市场对人工智能的热情持续高涨,特别是硬件领域。人工智能将成为下一个大风口,首当其冲的就包括硬件, 在图像语音识别、无人驾驶等人工智能领域的运用层面,图形处理器 (GPU)正迅速扩大市场占比,而谷歌专门为人工智能研发的TPU则被视为GPU的竞争对手。
概念
人工智能的实现需要依赖三个要素:算法是核心,硬件和数据是基础, 如下图:
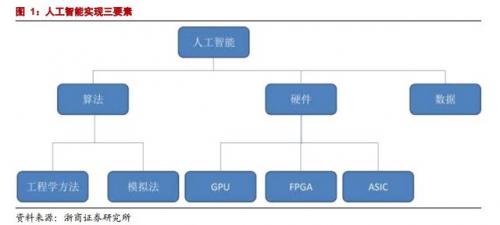
算法主要分为为工程学法和模拟法:
- 工程学方法是采用传统的编程技术,利用大量数据处理经验改进提升算法性能;
- 模拟法则是模仿人类或其他生物所用的方法或者技能,提升算法性能,例如遗传算法和神经网络。
硬件方面:目前主要是使用 GPU 并行计算神经网络
从产业结构来讲,人工智能生态分为基础、技术、应用三层
- 基础层:包括数据资源和计算能力;
- 技术层:包括算法、模型及应用开发;
- 应用层:包括人工智能+各行业(领域),比如在互联网、金融、汽车、游戏等产业应用的语音识别、人脸识别、无人机、机器人、无人驾驶等功能。
GPU:(Graphic Processing Unit 图形处理器) 英伟达(NVIDIA)制造的GPU专门用于在个人电脑、工作站、游戏机和一些移动设备上进行图像运算工作,是显示卡的“心脏”。
FPGA:半定制化芯片FPGA(FPGA)
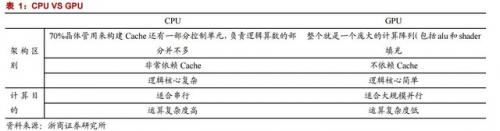
GPU与CPU的区别
本身架构方式和运算目的的不同,导致英特尔制造的CPU 和 GPU之间有所区别,如下图:
- GPU之所以能够迅速发展,主要原因是GPU针对密集的、高并行的计算,这正是图像渲染所需要的,因此 GPU 设计了更多的晶体管专用于数据处理,而非数据高速缓存和流控制。
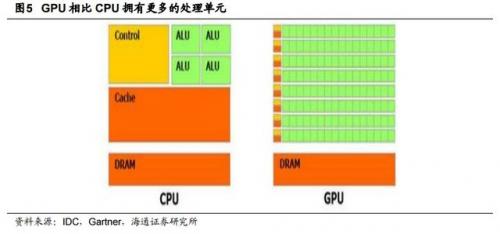
- 与CPU相比,GPU拥有更多的处理单元。
- 和CPU 上大部分面积都被缓存所占据有所不同,诸如GTX 200 GPU之类的核心内很大一部分面积都作为计算之用。如果用具体数据表示,大约估计在 CPU 上有 20%的晶体管是用作运算之用的,而(GTX 200)GPU 上有 80%的晶体管用作运算:
GPU 的处理核心 SP 基于传统的处理器核心设计,能够进行整数,浮点计算,逻辑运算等操作,从硬体设计上看就是一种完全为多线程设计的处理核心,拥有复数的管线平台设计,完全胜任每线程处理单指令的工作。
【简单的说,例如GPU要计算某个颜色的值(RGBa),就要用到浮点运算。一般在普通的图形运算中,32位单精度甚至16位半精度已经够用了。但是随着对精准效果的追求和通用运算的需求,出现了许多对精度要求极高的情况,例如解微分方程等。在这些情景中,如果精度不足,会使误差逐渐积累,导致最后的结果和精确结果相差太大,所以需要使用双精度甚至更高精度才能获得可靠的结果。高精度的运算必然导致运算速度的下降,所以一般游戏显卡都着力于提升单精度运算能力,经常看到各种宣称单精度运算能力达到多少多少,却很少提及双精度。而对于一些专业卡来说,使用者往往对运算结果的要求很高,如在物理模拟中,单精度运算很可能导致模型偏差很大,所以此时就对GPU的双精度运算能力提出了更高的要求。】
GPU 处理的首要目标是运算以及数据吞吐量,而 CPU 内部晶体管的首要目的是降低处理的延时以及保持管线繁忙,这也决定了 GPU 在密集型计算方面比起 CPU 来更有优势。
GPU+CPU异构运算
就目前来看,GPU不是完全代替CPU,而是两者分工合作。
在 GPU 计算中 CPU 和 GPU 之间是相连的,而且是一个异构的计算环境。这就意味着应用程序当中,顺序执行这一部分的代码是在 CPU 里面进行执行的,而并行的也就是计算密集这一部分是在 GPU 里面进行。
