CPU定位分析
CPU利用率大于50%,需要注意;大于70%,需要密切关注;高于90%,情况比较严重。
监控命令:vmstat、sar、dstat、mpstat、top、ps
|
类型 |
度量方法 |
衡量标准 |
|
利用率 |
1、vmstat 统计1-%idle 2、sar -u 统计1-%idle 3、dstat 统计1-%idl 4、mpstat -P ALL 统计1-%idle |
注意>=50% 告警>=70% 严重>=90% |
|
满载 |
1、vmstat的r值> cpu逻辑颗数 2、sar -q ,“runq-sz”>cpu逻辑颗数 |
运行队列大于1时,证明已经有一定的负载 |
内存定位分析
当物理内存不够时,会使用swap分区,所以性能测试过程中需要关注swap和mem的使用情况。
物理内存不够,大量的内存置换到swap空间,可能导致CPU和I/O的瓶颈。
监控命令:vmstat、sar、dstat、free、top、ps等
|
类型 |
度量方法 |
衡量标注 |
|
占用率 |
1、free 查看使用情况 2、vmstat 3、sar -r 4、ps |
注意>=50% 告警>=70% 严重>=80% |
|
满载 |
1、vmstat的si/so比例,swapd占比 2、sar -W 查看次缺页数 3、dmesg | grep killed |
1、so数值大,且swapd已经占比很高,内存已经饱和 2、sar命令次缺页多意味内存已经饱和 3、内存不够用会触发内核的OOM机制 |
网络定位分析
监控命令:sar、ifconfig、netstat,以及查看net的dev速率。
通过查看发现收发包的吞吐率达到网卡的最大上限,网络数据报文有因为这类原因而引起的丢包、阻塞等现象都证明当前网络可能存在瓶颈。
为了减小网络对性能测试的影响,一般我们都在局域网中进行测试执行。
|
类型 |
度量方法 |
衡量标准 |
|
使用情况 |
1、sar -n DEV 的收发计数大于网卡上限 2、ifconfig RX/TX宽带超过网卡上限 3、cat /proc/net/dev的速率超过上限 4、nicstat的util基本满负荷 |
1、收发包的吞吐率达到网卡上限 2、有延迟 3、有丢包 4、有阻塞 |
|
满载 |
1、ifconfig dropped 有计数 2、netstat -s "segments retransmited"有计数 3、sar -n EDEV,rxdrop/s txdrop/s有计数 |
有丢包统计 |
|
错误 |
1、ifconfig,“errors” 2、netstat -i,RX-ERR TX-ERR 3、sar -n EDEV,rxerr/s txerr/s 4、ip -s link, “errors” |
错误有计数 |
IO定位分析
I/O读写频繁的时候,如果I/O得不到满足会导致应用的阻塞。
需要考虑I/O的TPS、平均I/O数据、平均队列长度、平均服务时间、平均等待时间、IO利用率(磁盘Busy Time%)等指标
监控命令:sar、iostat、iotop
|
类型 |
度量方法 |
衡量标准 |
|
使用情况 |
1、iostat -xz,“%util” 2、sar -d,“%util” 3、cat /proc/pid/sched | grep iowait |
注意>=40% 告警>=60% 严重>=80% |
|
满载 |
1、iostat -xnz,“avgqu-sz ”>1 2、iostat await>70 |
IO疑似满载 |
|
错误 |
1、dmseg 查看io错误 2、smartctl /dev/sda |
有错误信息 |
nmon监控
一、检查安装环境
# uname –a (查看操作系统信息,所检查服务器为64位操作系统)
# lsb_release –a (查看linux发行商版本,所检查服务器linux版本为:CentOS6.5)
二、安装
