第一周:深度学习引言(Introduction to Deep Learning)
1.1 欢迎(Welcome) 1
1.2 什么是神经网络?(What is a Neural Network)
1.3 神经网络的监督学习(Supervised Learning with Neural Networks)
1.4 为什么神经网络会流行?(Why is Deep Learning taking off?)
1.5 关于本课程(About this Course)
1.6 课程资源(Course Resources)
1.7 Geoffery Hinton 专访(Geoffery Hinton interview)
第二周:神经网络的编程基础(Basics of Neural Network programming)
2.1 二分类(Binary Classification)
2.2 逻辑回归(Logistic Regression)
2.3 逻辑回归的代价函数(Logistic Regression Cost Function)
2.4 梯度下降(Gradient Descent)
2.5 导数(Derivatives)
2.6 更多的导数例子(More Derivative Examples)
2.7 计算图(Computation Graph)
2.8 计算图导数(Derivatives with a Computation Graph)
2.9 逻辑回归的梯度下降(Logistic Regression Gradient Descent)
2.10 梯度下降的例子(Gradient Descent on m Examples)
2.11 向量化(Vectorization)
2.12 更多的向量化例子(More Examples of Vectorization)
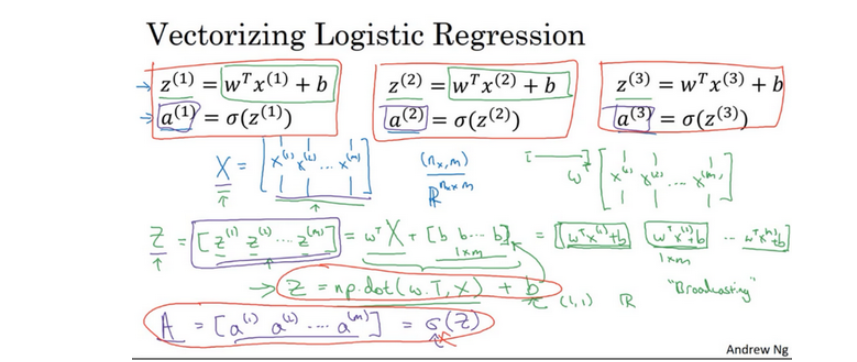
2.13 向量化逻辑回归(Vectorizing Logistic Regression)
2.14 向量化逻辑回归的梯度计算(Vectorizing Logistic Regression's Gradient)
2.15 Python中的广播机制(Broadcasting in Python)
2.16 关于 Python与numpy向量的使用(A note on python or numpy vectors)
2.17 Jupyter/iPython Notebooks快速入门(Quick tour of Jupyter/iPython Notebooks)
2.18 逻辑回归损失函数详解(Explanation of logistic regression cost function)
第三周:浅层神经网络(Shallow neural networks)
3.1 神经网络概述(Neural Network Overview)
3.2 神经网络的表示(Neural Network Representation)
3.3 计算一个神经网络的输出(Computing a Neural Network's output)
3.4 多样本向量化(Vectorizing across multiple examples)
3.5 向量化实现的解释(Justification for vectorized implementation)
3.6 激活函数(Activation functions)
3.7 为什么需要非线性激活函数?(why need a nonlinear activation function?)
3.8 激活函数的导数(Derivatives of activation functions)
3.9 神经网络的梯度下降(Gradient descent for neural networks)
3.10(选修)直观理解反向传播(Backpropagation intuition)
3.11 随机初始化(Random+Initialization)
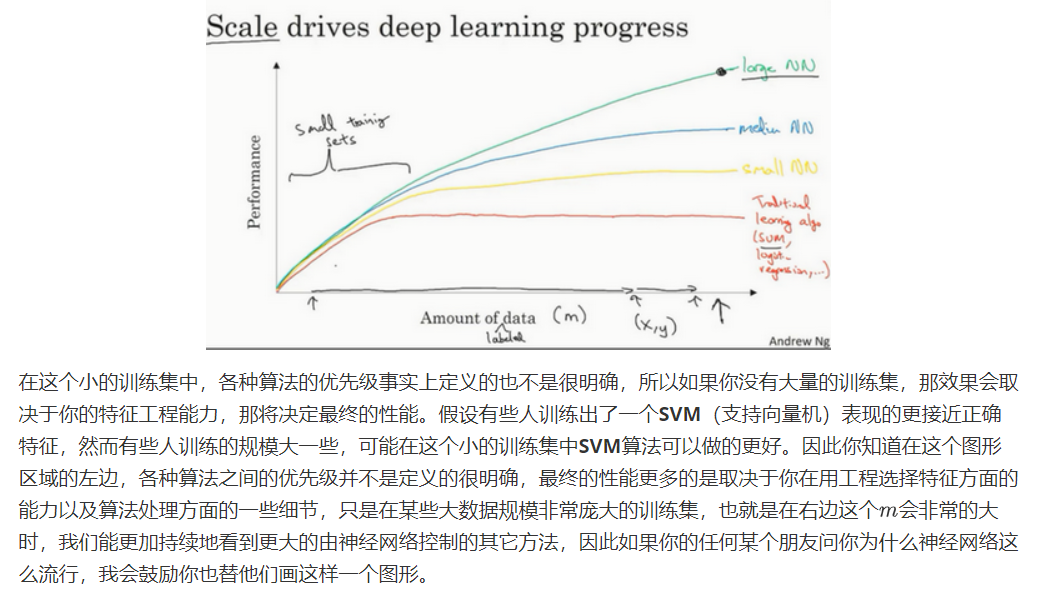
数据的数量决定了模型训练的效果,前期差别不大
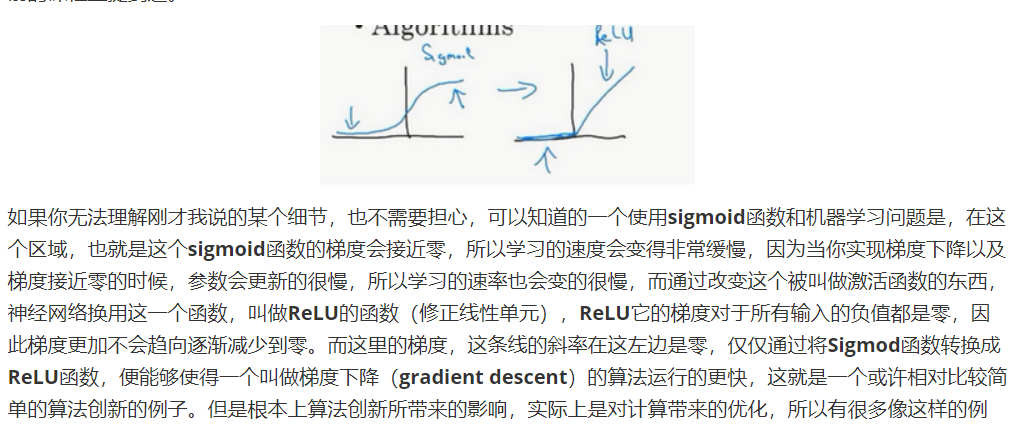
通过sigmoid 改成relu,可以让学习率的上升下降更加明显,可以降低训练时间
使用这个逻辑损失函数,为了让目标值和预测值y的大小取值方向是一致的。
代价函数是损失函数的求和平均

