引用自:https://zhuanlan.zhihu.com/p/139898040
代码位置:
https://github.com/google-research/electra
1、概述
在 2019 年 11 月份,NLP 大神 Manning 联合谷歌做的 ELECTRA 一经发布,迅速火爆整个 NLP 圈,其中 ELECTRA-small 模型参数量仅为 BERT-base 模型的 1/10,性能却依然能与 BERT、RoBERTa 等模型相媲美,得益于 ELECTRA 模型的巧妙构思 LOSS,在 2020 年 3 月份 Google 对代码做了开源,下面针对 Google 放出的 ELECTRA 做代码做解读,希望通过此文章大家能在自己文本数据、行为序列数据训练一个较好的预训练模型,在业务上提升价值。
2、ELECTRA 模型
2、1 总体框架
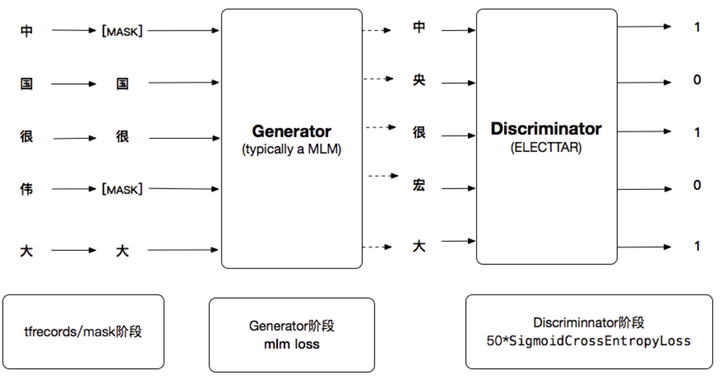
ELECTRA 模型(BASE 版本)本质是换一种方法来训练 BERT 模型的参数;BERT 模型主要是利用 MLM 的思想来训练参数,直接把需要预测的词给挖掉了,挖了 15%的比例。由于每次训练是一段话中 15%的 token,导致模型收敛更新较慢,需要的语料也比较庞大。同时为了兼顾处理阅读理解这样的任务,模型加入了 NSP,是个二分类任务,判断上下两句是不是互为上下句;而 ELECTRA 模型主要借助于图像领域 gan 的思想,利用生成器和判别器思想,如下图所;ELECTRA 的预训练可以分为两部分,生成器部分仍然是 MLM,结构与 BERT 类似,利用这个模型对挖掉的 15%的词进行预测,并将其进行替换,若替换的词不是原词,则打上被替换的标签,语句的其他词则打上没有替换的标签,判别器部分是训练一个判别模型对所有位置的词进行替换识别,此时预测模型转换成了一个二分类模型。这个转换可以带来效率的提升,对所有位置的词进行预测,收敛速度会快的多,损失函数是利用生成器部分的损失和判别器的损失函数以一个比例数(官方代码是 50)相加。
2、3 pretraining 阶段
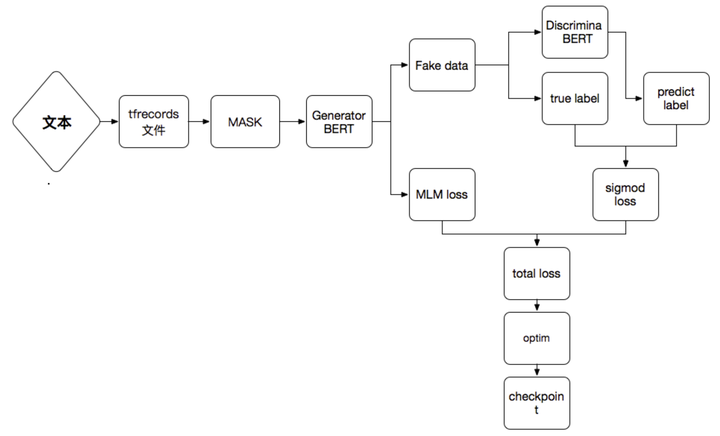
ELECTRA 模型 pretraining 阶段是最核心的逻辑,代码是在 run_pretraining.py 里面,下面会加以详细说明,整体阶段理解绘制了一张图,逻辑见如下图:
2.3.1 主方法入口
在 run_pretraining.py 文件中主方法有三个必须的参数见:
def main():
parser = argparse.ArgumentParser(description=__doc__)
parser.add_argument("--data-dir", required=True,
help="Location of data files (model weights, etc).")
parser.add_argument("--model-name", required=True,
help="The name of the model being fine-tuned.")
parser.add_argument("--hparams", default="{}",
help="JSON dict of model hyperparameters.")