异构运算(heterogeneous computing)是通过使用计算机上的主要处理器,如CPU 以及 GPU 来让程序得到更高的运算性能。一般来说,CPU 由于在分支处理以及随机内存读取方面有优势,在处理串联工作方面较强。在另一方面,GPU 由于其特殊的核心设计,在处理大量有浮点运算的并行运算时候有着天然的优势。完全使用计算机性能实际上就是使用 CPU 来做串联工作,而 GPU 负责并行运算,异构运算就是“使用合适的工具做合适的事情”。
只有很少的程序使用纯粹的串联或者并行的,大部分程序同时需要两种运算形式。编译器、文字处理软件、浏览器、e-mail 客户端等都是典型的串联运算形式的程序。而视频播放,视频压制,图片处理,科学运算,物理模拟以及 3D 图形处理(Ray tracing 及光栅化)这类型的应用就是典型的并行处理程序。
GPU的运用
正是因为GPU特别适合大规模并行运算的特点,因此,“GPU 在深度学习领域发挥着巨大的作用”。
GPU可以平行处理大量琐碎信息。深度学习所依赖的是神经系统网络——与人类大脑神经高度相似的网络——而这种网络出现的目的,就是要在高速的状态下分析海量的数据。例如,如果你想要教会这种网络如何识别出猫的模样,你就要给它提供无数多的猫的图片。而这种工作,正是 GPU 芯片所擅长的事情。 而且相比于 CPU,GPU 的另一大优势,就是它对能源的需求远远低于 CPU。GPU 擅长的是海量数据的快速处理。
深度学习令 NVIDIA 业绩加速增长,利用 GPU 的大规模并行处理能力来学习人工智能算法再合适不过,GPU 并行计算能力正在渗透一个又一个高精尖行业,推动GPU 的需求不断增长。移动端,不论是当前火热的移动直播,还是移动 VR 设备,基于图形处理的需求都在急剧爆发。目前移动市场的 GPU 还远远落后于 PC 端,市场被高通、ARM、imagination 等三大巨头占据。
GPU的劣势
不过,GPU也有不足之处。
虽然GPU更擅长于类似图像处理的并行计算,因为像素与像素之间相对独立,GPU 提供大量的核,可以同时对很多像素进行并行处理。但是,这并不能带来延迟的提升(而仅仅是处理吞吐量的提升)。比如,当一个消息到达时,虽然 GPU 有很多的核,但只能有其中一个核被用来处理当前这个消息,而且 GPU 核通常被设计为支持与图像处理相关的运算,不如 CPU 通用。
GPU 主要适用于在数据层呈现很高的并行特性(data-parallelism)的应用,比如 GPU 比较适合用于类似蒙特卡罗模拟这样的并行运算。
GPU 的另外一个问题是,它的“确定性”不如可编程的硅芯片FPGA,相对较容易产生计算错误。
TPU
TPU:即谷歌的张量处理器——Tensor Processing Unit。
据谷歌工程师Norm Jouppi介绍,TPU是一款为机器学习而定制的芯片,经过了专门深度机器学习方面的训练,它有更高效能(每瓦计算能力)。大致上,相对于现在的处理器有7年的领先优势,宽容度更高,每秒在芯片中可以挤出更多的操作时间,使用更复杂和强大的机器学习模型,将之更快的部署,用户也会更加迅速地获得更智能的结果。
谷歌专门为人工智能研发的TPU被疑将对GPU构成威胁。不过谷歌表示,其研发的TPU不会直接与英特尔或NVIDIA进行竞争。
据谷歌介绍,TPU已在谷歌的数据中心运行了一年多,表现非常好。谷歌的很多应用都用到了TPU,比如谷歌街景,以及AlphaGo等。
TPU最新的表现正是人工智能与人类顶级围棋手的那场比赛。在AlphaGo战胜李世石的系列赛中,TPU能让AlphaGo“思考”更快,“想”到更多棋招、更好地预判局势。