我们设计测试用例时,会出现测试步骤一样,只是其中的测试数据有变化的情况,比如测试登录时的账号密码。这个时候,如果我们依然使用一条case一个方法的话,会出现大量的代码冗余,而且效率也会大大降低。此时,ddt模块就能帮助我们解决这个问题。
ddt(data-driven test),顾名思义,数据驱动测试。这个模块是第三方库,需要我们自己下载。或者直接在命令行输入pip install ddt。
ddt用法
先看一个简单的演示:
import unittest import ddt @ddt.ddt # 解析Demo中使用了ddt装饰器的方法 class Demo(unittest.TestCase): @ddt.data(1, 2) # 迭代的参数值 def test_case_1(self, v): # 迭代的参数个数需要与方法中的形参个数一致 print(f"v:{v}") @ddt.data((1, 2), [3, 4]) # 迭代的参数值类型可以为元组或列表 @ddt.unpack # 当迭代的参数为多维数组时,需要使用该装饰器来解析参数 def test_case_2(self, v1, v2): print(f"v1:{v1} v2:{v2}") @ddt.data({"v3": 1, "v4": 2}, {"v3": 3, "v4": 4}) # 迭代的参数值类型可以为字典,字典的key值需要与形参的名称一致 @ddt.unpack def test_case_3(self, v3, v4): print(f"v3:{v3} v4:{v4}") if __name__ == '__main__': unittest.main()
演示结果:
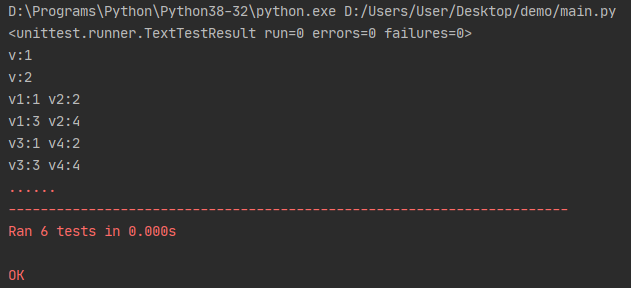
ddt缺陷
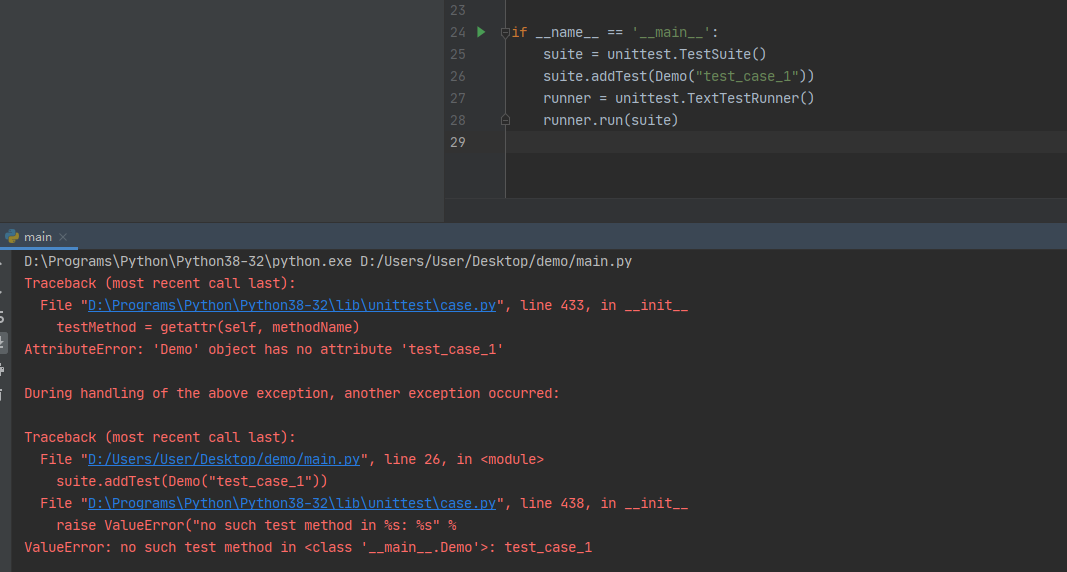
按照上面的方法将ddt运用到实际项目中,就能实现数据驱动的功能了。但是,用dir(Demo)查看类的属性时,发现找不到 test_case_1,*2,*3的方法名称,而是出现下图类似的名称。

这是因为ddt为了防止方法名冲突,自动修改了方法名称。名称改变后,表面看起来也没影响用例的执行,这是因为我们使用的是自动搜索用例的方法执行的用例,如果使用addTest这种指定用例的方法就会报错:ValueError: no such test method in <class '__main__.Demo'>: test_case_1
如果我们不实用指定用例的方法那是不是就没有问题了呢?执行上确实没问题,但如果我们使用了自动生成报告的模块(比如:BeautifulReport),生成的报告中,用例名称显示的是修改后的名称。

修复ddt缺陷
添加指定用例的方法看起来是无解的,因为使用数据驱动迭代的过程中,ddt必然会修改被装饰方法的方法名称,那怎么办呢?既然是ddt在解析用例过程中修改的方法名称,那么我们在解析过程中自定义用例名。
综合考虑各数据类型的特性后,决定不修改ddt对元组和列表类型数据的处理方式,只在字典类型的数据中添加指定用例名称的方法。
通读ddt源码,发现ddt是在 mk_test_name() 函数中定义的用例名称,具体代码如下:
def mk_test_name(name, value, index=0, name_fmt=TestNameFormat.DEFAULT): # Add zeros before index to keep order index = "{0:0{1}}".format(index + 1, index_len) if name_fmt is TestNameFormat.INDEX_ONLY or not is_trivial(value): return "{0}_{1}".format(name, index) try: value = str(value) except UnicodeEncodeError: # fallback for python2 value = value.encode('ascii', 'backslashreplace') test_name = "{0}_{1}_{2}".format(name, index, value) return re.sub(r'W|^(?=d)', '_', test_name)