1、手动下载解压安装
nmon: 下载命令 wget http://sourceforge.net/projects/nmon/files/download/nmon_x86_12a.zip/download
安装位置:/home/nmon (任意目录)
1、 在home 目录下创建nmon文件夹:# mkdir nmon
2、 上传nmon_linux_14i.tar.gz 到nmon目录
3、 解压:# tar –zxvf nmon_linux_14i.tar.gz
4、 赋权限:# chmod –R 755 nmon
5、 启动nmon:# ./nmon_x86_64_sles11(在nmon目录下执行命令)
2、yum自动安装
首先安装第三方yum源
wget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo
wget -P /target/path http://192.168.1.1:3333/file/to/download.gz 下载文件时若需要指定目录则使用 -P 参数,如果指定的目录不存在,则会自动创建
wget http://192.168.1.1:3333/file/to/download.gz -O /path/to/rename.gz 下载的文件进行重命名则使用 -O 参数,如果重命名中包含路径则该路径必须事先创建好
更新yum源
yum makecache
安装nmon
yum -y install nmon
安装成功显示以下界面:
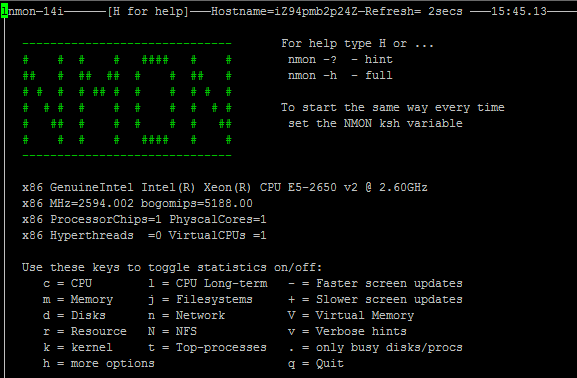
四、实时监控
输入以下命令:
c 可显示CPU的信息
m 对应内存
n 对应网络
d 可以查看磁盘信息
t 可以查看系统的进程信息
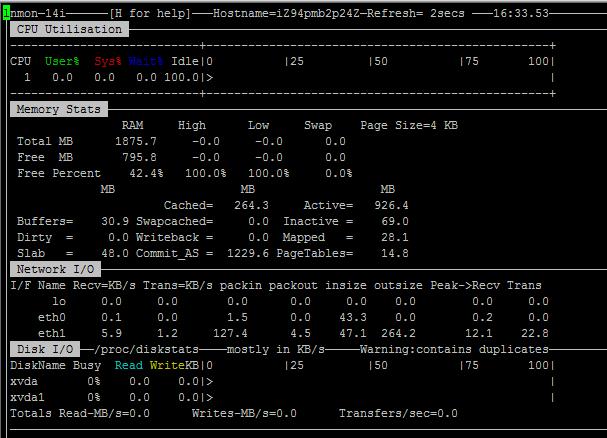
五、配置环境变量
1、修改启动文件名称:
# mv nmon_x86_64_sles11 nmon
# ./nmon
2、 添加到环境变量中:
# vim /etc/profile (在profile中写入以下两行内容)
PATH=PATH:/home/nmon/nmon(PATH:/home/nmon/nmon(PATH:后为命令的路径)
export PATH
3、 保存退出
4、 使配置文件立即生效
# source /etc/profile
# nmon (在任何目录下执行nmon命令启动nmon)
六、采集监控数据
在实际的性能测试中我们需要把一段时间之内的数据记录下来,如:
1、采集数据
# nmon -s1 -c60 -f -m /home/nmon
参数说明:
-s1 每隔n秒抽样一次,这里为1秒
-c60 取出多少个抽样数量,这里为60,即监控=1*60/60=1分钟
-f 按标准格式输出文件名称:<hostname>_YYMMDD_HHMM.nmon
-m 指定监控文件的存放目录,-m后跟指定目录
七、生成图形化报表
nmonanalyser:
版本:nmon_analyser_v47.zip
1、将.nmon文件转化成.csv文件
# sort chen _151014_1659.nmon > chen _151014_1659.csv
2、将.csv文件下载到本地
3、打开nmon analyser工具
在本地解压nmon_analyser_v47.zip
双击打开:nmon analyser v47.xlsm
点击Analyse nmon data按钮,加载之前下载的chen_151014_1659.csv文件。
八、结果分析

开源工具介绍
1、Zabbix