args = parser.parse_args()
if args.hparams.endswith(".json"):
hparams = utils.load_json(args.hparams)
else:
hparams = json.loads(args.hparams)
tf.logging.set_verbosity(tf.logging.ERROR)
train_or_eval(configure_pretraining.PretrainingConfig(
args.model_name, args.data_dir, **hparams))三个必须参数见如下: --data-dir: 表示 tfrecord 文件的地址,一般是以 pretrain_data.tfrecord-0-of*这种格式,调用 build_pretraining_dataset.py 文件生成,默认生成 1000 个 tfrecord 文件,数目可以自己改,此外需要注意的是切词需要制定 vocab.txt,训练中文的模型词典指定 BERT 模型那个 vocab.txt 词典即可,同理用于英文的模型训练。
--model-name: 表示预训练模型的名字一般是 electar,可以自己设定。
--hparams:,一般是个 json 文件,可以传递自己的参数进去,比如你要训练的模型是 small、base、big 等模型,还有 vocab_size,一般中文是 21128,英文是 30522。还有模型训练是否是测试状态等参数,一般我训练中文模型 hparams 参数是的 config.json 是:
{
"model_size": "base",
"vocab_size": 21128
}详细的参数可以去看 configure_pretraining.py,一般你传进去的参数进去会更新里面的超参数。
程序入口训练模型:
train_or_eval(configure_pretraining.PretrainingConfig(
args.model_name, args.data_dir, **hparams))还有一个入口,只 see.run()一次,用于测试,见如下:
train_one_step(configure_pretraining.PretrainingConfig(
args.model_name, args.data_dir, **hparams))2.3.2 数据 mask
训练模型主要是代码是PretrainingModel类的定义,在 PretrainingModel 里面 程序首先对输入的 tfrecord 文件做随机 mask,
# Mask the input
masked_inputs = pretrain_helpers.mask(
config, pretrain_data.features_to_inputs(features), config.mask_prob)用于生成含有 masked_lm_positions,masked_lm_ids,masked_lm_weights 等 key 的 tfrecord 文件,随机 MASK 实现的主要逻辑是调用 pretrain_helpers.mask()来实现,其中用到了随机生成多项分布的函数 tf.random.categorical,这个函数目的是随机获取 masked_lm_positions、masked_lm_weights,再根据 masked_lm_positions 调用 tf.gather_nd 做索引截取来获取 masked_lm_ids。
2.3.3 Generator BERT
数据获取之后往下一步走就是生成 Generator BERT 阶段的模型,调用方法见如下:
generator = self._build_transformer(
masked_inputs, is_training,
bert_config=get_generator_config(config, self._bert_config),
embedding_size=(None if config.untied_generator_embeddings
else embedding_size),
untied_embeddings=config.untied_generator_embeddings,
name="generator")这里主要用于 Generator 阶段 BERT 模型生成,同时生成 MLM loss 和 Fake data,其中 Fake data 非常核心。 MLM loss 生成见代码,和 BERT 的逻辑几乎一样 :
def _get_masked_lm_output(self, inputs: pretrain_data.Inputs, model):
"""Masked language modeling softmax layer."""
masked_lm_weights = inputs.masked_lm_weights
with tf.variable_scope("generator_predictions"):
if self._config.uniform_generator:
logits = tf.zeros(self._bert_config.vocab_size)
logits_tiled = tf.zeros(
modeling.get_shape_list(inputs.masked_lm_ids) +
[self._bert_config.vocab_size])
logits_tiled += tf.reshape(logits, [1, 1, self._bert_config.vocab_size])
logits = logits_tiled
else:
relevant_hidden = pretrain_helpers.gather_positions(
model.get_sequence_output(), inputs.masked_lm_positions)
hidden = tf.layers.dense(
relevant_hidden,
units=modeling.get_shape_list(model.get_embedding_table())[-1],
activation=modeling.get_activation(self._bert_config.hidden_act),
kernel_initializer=modeling.create_initializer(
self._bert_config.initializer_range))
hidden = modeling.layer_norm(hidden)
output_bias = tf.get_variable(
"output_bias",
shape=[self._bert_config.vocab_size],
initializer=tf.zeros_initializer())
logits = tf.matmul(hidden, model.get_embedding_table(),
transpose_b=True)
logits = tf.nn.bias_add(logits, output_bias)
oh_labels = tf.one_hot(
inputs.masked_lm_ids, depth=self._bert_config.vocab_size,
dtype=tf.float32)
probs = tf.nn.softmax(logits)
log_probs = tf.nn.log_softmax(logits)
label_log_probs = -tf.reduce_sum(log_probs * oh_labels, axis=-1)
numerator = tf.reduce_sum(inputs.masked_lm_weights * label_log_probs)
denominator = tf.reduce_sum(masked_lm_weights) + 1e-6
loss = numerator / denominator
preds = tf.argmax(log_probs, axis=-1, output_type=tf.int32)
MLMOutput = collections.namedtuple(
"MLMOutput", ["logits", "probs", "loss", "per_example_loss", "preds"])
return MLMOutput(
logits=logits, probs=probs, per_example_loss=label_log_probs,
loss=loss, preds=preds)Fake data 数据生成逻辑见下面代码,这里调用了 unmask 函数和上面提到的 mask 函数作用相反,把原来 input_ids 随机 mask 的函数还原回去生成一个 input_ids_new,再利用谷生成模型生成的 logit 取最大索引去还原原来被 mask 调的 input_ids,生成一个 updated_input_ids,判断 input_ids_new 和 updated_input_ids 是否相等,生成 true label
def _get_fake_data(self, inputs, mlm_logits):
"""Sample from the generator to create corrupted input."""