我们只要在这部分代码中增加对字典类型的数据处理即可,增加蓝色区域代码如下:
def mk_test_name(name, value, index=0, name_fmt=TestNameFormat.DEFAULT): # Add zeros before index to keep order index = "{0:0{1}}".format(index + 1, index_len) if name_fmt is TestNameFormat.INDEX_ONLY or not is_trivial(value): if isinstance(value, dict): test_name = value.get("case_name") if test_name is not None: return test_name return "{0}_{1}".format(name, index) try: value = str(value) except UnicodeEncodeError: # fallback for python2 value = value.encode('ascii', 'backslashreplace') test_name = "{0}_{1}_{2}".format(name, index, value) return re.sub(r'W|^(?=d)', '_', test_name)
修改代码后,自定义用例名称的用法是在数据中定义case_name的key,值就为用例名称。
代码演示如下:
import unittest import ddt @ddt.ddt # 解析Demo中使用了ddt装饰器的方法 class Demo(unittest.TestCase): @ddt.data(1, 2) # 迭代的参数值 def test_case_1(self, v): # 迭代的参数个数需要与方法中的形参个数一致 print(f"v:{v}") @ddt.data((1, 2), [3, 4]) # 迭代的参数值类型可以为元组或列表 @ddt.unpack # 当迭代的参数为多维数组时,需要使用该装饰器来解析参数 def test_case_2(self, v1, v2): print(f"v1:{v1} v2:{v2}") @ddt.data({"v3": 1, "v4": 2, "case_name": "test_normal"}, {"v3": 3, "v4": 4, "case_name": "test_error"}) # 在数据中定义case_name的key,值就为用例名称 @ddt.unpack def test_case_3(self, v3, v4, case_name): print(f"v3:{v3} v4:{v4}")
执行结果如下
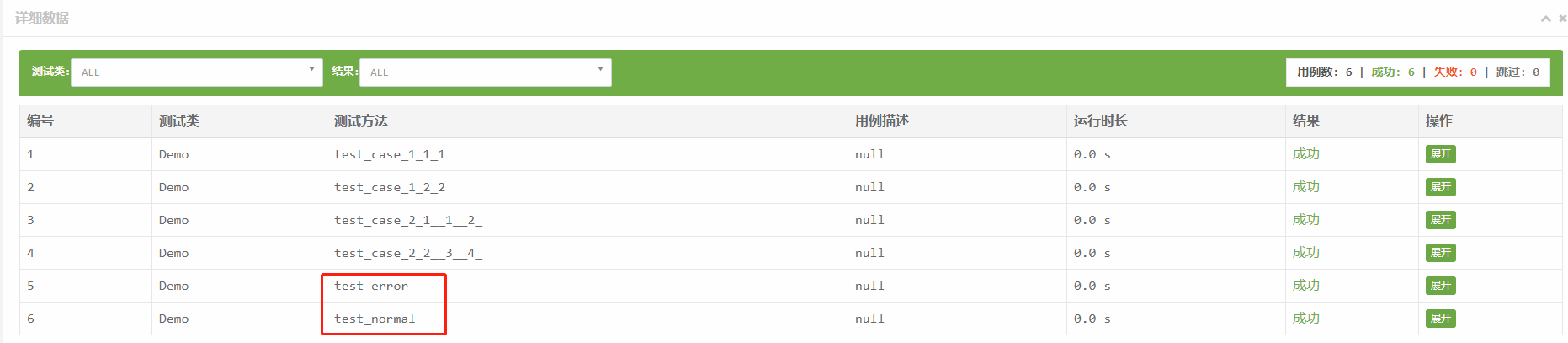
需要注意两点:
- 自定义的用例名称不能相同,虽然不会报错,但是只会执行一个用例。
- 自定义的用例名称也必须是test开头。
使用这种方法,也能解决addTest添加不了用例的问题,有兴趣自己可以试试,就不在演示了。
ddt的数据可在用例描述中参数化显示
ddt对用例描述使用format方法进行了初始化
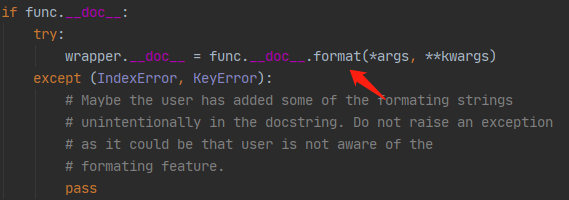
因此在用例描述中,增加参数值的显示
@ddt.ddt # 解析Demo中使用了ddt装饰器的方法 class Demo(unittest.TestCase): @ddt.data({"v3": 1, "v4": 2, "case_name": "test_normal"}, {"v3": 3, "v4": 4, "case_name": "test_error"}) # 在数据中定义case_name的key,值就为用例名称 @ddt.unpack def test_case(self, v3, v4, case_name): """参数值为v3:{v3},v4:{v4}""" print(f"v3:{v3} v4:{v4}")
执行结果