关于梯度下降过程中减去求导的思考
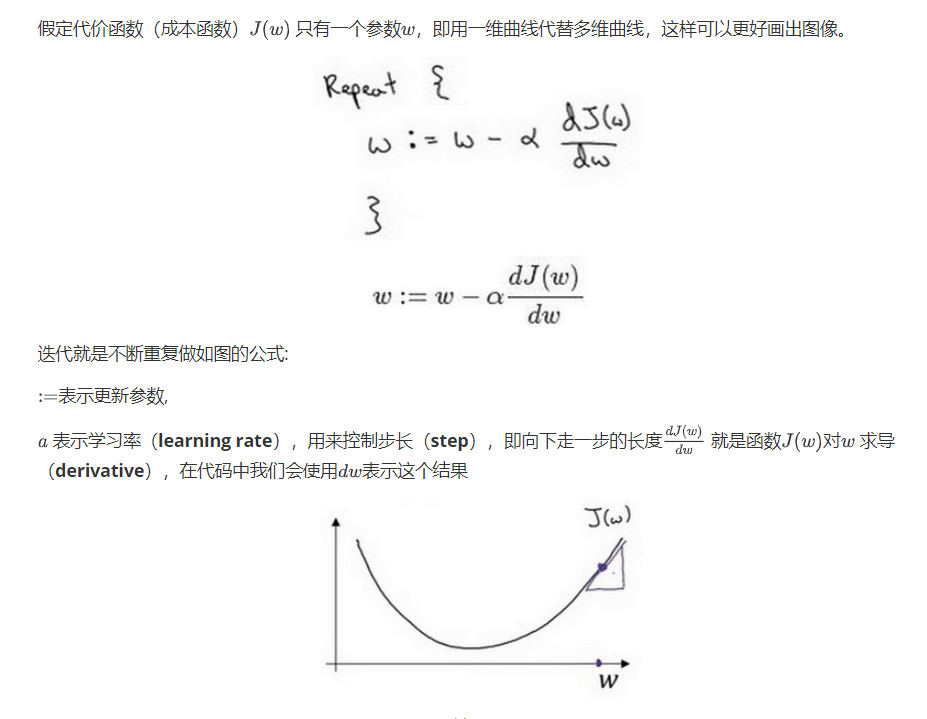
参考斜率的形式,大于0和小于0 的斜率图像摆放是不同的
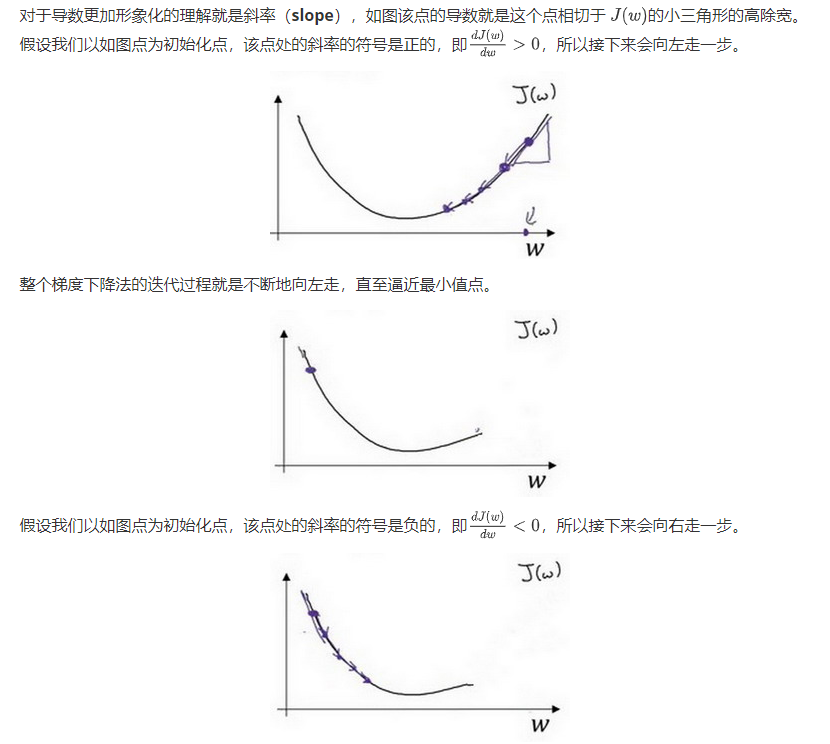
逻辑回归中的梯度下降(Logistic Regression Gradient Descent)