inputs = pretrain_helpers.unmask(inputs)
disallow = tf.one_hot(
inputs.masked_lm_ids, depth=self._bert_config.vocab_size,
dtype=tf.float32) if self._config.disallow_correct else None
sampled_tokens = tf.stop_gradient(pretrain_helpers.sample_from_softmax(
mlm_logits / self._config.temperature, disallow=disallow))
sampled_tokids = tf.argmax(sampled_tokens, -1, output_type=tf.int32)
updated_input_ids, masked = pretrain_helpers.scatter_update(
inputs.input_ids, sampled_tokids, inputs.masked_lm_positions)
labels = masked * (1 - tf.cast(
tf.equal(updated_input_ids, inputs.input_ids), tf.int32))
updated_inputs = pretrain_data.get_updated_inputs(
inputs, input_ids=updated_input_ids)
FakedData = collections.namedtuple("FakedData", [
"inputs", "is_fake_tokens", "sampled_tokens"])
return FakedData(inputs=updated_inputs, is_fake_tokens=labels,
sampled_tokens=sampled_tokens)2.3.4 Discrimina BERT
利用上一步生成的 Fake data,作为 Discrimina BERT 的输入,见代码:
if config.electra_objective:
discriminator = self._build_transformer(
fake_data.inputs, is_training, reuse=not config.untied_generator,
embedding_size=embedding_size)
disc_output = self._get_discriminator_output(
fake_data.inputs, discriminator, fake_data.is_fake_tokens)获取二分类的损失函数,代码见:
def _get_discriminator_output(self, inputs, discriminator, labels):
"""Discriminator binary classifier."""
with tf.variable_scope("discriminator_predictions"):
hidden = tf.layers.dense(
discriminator.get_sequence_output(),
units=self._bert_config.hidden_size,
activation=modeling.get_activation(self._bert_config.hidden_act),
kernel_initializer=modeling.create_initializer(
self._bert_config.initializer_range))
logits = tf.squeeze(tf.layers.dense(hidden, units=1), -1)
weights = tf.cast(inputs.input_mask, tf.float32)
labelsf = tf.cast(labels, tf.float32)
losses = tf.nn.sigmoid_cross_entropy_with_logits(
logits=logits, labels=labelsf) * weights
per_example_loss = (tf.reduce_sum(losses, axis=-1) /
(1e-6 + tf.reduce_sum(weights, axis=-1)))
loss = tf.reduce_sum(losses) / (1e-6 + tf.reduce_sum(weights))
probs = tf.nn.sigmoid(logits)
preds = tf.cast(tf.round((tf.sign(logits) + 1) / 2), tf.int32)
DiscOutput = collections.namedtuple(
"DiscOutput", ["loss", "per_example_loss", "probs", "preds",
"labels"])2.3.5 总的损失函数
上面一步骤求出了 disc_output.loss 也就是 sigmod 的 loss,代码见:
self.total_loss = config.gen_weight * mlm_output.loss
self.total_loss += config.disc_weight * disc_output.loss这里 config.gen_weight=1 以及 config.disc_weight=50,这里 sigmod 的损失函数设置为 50,作者也没给明确的答复。
2.3.6 模型优化以及 checkpoint
上面一步已经求出了总的损失函数,下一步则是做模型优化训练以及做 checkpoint,程序入口在 train_or_eval()里面,代码见:
is_per_host = tf.estimator.tpu.InputPipelineConfig.PER_HOST_V2
tpu_cluster_resolver = None
if config.use_tpu and config.tpu_name:
tpu_cluster_resolver = tf.distribute.cluster_resolver.TPUClusterResolver(
config.tpu_name, zone=config.tpu_zone, project=config.gcp_project)
tpu_config = tf.estimator.tpu.TPUConfig(
iterations_per_loop=config.iterations_per_loop,
num_shards=(config.num_tpu_cores if config.do_train else
config.num_tpu_cores),
tpu_job_name=config.tpu_job_name,
per_host_input_for_training=is_per_host)
run_config = tf.estimator.tpu.RunConfig(
cluster=tpu_cluster_resolver,
model_dir=config.model_dir,
save_checkpoints_steps=config.save_checkpoints_steps,
tpu_config=tpu_config)
