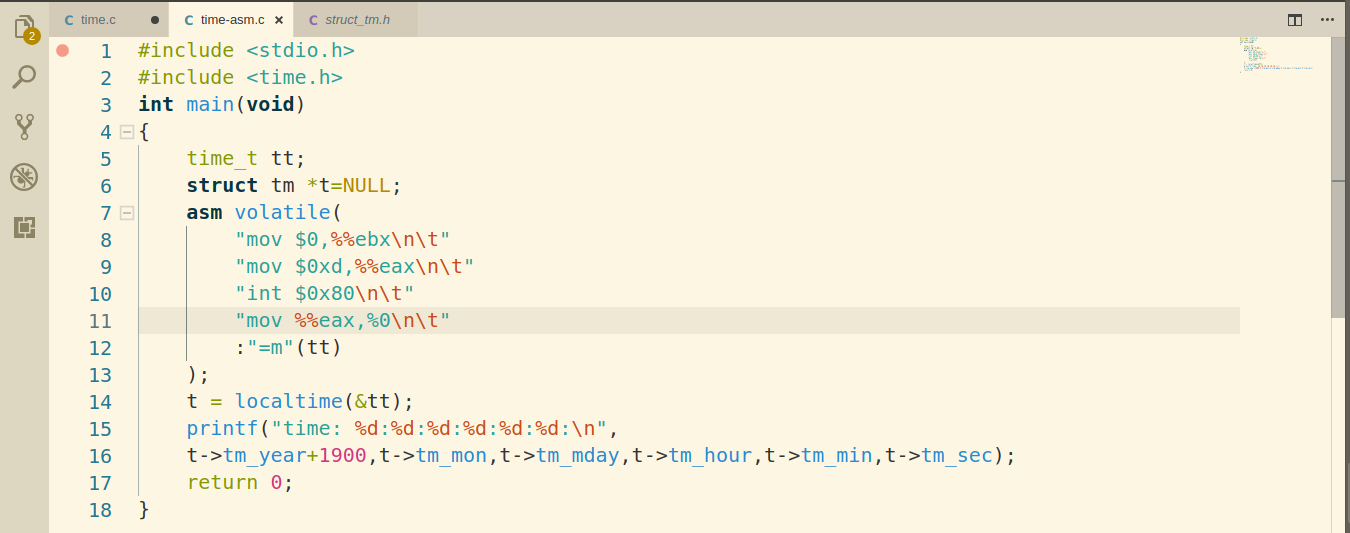
依次通过c语言和内嵌汇编的c语言实现time()函数中封装的系统调用。
time.c
课本上给出的time.c在编译时遇到如下问题:

查看struct tm发现应该是mday:
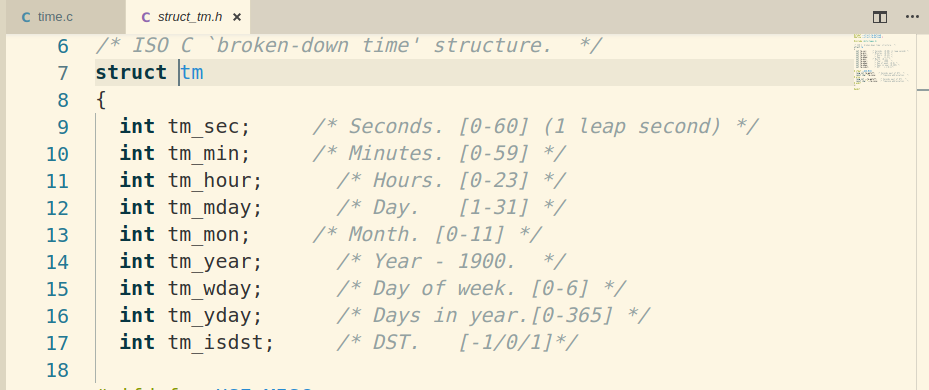
修改后代码如下:

修改后顺利运行:

内嵌汇编的代码运行顺利:

自选系统调用access
其实没什么大区别,C语言代码及运行结果如图:


内嵌汇编的代码及运行结果如图,比c语言代码有所简化:


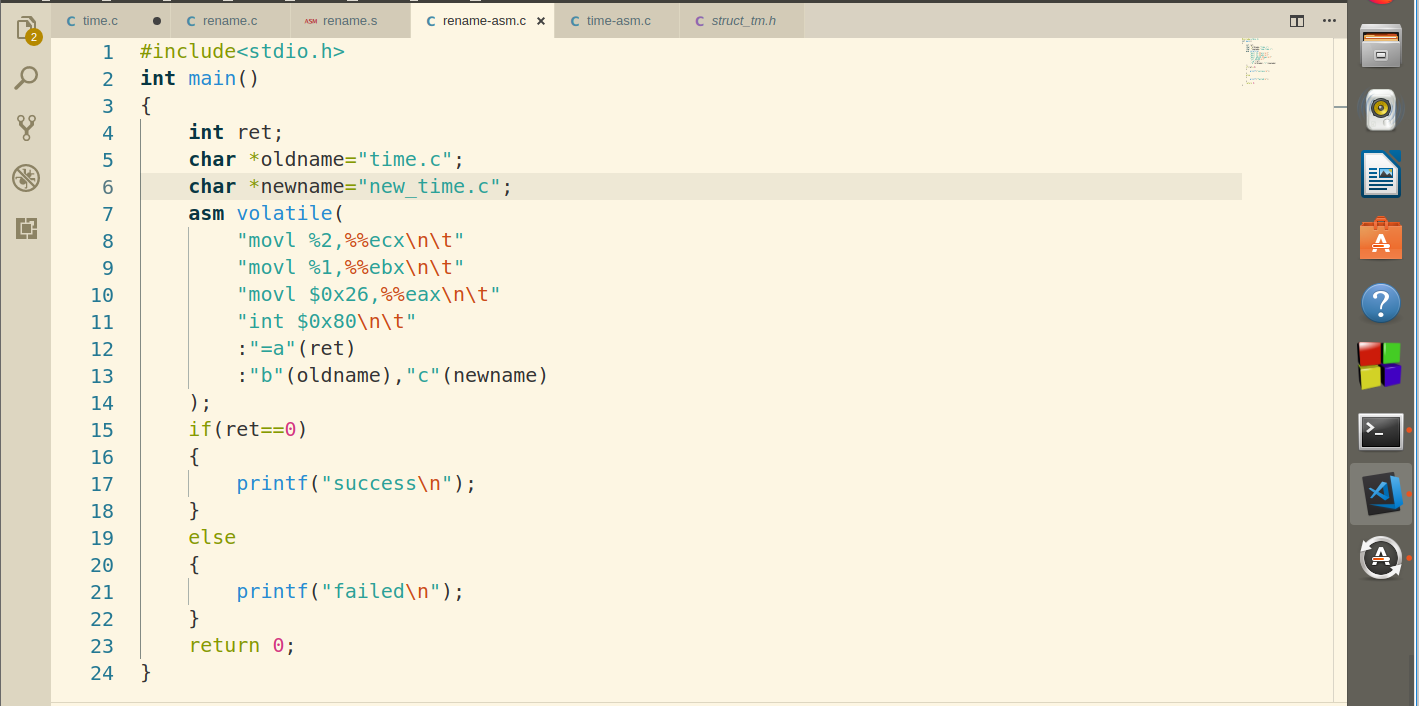
带两个参数的系统调用
同样运行顺利,代码如下:
通用库函数syscall
新增的没有被封装好的系统调用可以通过syscall(系统调用号,参数表)实现,实际上比前两种方式舒服很多。
于是我们需要知道系统调用对应的系统调用号,在编译器中通过查看syscall.h中引用的unistd.h文件可以查看系统定义的系统调用号表。

至于为什么unistd.h中的宏定义的变量名和我们使用的不一样,是因为在bits/syscall.h中又进行了一次宏定义:

这样应该更有益于程序的可读性和不同版本的兼容性(兼容性是官方的解释,但我现在对不同版本之间的兼容不报什么希望)。

感想
在查看系统调用号表时,实际上系统中有大量的unistd.h,包括i386、x86_64安装过的mykernel和Linuxkernel以及许多不知道来源的。通常是在/usr/include/asm目录下,但在我的电脑上甚至没有asm这个目录。还好编译器中链接到的文件是在搜索目录中的,所以能比较快的找到需要的头文件。
之前在编程中要用到系统中的命令都是由system(command)实现,现在想来这应该是通过shell的封装来调用的系统函数,效率应该比直接在程序中进行系统调用低不少。
一个小问题
这章之后对Linux系统的层次似乎多了些理解。按照我的理解,内核处于最底层,c语言中的系统调用和shell中的内建命令都是通过调用内核中的函数实现,是对内核中的函数的不同的封装。C语言中syscall()是直接调用内核中的函数,而C语言中的system()函数则是通过调用shell间接的调用内核中的函数,所以命令可以和终端中的写法保持一致,传参也是直接传字符串。希望这么理解是对的,在以后的实践中去检验。