上述过程通过np的矩阵方式来做,可以减少for循环的时间,也可以降低运行时间

多个样本的前后传递更新


所谓的broadcast原则就是根据最大的那个来扩充

sigmoid函数和tanh函数两者共同的缺点是,在特别大或者特别小的情况下,导数的梯度或者函数的斜率会变得特别小,最后就会接近于0,导致降低梯度下降的速度。
在机器学习另一个很流行的函数是:修正线性单元的函数(ReLu),ReLu函数图像是如下图。 公式3.22: 所以,只要是正值的情况下,导数恒等于1,当是负值的时候,导数恒等于0。从实际上来说,当使用的导数时,=0的导数是没有定义的。但是当编程实现的时候,的取值刚好等于0.00000001,这个值相当小,所以,在实践中,不需要担心这个值,是等于0的时候,假设一个导数是1或者0效果都可以。
这有一些选择激活函数的经验法则:
如果输出是0、1值(二分类问题),则输出层选择sigmoid函数,然后其它的所有单元都选择Relu函数。
这是很多激活函数的默认选择,如果在隐藏层上不确定使用哪个激活函数,那么通常会使用Relu激活函数。有时,也会使用tanh激活函数,但Relu的一个优点是:当是负值的时候,导数等于0。
这里也有另一个版本的Relu被称为Leaky Relu。
当是负值时,这个函数的值不是等于0,而是轻微的倾斜,如图。
这个函数通常比Relu激活函数效果要好,尽管在实际中Leaky ReLu使用的并不多。



比较难的一个part