Zabbix是一个基于WEB界面的提供分布式系统监控以及网络监控功能的企业级开源运维平台,也是目前国内互联网用户中使用最广的监控软件,云智慧遇到的85%以上用户在使用Zabbix做监控解决方案。入门容易、上手简单、功能强大并且开源免费是云智慧对Zabbix的最直观评价。Zabbix易于管理和配置,能生成比较漂亮的数据图,其自动发 现功能大大减轻日常管理的工作量,丰富的数据采集方式和API接口可以让用户灵活进行数据采集,而分布式系统架构可以支持监控更多的设备。理论上,通过 Zabbix提供的插件式架构,可以满足企业的任何需求。
优点:
1. 支持多平台的企业级分布式开源监控软件
2. 安装部署简单,多种数据采集插件灵活集成
3. 功能强大,可实现复杂多条件告警,
4. 自带画图功能,得到的数据可以绘成图形5. 提供多种API接口,支持调用脚本6. 出现问题时可自动远程执行命令(需对agent设置执行权限)
缺点:
1. 项目批量修改不方便2. 入门容易,能实现基础的监控,但是深层次需求需要非常熟悉Zabbix并进行大量的二次定制开发,难度较大;3. 系统级别报警设置相对比较多,如果不筛选的话报警邮件会很多;并且自定义的项目报警需要自己设置,过程比较繁琐(但是网上的模板比较,也可以使用模板导入的方法);4. 缺少数据汇总功能,如无法查看一组服务器平均值,需进行二次开发;5. 数据报表需要特殊二次开发定义;
2、Open-falcon
Open-falcon是小米运维团队从互联网公司的需求出发,根据多年的运维经验,结合SRE、SA、DEVS的使用经验和反馈,开发的一套面向互联网的企业级开源监控产品。

Open-falcon架构
用户群:目前有几十家企业用户不同程度使用。
优点:
1. 自动发现,支持falcon-agent、snmp、支持用户主动push、用户自定义插件支持
2. 支持每个周期上亿次的数据采集、告警判定、历史数据存储和查询
3. 高效的portal、支持策略模板、模板继承和覆盖、多种告警方式、支持callback调用
4. 单机支撑200万metric的上报、归档、存储
5. 采用rrdtool的数据归档策略,秒级返回上百个metric一年的历史数据
6. 多维度的数据展示,用户自定义Screen
7. 通过各种插件目前支持Linux、Windows、Mysql、Redis、Memache、RabbitMQ和交换机监控。
缺点:
由于发布时间较短,很多基础的服务监控插件(如Tomcat、apache等)还不支持,很多功能还在不断完善中,另外由于缺少专门的支持,虽然有开放社区,但是解决问题的效率相对较低。
zabbix监控
Zabbix 是由 Alexei Vladishev 开发的一种网络监视、管理系统,基于CS架构。可用于监视各种网络服务、服务器和网络机器等状态。使用MySQL, PostgreSQL, SQLite, Oracle 或 IBM DB2 等数据库储存资料。Server 端基于C语言、Web 管理端则是基于 PHP 所制作的。Zabbix 可以使用多种方式监视。可以只使用 Simple Check 不需要安装 Client 端,亦可基于 SMTP 或 HTTP ... 各种协定做死活监视。在客户端如 UNIX, Windows 中安装 Zabbix Agent 之后,可监视 CPU Load、网络使用状况、硬盘容量等各种状态。而就算没有安装 Agent 在监视对象中,Zabbix 也可以经由 SNMP、TCP、ICMP、利用 IPMI、SSH、telnet 对目标进行监视。另外,Zabbix 包含 XMPP 等各种 Item 警示功能。
zabbix官网: https://www.zabbix.com
zabbix 主要由2部分构成 zabbix server和 zabbix agent
zabbix proxy是用来管理其他的agent,作为代理
zabbix监控范畴
² 硬件监控 :Zabbix IPMI Interface
² 系统监控 :Zabbix Agent Interface
² Java 监控:ZabbixJMX Interface