model_fn = model_fn_builder(config=config)
estimator = tf.estimator.tpu.TPUEstimator(
use_tpu=config.use_tpu,
model_fn=model_fn,
config=run_config,
train_batch_size=config.train_batch_size,
eval_batch_size=config.eval_batch_size)可以看到 google 开源的代码主要是 TPU 的一些钩子,改成 GPU 也比较简单,在 BERT 里面就有 GPU 相关的钩子,下面就会讲到。
2、4 finetuning 阶段
ELECTRA finetuning 阶段给出了不少例子,也比较简单,在 finetuneing 文件下面,这里不做过多的说明,和 bert 类似,唯一要改的就是把 TPU 相关的设置改为 GPU、CPU 即可。
2、5 序列训练改进
上面代码主要存在两个问题,第一个是 TPU 设置的问题,并不是人人都是土豪,还是要适配 GPU 的训练,第二个就是假如我想训练一个 vocab 比较大的序列模型,上面模型是训练不动的,loss 方面改为负采样的形式。
2.5.1 TPU 改 GPU 训练
global_step = tf.train.get_or_create_global_step()
optimizer = optimization.AdamWeightDecayOptimizer(learning_rate=learning_rate)
train_op = optimizer.apply_gradients(zip(grads, tvars), global_step)
update_global_step = tf.assign(global_step, global_step + 1, name='update_global_step')
output_spec=tf.estimator.EstimatorSpec(
mode=mode,
predictions=probabilities,
loss=total_loss,
train_op=tf.group(train_op, update_global_step))
run_config = tf.estimator.RunConfig(model_dir=FLAGS.modelpath,save_checkpoints_steps=500)
bert_config = modeling.BertConfig.from_json_file(FLAGS.bert_config_file)
model_fn = model_fn_builder(
bert_config=bert_config,
num_labels=FLAGS.n_class,
is_training=True,
init_checkpoint=FLAGS.init_checkpoint,
learning_rate=FLAGS.learning_rate,
use_one_hot_embeddings=False)
estimator = tf.estimator.Estimator(model_fn=model_fn, config=run_config)
total_files=glob.glob("/tf*")
random.shuffle(total_files)
eval_files=total_files.pop()
input_fn_train=lambda:input_fn(total_files,FLAGS.batch_size,num_epochs=N)
input_fn_eval=lambda:input_fn(eval_files,FLAGS.batch_size,is_training=False)
train_spec = tf.estimator.TrainSpec(input_fn=input_fn_train, max_steps=10000)
eval_spec = tf.estimator.EvalSpec(input_fn=input_fn_eval,steps=None, start_delay_secs=30, throttle_secs=30)
tf.estimator.train_and_evaluate(estimator, train_spec, eval_spec)2.5.2 负采样改造
主要是对 mlm loss 做改造:
def get_masked_lm_output(bert_config, input_tensor, output_weights, positions,
label_ids, label_weights):
with tf.variable_scope("cls/predictions"):
with tf.variable_scope("transform"):
input_tensor = tf.layers.dense(
input_tensor,
units=bert_config.hidden_size,
activation=modeling.get_activation(bert_config.hidden_act),
kernel_initializer=modeling.create_initializer(
bert_config.initializer_range))
input_tensor = modeling.layer_norm(input_tensor) #batch*10*embeding_size
# The output weights are the same as the input embeddings, but there is
# an output-only bias for each token.
output_bias = tf.get_variable(
"output_bias",
shape=[bert_config.vocab_size],
initializer=tf.zeros_initializer())
label_ids = tf.reshape(label_ids, [-1,1])
label_weights = tf.reshape(label_weights, [-1])
per_example_loss = tf.nn.sampled_softmax_loss(
weights=output_weights,
biases=output_bias,
labels=label_ids,
inputs=input_tensor,
num_sampled=N,
num_classes=bert_config.vocab_size)
numerator = tf.reduce_sum(label_weights*per_example_loss )
denominator = tf.reduce_sum(label_weights) + 1e-5
loss = numerator / denominator
return (loss, per_example_loss)3、总结
前段时间挺忙,有比较多的新 idea 出来没来的及看,上周末花了一天时间看了下 electra 源码,并做记录,也看到不少团队做了一些中文 electra 预训练模型,虽然 electra 没有达到 state of the art,和 roberta 差距可以忽视,但是这种训练方式这是一个很棒的 idea,其收敛速度是其他以 bert 为基础为改造的模型不能比的,在序列建模就有非常重大的研究意义,欢迎一起交流。