一、什么是Avro?
1. Avro是一种远程过程调用和数据序列化框架,是在Apache的Hadoop项目之内开发的
2. 它使用JSON来定义数据类型和通讯协议,使用压缩二进制格式来序列化数据
3. 它主要用于Hadoop,它可以为持久化数据提供一种序列化格式,并为Hadoop节点间及从客户端程序到Hadoop服务的通讯提供一种电报格式
通过avro,每次进行序列化,根据模式(schema)文件来序列化,可以提高性能
二、特点
1. 丰富的数据结构类型,8种基本数据类型以及6种复杂类型
2. 快速可压缩的二进制形式
3. 提供容器文件用于持久化数据
4. 远程过程调用RPC框架
简单的动态语言结合功能,Avro 和动态语言结合后,读写数据文件和使用 RPC协议都不需要生成代码,而代码生成作为一种可选的优化只值得在静态类型语言中实现。而代码生成作为一种可选的优化只值得在静态类型语言中实现
三、创建maven工程,准备pom.xml文件
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.blb</groupId>
<artifactId>avro</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>jar</packaging>
<dependencies>
<dependency>
<groupId>org.apache.avro</groupId>
<artifactId>avro</artifactId>
<version>1.8.2</version>
</dependency>
<dependency>
<groupId>org.apache.avro</groupId>
<artifactId>avro-tools</artifactId>
<version>1.8.2</version>
</dependency>
<dependency>
<groupId>org.apache.avro</groupId>
<artifactId>avro-maven-plugin</artifactId>
<version>1.8.2</version>
</dependency>
<dependency>
<groupId>org.apache.avro</groupId>
<artifactId>avro-compiler</artifactId>
<version>1.8.2</version>
</dependency>
<dependency>
<groupId>org.apache.avro</groupId>
<artifactId>avro-ipc</artifactId>
<version>1.8.2</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<!-- 一般而言,target与source是保持一致的,但是,有时候为了让程序能在其他版本的jdk中运行(对于低版本目标jdk,源代码中不能使用低版本jdk中不支持的语法),会存在target不同于source的情况 -->
<source>1.8</source> <!-- 源代码使用的JDK版本 -->
<target>1.8</target> <!-- 需要生成的目标class文件的编译版本 -->
<encoding>UTF-8</encoding><!-- 字符集编码 -->
</configuration>
</plugin>
<plugin>
<groupId>org.apache.avro</groupId>
<artifactId>avro-maven-plugin</artifactId>
<version>1.8.2</version>
<executions>
<execution>
<phase>generate-sources</phase>
<goals>
<goal>schema</goal>
</goals>
<configuration>
<sourceDirectory>${project.basedir}/src/main/avro/</sourceDirectory>
<outputDirectory>${project.basedir}/src/main/java/</outputDirectory>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
</plugins>
</build>
</project>
四、定义avro的scheme
Avro scheme是通过JSON形式来定义的,一般以.avsc结尾(maven插件会去指定目录下获取.avsc结尾的文件并生成成Java文件)。
4.1 在src/main目录下新建一个avro文件夹
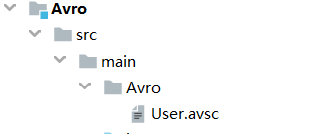
4.2 在src/main/avro目录下新建一个文件,并保存为User.avsc
{ "namespace":"com.blb", "type":"record", "name":"User", "fields": [ {"name":"username","type":"string"}, {"name":"age","type":"int"} ] }
其中
namespace在java项目中翻译成包名
name是类名
fields就是配置的属性
注意:必须配置type为record
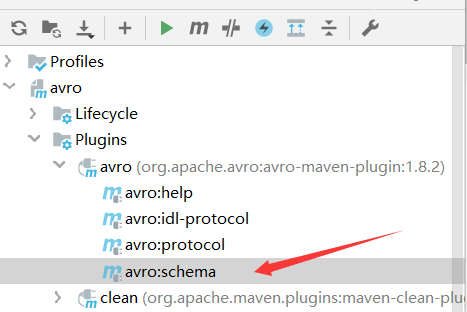
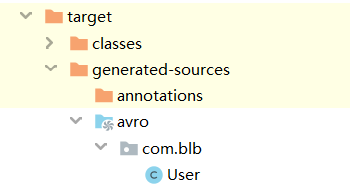
4.3 生成类
五、Java读写Avro文件,实现序列化和反序列化
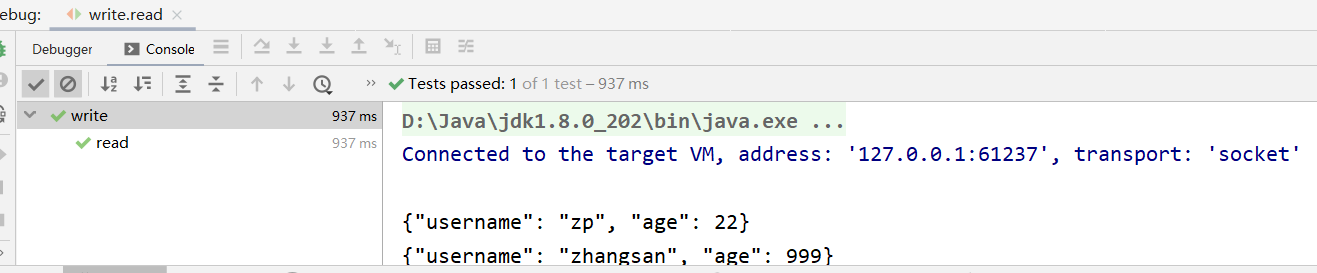
@Test public void write() throws Exception{ User u1 = new User("zp",22); User u2 = new User("zhangsan",999); DatumWriter<User> dw = new SpecificDatumWriter<>(User.class); DataFileWriter<User> dfw = new DataFileWriter<>(dw); // 创建底层的文件输出通道 // schema - 序列化类的模式 // path - 文件路径 dfw.create(u1.getSchema(),new File("d://zp.txt")); // 把对象数据写到文件中 dfw.append(u1); dfw.append(u2); dfw.close(); }
@Test public void read()throws Exception{ DatumReader<User> dr = new SpecificDatumReader<>(User.class); DataFileReader<User> dfr = new DataFileReader(new File("d://zp.txt"),dr); //--通过迭代器,迭代出对象数据 while(dfr.hasNext()){ System.out.println(dfr.next()); } }