² 网络设备监抟:Zabbix SNMP Interface
² 应用服务监控:Zabbix Agent UserParameter
² MySQL 数据库监控:percona-monitoring-pldlgins
² URL监控:Zabbix Web监控
1、实验准备
centos系统服务器3台、 一台作为监控服务器, 两台台作为被监控节点, 配置好yum源、 防火墙关闭、 各节点时钟服务同步、 各节点之间可以通过主机名互相通信。
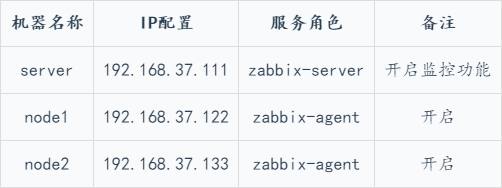
2、Zabbix的安装
1)关闭selinux和iptables
[root@linux-node2 ~]# systemctl stop firewalld.service
[root@linux-node2 ~]# setenforce 0
setenforce: SELinux is disabled
init的发展:
CentOS 5: SysV init,串行
CentOS 6:Upstart,并行,借鉴ubantu
CentOS 7:Systemd,并行,借鉴MAC
Systemd是由红帽公司开发,systemd是Linux系统中最新的初始化系统(init),它主要的设计目的是克服Sys V 固有的缺点,提高系统的启动速度,systemd和upstart是竞争对手,ubantu上使用的是upstart的启动方式,centos7上使用systemd替换了Sys V
开机启动chkconfig name on–>systemctl enable name.service
开机禁止启动chkconfig name off –>systemctl disable name.service
查看所有服务的开机自启状态chkconfig –list–>systemctl list-unit-files -t service
启动:service name start –>systemctl start name.service
停止:service name stop –>systemctl stop name.service
重启:service name restart–>systemctl restart name.service
状态:service name status–>systemctl status name.service
2)删除旧版本MySQL5.1数据库
[root@localhost ~]# rpm -qa mysql* #查看已安装的
[root@localhost ~]# yum remove mysql
[root@localhost ~]# yum remove mysql-connector-java-5.1.17-6.el6.noarch
[root@localhost ~]# yum remove mysql-libs-5.1.73-8.el6_8.x86_64 ##删除MySQL物理存储位置
[root@localhost mysql]# cd /var/lib/mysql
[root@localhost mysql]# rm -rf ./*3)安装MySQL 5.6数据库
1.下载mysql源安装包
shell> wget http://dev.mysql.com/get/mysql57-community-release-el7-8.noarch.rpm
2.安装mysql源
shell> yum localinstall mysql57-community-release-el7-8.noarch.rpm
3.检查mysql源是否安装成功
shell> yum repolist enabled | grep "mysql.*-community.*"
