一.requests介绍
1.介绍:使用requests可以模拟浏览器的请求,比起之前用到的urllib,requests模块的api更加便捷(本质就是封装了urllib3)
2.注意:requests库发送请求将网页内容下载下来以后,并不会执行js代码,这需要我们自己分析目标站点然后发起新的request请求
3.安装:pip3 install requests
4.各种请求方式:常用的就是requests.get()和requests.post()
>>> import requests
>>> r = requests.get('https://api.github.com/events')
>>> r = requests.post('http://httpbin.org/post', data = {'key':'value'})
>>> r = requests.put('http://httpbin.org/put', data = {'key':'value'})
>>> r = requests.delete('http://httpbin.org/delete')
>>> r = requests.head('http://httpbin.org/get')
>>> r = requests.options('http://httpbin.org/get')
二.请求
get请求
1. get基本使用
#1.导入模块 import requests #2.发送请求 response = requests.get("http://dig.chouti.com/") #获取相应数据并处理 print(response.text)
2.传送 parmas参数
如果拼接的数据是中文或特殊符号,则必须进行url编码
方式1:
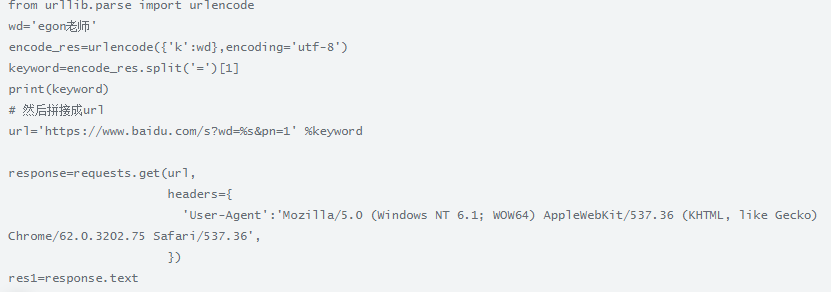
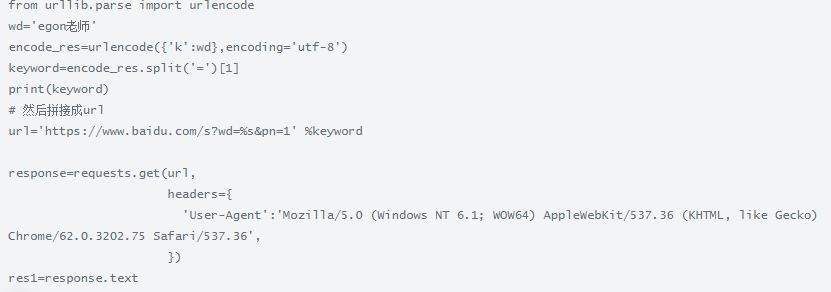
res = urlencode({"k":wd},encoding='utf-8')
print(res,type(res)) # k=egon%E8%80%81%E5%B8%88 <class 'str'>
方式2:、
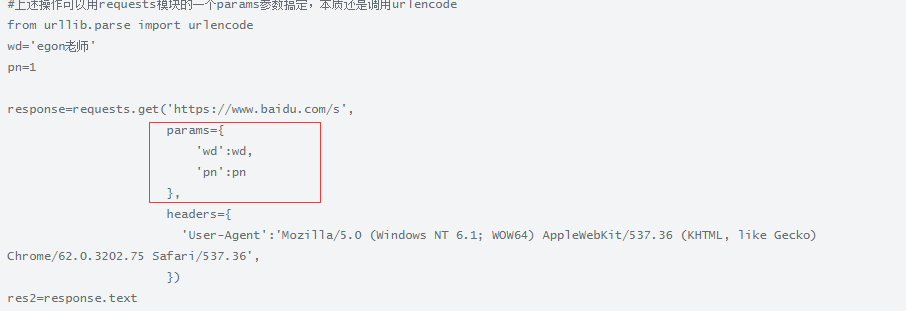
3.header


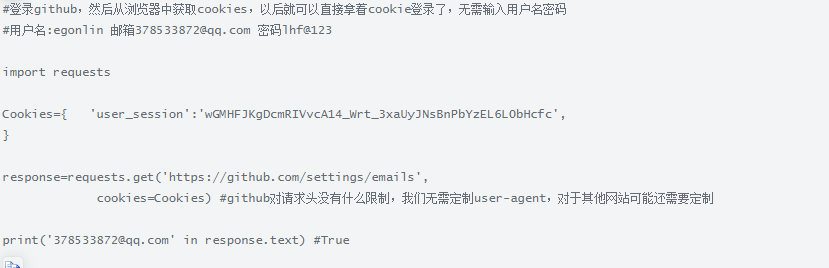
4.cookies
post请求
1.介绍

2.使用
response = requests.post(url, data = data, headers=headers)
三.响应



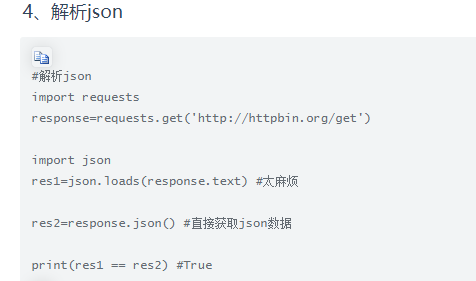
5.高级用法
https://www.cnblogs.com/xiaoyuanqujing/articles/11805698.html