4.修改 vim /etc/yum.repos.d/mysql-community.repo源 ,改变默认安装的mysql版本。比如要安装5.6版本,将5.7源的enabled=1改成enabled=0。然后再将5.6源的enabled=0改成enabled=1即可。
5.安装MySQL
shell> yum install mysql-community-server
6.启动MySQL服务
shell> systemctl start mysqld
7.开机启动
shell> systemctl enable mysqld
shell> systemctl daemon-reload
8.修改root本地登录密码
1)连接mysql
shell> mysql -uroot -p
3)修改密码
a、在mysql中该
mysql> ALTER USER 'root'@'localhost' IDENTIFIED BY 'MyNewPass4!';
或者:
mysql> set password for 'root'@'localhost'=password('MyNewPass4!');
b、安装后通过初始化该
shell# mysql_secure_installation #初始化
4)安装Zabbix rpm包仓库
[root@linux-node2 ~]# rpm -vhi http://repo.zabbix.com/zabbix/3.0/rhel/7/x86_64/zabbix-release-3.0-1.el7.noarch.rpm
5)安装zabbix-server-mysql和zabbix-web-mysql
[root@linux-node2 ~]# yum install -y zabbix-server-mysql zabbix-web-mysql #系统会自动安装php依赖
创建数据库并授权账号
mysql> create database zabbix character set 'utf8';
mysql> grant all privileges on zabbix.* to 'zabbix'@'localhost' identified by 'zabbix'; #用户名和密码都是zabbix
mysql> flush privileges; #刷新授权导入表
[root@server ~]# rpm -ql zabbix-server-mysql #查看zabbix-server-mysql包提供的文件
[root@server ~]# gzip -d /usr/share/doc/zabbix-server-mysql-3.0.28/create.sql.gz #使用这个文件生成我们所需要的表
[root@server ~]# mysql -uzabbix -hlocalhost -pzabbix < create.sql #直接把这个表导入至我们的数据库即可进去数据库查看一下:
[root@server ~]# mysql -uzabbix -hlocalhost -pzabbix mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| test |
| zabbix |
+--------------------+
mysql> use zabbix;
Database changed
mysql> show tables;
+----------------------------+
| Tables_in_zabbix |
+----------------------------+
| acknowledges |
| actions |
| alerts |
……
| usrgrp |
| valuemaps |
+----------------------------+
127 rows in set (0.00 sec) 可以看出来,我们的数据已经导入成功了。
3、配置 server 端
修改server端的配置文件zabbix_server.conf
[root@server ~]# cd /etc/zabbix/ [root@server zabbix]# ls web zabbix_agentd.conf zabbix_agentd.d zabbix_server.conf [root@server zabbix]# cp zabbix_server.conf.bak #为了方便我们以后恢复,我们把配置文件备份一下 [root@server zabbix]# vim zabbix_server.conf ListenPort=10051 #默认监听端口 SourceIP=192.168.37.111 #发采样数据请求的IP
若是server和agent在同一台机器上,则如下修改zabbix_server.conf文件
[root@linux-node2 ~]# grep ^DB /etc/zabbix/zabbix_server.conf DBHost=localhost DBName=zabbix DBUser=zabbix DBPassword=zabbix
修改配置文件/etc/httpd/conf.d/zabbix.conf,时区改成 Asia/Shanghai
php_value max_execution_time 300 php_value memory_limit 128M php_value post_max_size 16M php_value upload_max_filesize 2M php_value max_input_time 300 php_value always_populate_raw_post_data -1 php_value date.timezone Asia/Shanghai
时区是一定要设置的,这里的是可以被注释掉,因为我们也可以在php的配置文件中设置时区,如果我们在php配置文件中设置时区,则对所有的php服务均有效,如果我们在zabbix.conf中设置时区,则仅对zabbix服务有效。所以,我们去php配置文件中设置我们的时区:
vim /etc/php.ini
[Date]
; Defines the default timezone used by the date functions
; http://php.net/date.timezone
date.timezone = Asia/Shanghai开启服务:
[root@server zabbix]# systemctl start httpd #开启web服务器 [root@server zabbix]# systemctl enable httpd #设置为开机启动
[root@server zabbix]# netstat -an |grep 80 #查看端口
[root@server zabbix]# systemctl start zabbix-server.service #开启zabbix服务
[root@server zabbix]# systemctl enable zabbix-server.service #设置zabbix服务开启启动
[root@server zabbix]# ss -nutl |grep 10051 #查看端口tcp LISTEN 0 128 *:10051 *:*
tcp LISTEN 0 128 :::10051 :::* server端的进程已启动,可以访问网站了,例如:http://本机IP/zabbix,如下图所示:
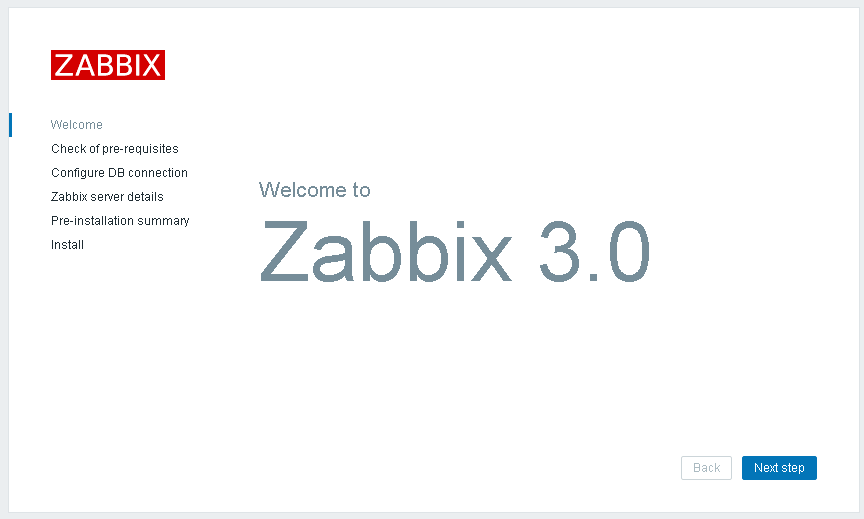
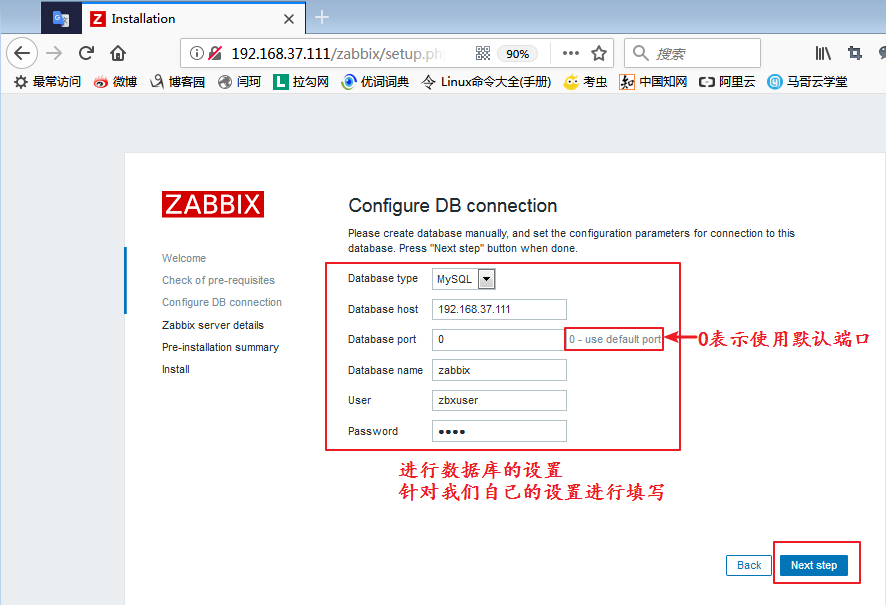
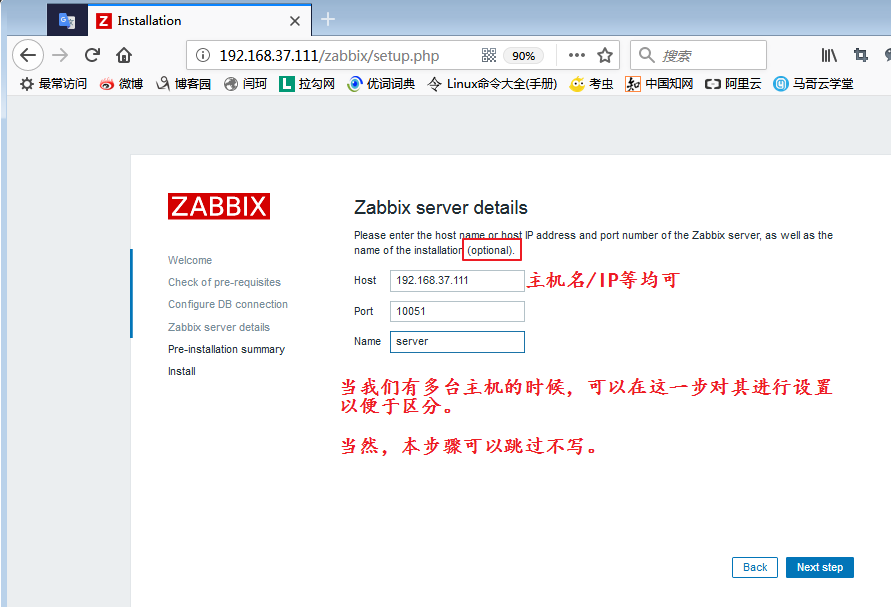
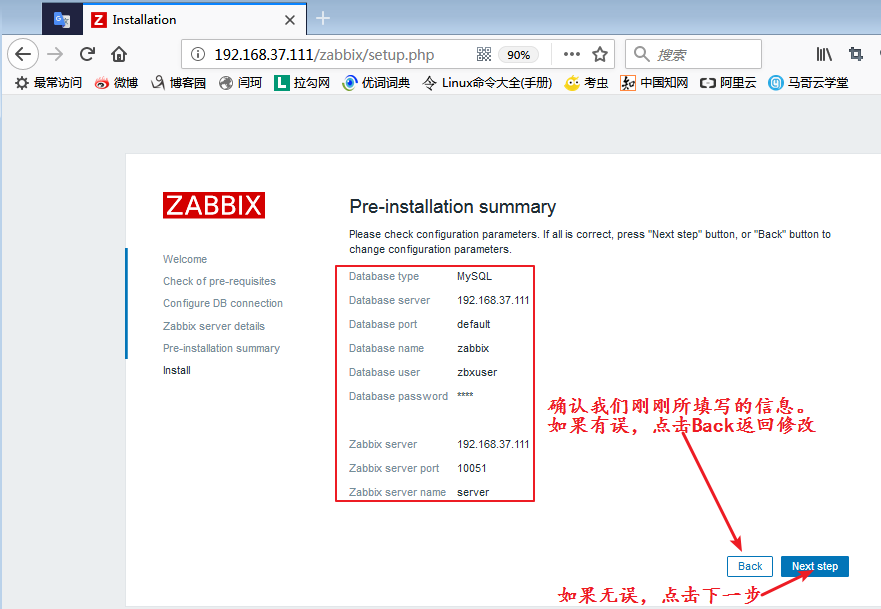
4、浏览器访问并进行初始化设置
我们使用浏览器访问192.168.37.111/zabbix,第一次访问时需要进行一些初始化的设置,我们按照提示操作即可:

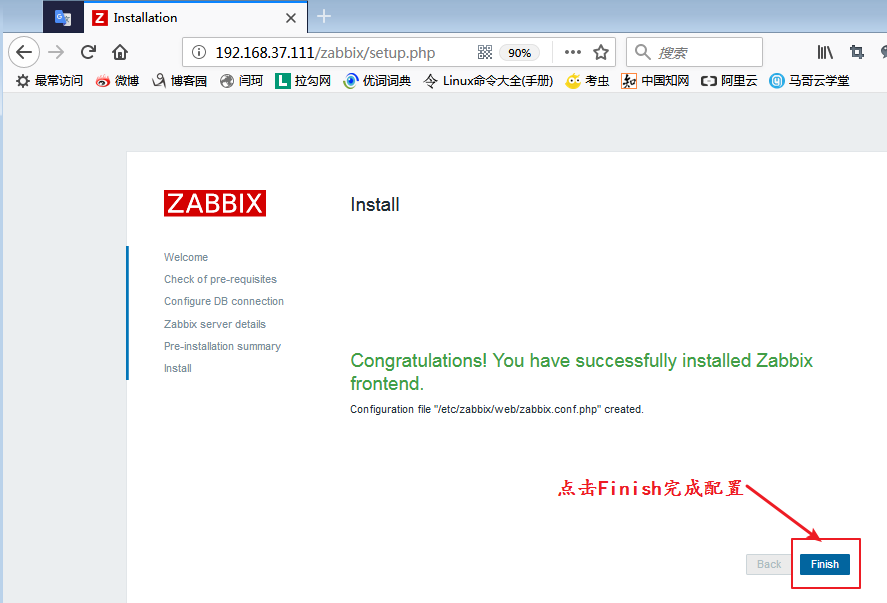
点击Finish以后,我们就会跳转到登录页面,使用我们的账号密码登录即可:
默认用户名为:admin ,密码为:zabbix 。
登陆进来就可以看到我们的仪表盘了:
5、配置 agent 端
当我们把监控端配置启动以后,我们需要来设置一下我们的监控端,我们在被监控的主机安装好agent,设置好他的server,并把他添加到server端,就能将其纳入我们的监控系统中去了。
1)安装zabbix
[root@node1 ~]# yum install zabbix-agent2)修改配置文件
[root@node1 zabbix]# rpm -ql zabbix-agent #先查一下包内容
[root@node1 ~]# cd /etc/zabbix/
[root@node1 zabbix]# ls
zabbix_agentd.conf zabbix_agentd.d
[root@node1 zabbix]# cp zabbix_agentd.conf{,.bak} #备份配置文件
[root@node1 zabbix]# vim zabbix_agentd.confServer=192.168.37.111 #指明服务器是谁的
ListenPort=10050 #自己监听的端口
ListenIP=0.0.0.0 #自己监听的地址,0.0.0.0表示本机所有地址
StartAgents=3 #优化时使用的
ServerActive=192.168.37.111 #主动监控时的服务器
Hostname=node1.keer.com #自己能被server端识别的名称 若是server和agernt在同一台机器上则无需改。[root@node1 zabbix]# systemctl start zabbix-agent.service #修改完后保存,启动服务
[root@node1 zabbix]# ss -ntul |grep 10050 查看端口tcp LISTEN 0 128 *:10050 *:*
已经开启成功。我们可以去server端添加了。node2也进行同样的操作,唯一不同的就是配置文件中的Hostname要设为node2.keer.com。
6、监控过程详解
1)修改密码及中文版
按如上操作即可,选择中文以后,点击下面的update即可更新成功,同样的,为了安全起见,我们把密码改掉:
2)创建主机及主机群组
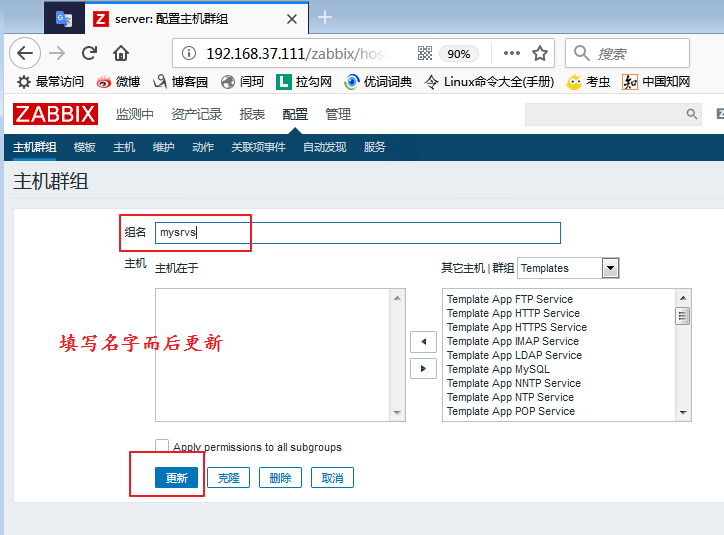
我们先来定义一个主机群组: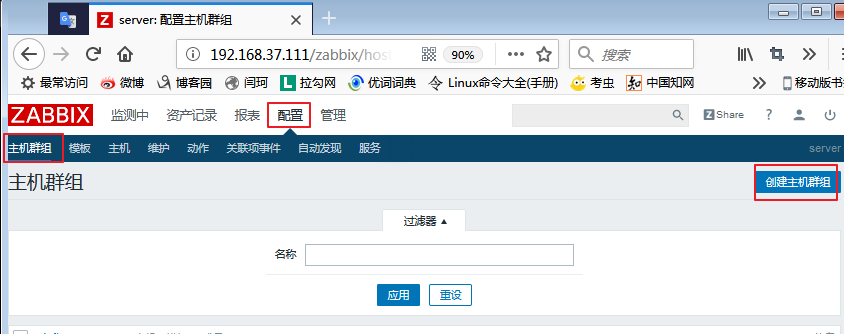
然后我们就可以去添加主机了: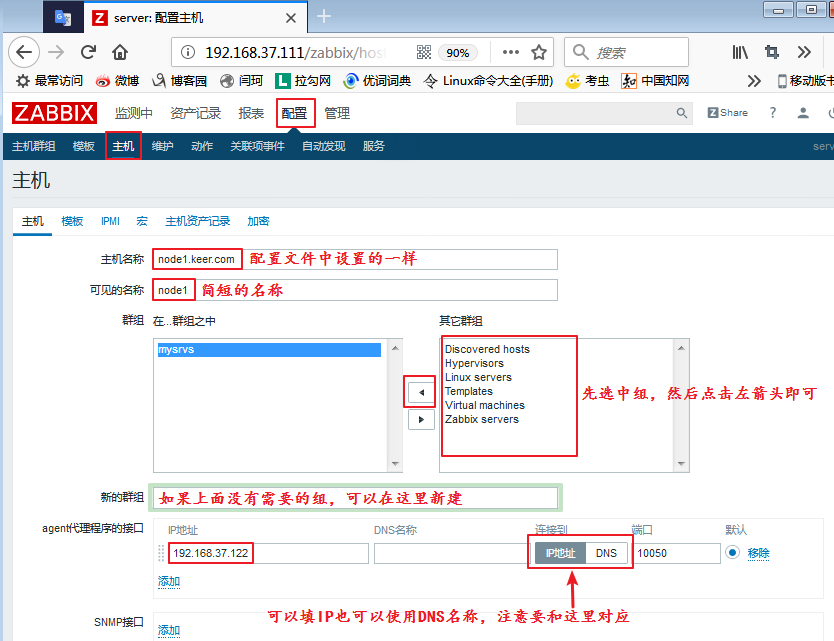
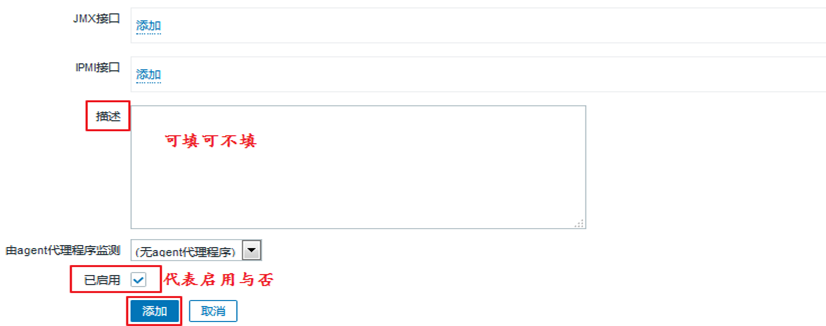
设置完成后,点击添加。我们就可以看到,我们添加的这个主机已经出现在列表中了: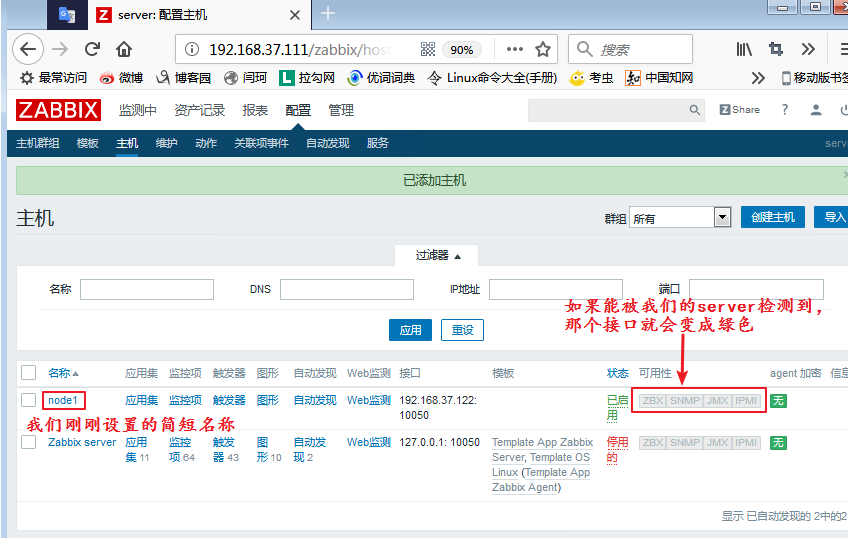
同样的,我们把node2节点也添加进来:
3)监控项(items)
我们点击上图中node1的监控项,即可创建我们的监控项,首先,我们创建三个应用集:
然后我们来定义监控项: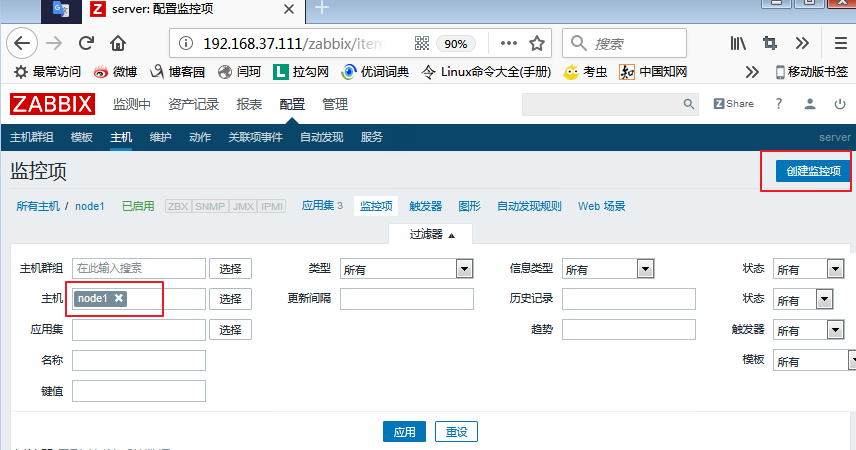
任何一个被监控项,如果想要能够被监控,一定要在zabbix-server端定义了能够连接至zabbix-agent端,并且能够获取命令。或者在agent端定义了能够让server端获取命令。一般都是内建的命令,都对应的有其名字,被我们称之为key。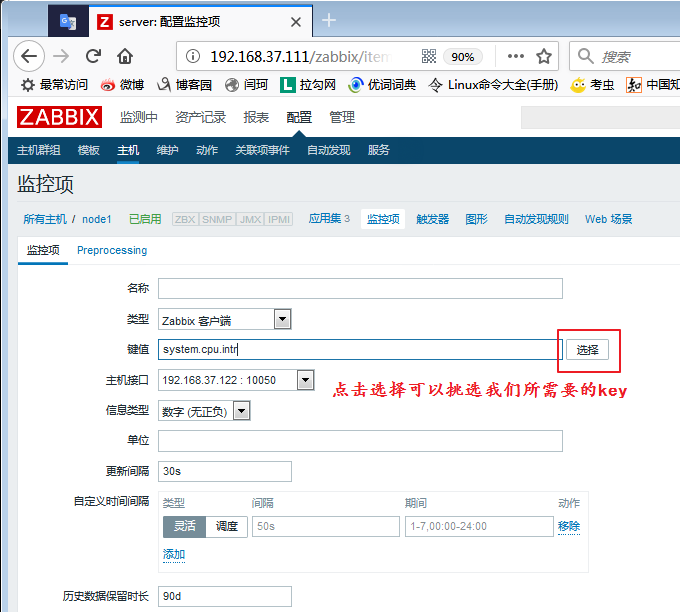
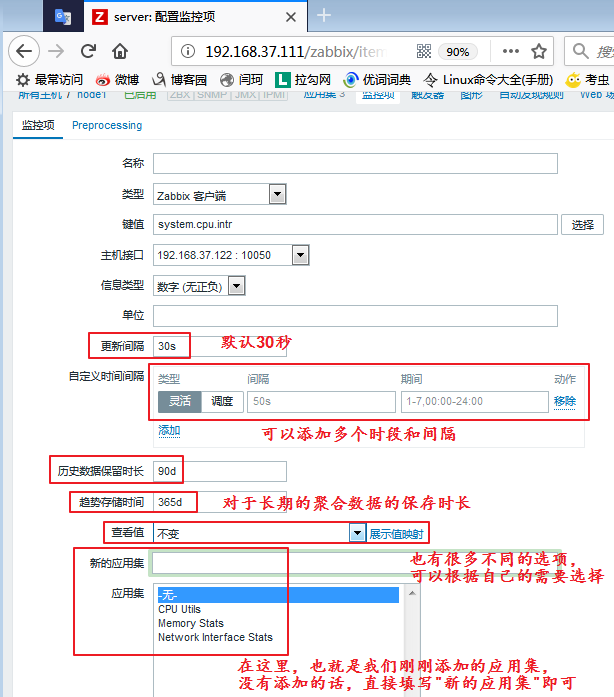
示例:我们来定义一个不带参数的监控项

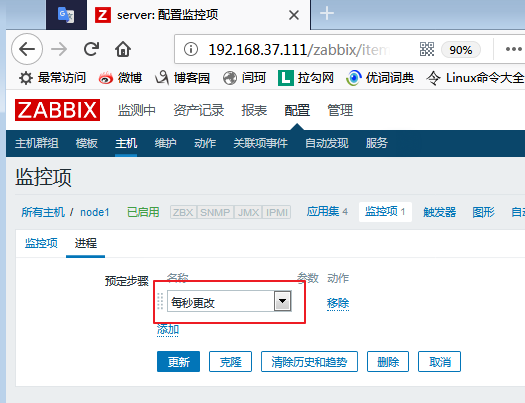
设置完以后,点击更新,即可加入,并会自动跳转至下图页面: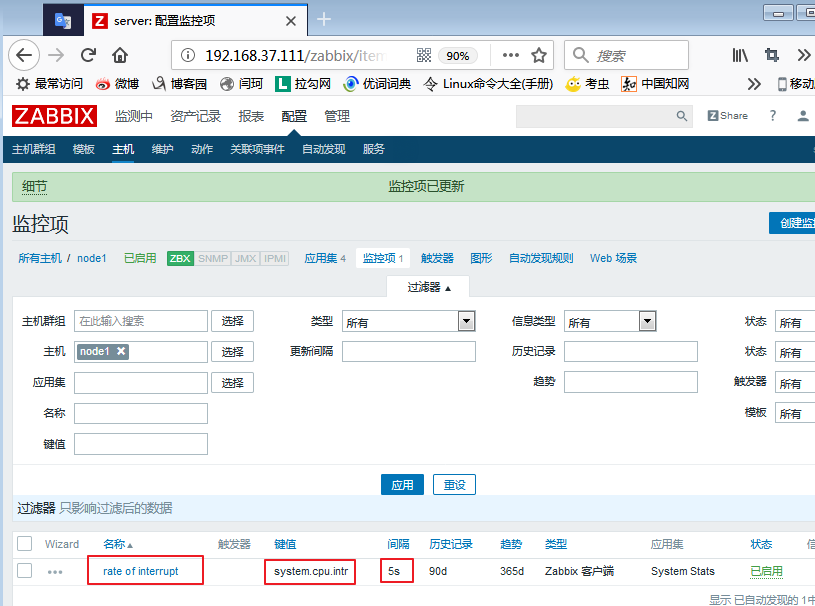
定义完成,我们回到所有主机,等待5秒,我们可以看到,我们node1节点后面的选项已经有变成绿色的了: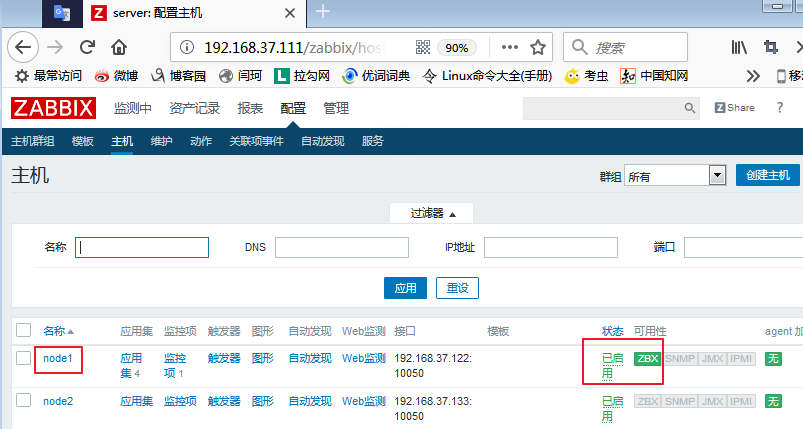
我们也可以回到我们的仪表盘,可以看到,我们的监控项有一个处于启用状态:
那么,我们的数据在哪里呢?可以点击最新数据,把我们的node1节点添加至主机,应用一下,就可以看到下面的状态了: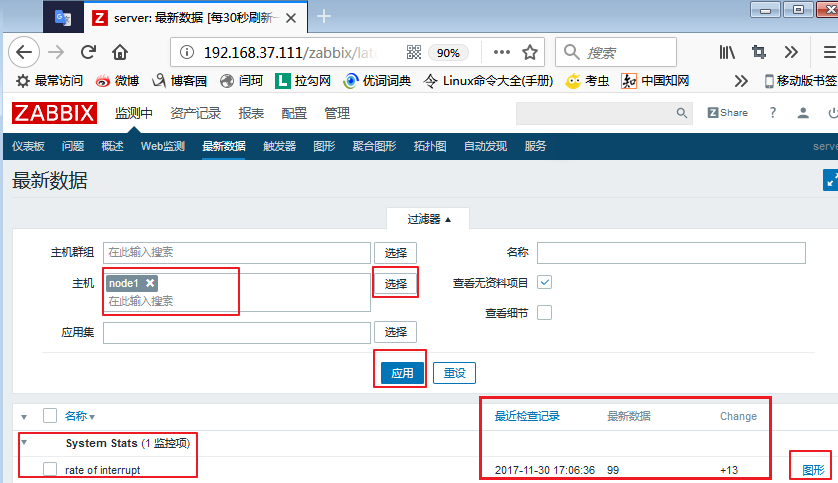
可以看到,我们还有一个图形页面,点进去则可以看图形的分布: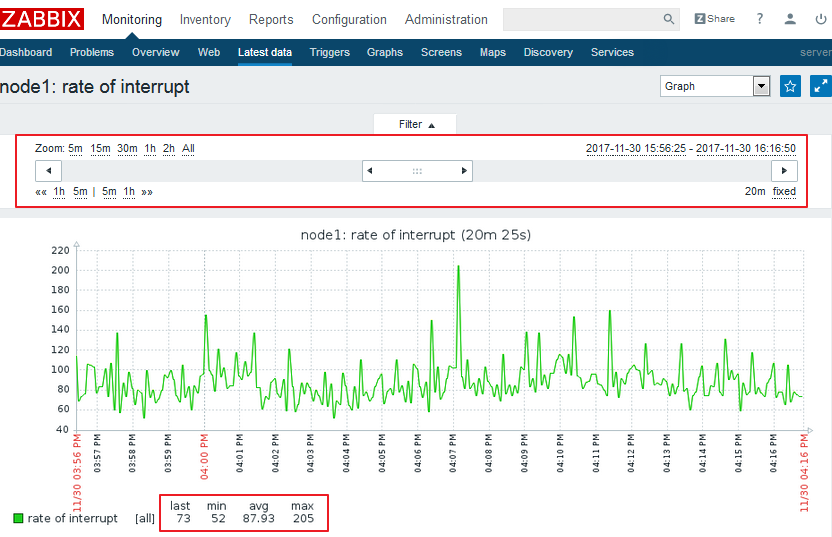
刚刚我们定义的监控项是很简单的,指定一个key即可,但是有些监控项是带有参数的,这样一来,我们的监控项就有更多的灵活性。接下来,我们来简单说明一个需要带参数的监控项:
③ 定义一个带参数的监控项

图中的[]就是需要参数的意思,里面的值即为参数,带<>为不可省略的。我们就以这个例子来说明:
if表示是接口名;<mode>表示是那种模式,包括但不限于:packets(包)、bytes(字节)、errors(错误)、dropped(丢包)、overuns等等(上述内容通过ifconfig查看)
我们来设置一下这个监控值: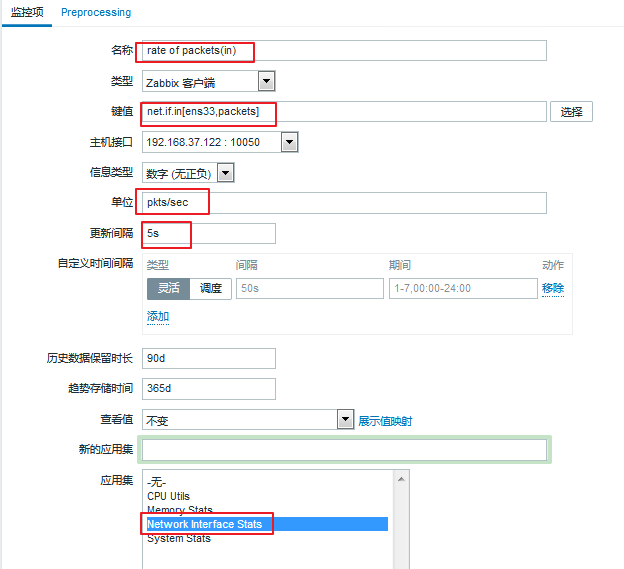

我们来看看网页的显示情况:检测中 ---> 最新数据 ---> Network Interface Stats(图形)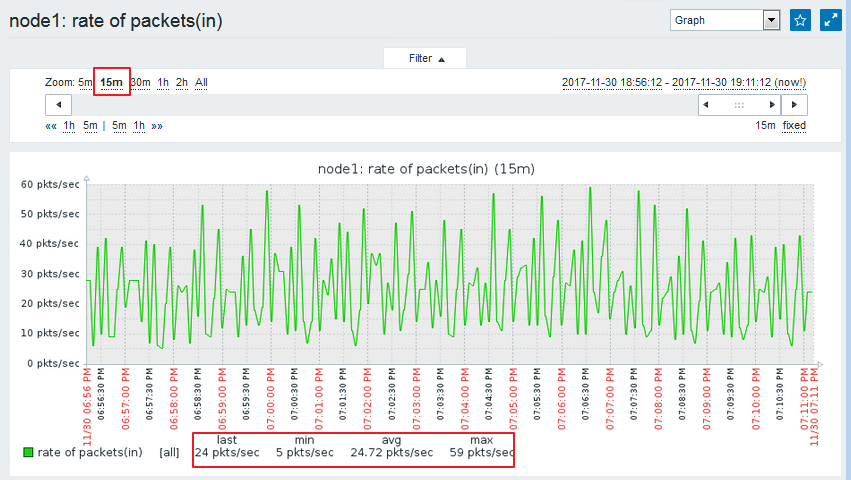
可以看一下,我们现在已经定义的指标: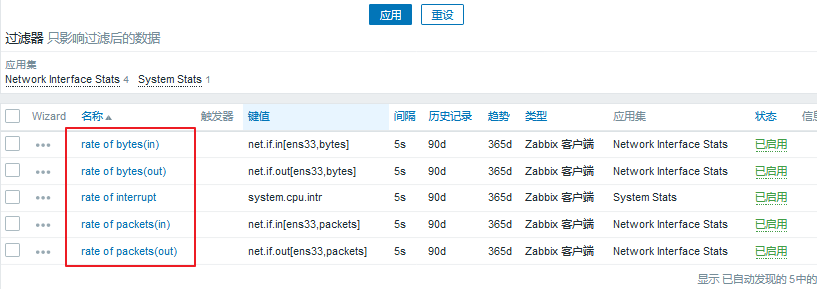
我们来到 检测中 ---> 最新数据,可以看到,我们定义的监控项都已经有值了:
4)触发器(trigger)
① 简介
当我们的采集的值定义完了以后,就可以来定义触发器了。
我们触发器的定义是:界定某特定的item采集到的数据的非合理区间或非合理状态。通常为逻辑表达式。
逻辑表达式(阈值):通常用于定义数据的不合理区间,其结果如下:
OK(不符合条件):正常状态 --> 较老的zabbix版本,其为FALSE;
PROBLEM(符合条件):非正常状态 --> 较老的zabbix版本,其为TRUE;
一般,我们评定采样数值是否为合理区间的比较稳妥的方法是——根据最后N次的平均值来判定结果;这个最后N次通常有两种定义方式:
- 最近N分钟所得结果的平均值
- 最近N次所得结果的平均值
而且,我们的触发器存在可调用的函数:
nodata() #是否采集到数据,采集不到则为异常
last() #最近几次的平均值
date()
time()
now()
dayofmonth()
...
注:能用数值保存的就不要使用字符串
② 触发器表达式
基本的触发器表达式格式如下所示
{<server>:<key>.<function>(<parameter>)}<operator><constant>server:主机名称;key:主机上关系的相应监控项的key;function:评估采集到的数据是否在合理范围内时所使用的函数,其评估过程可以根据采取的数据、当前时间及其它因素进行;- 目前,触发器所支持的函数有avg、count、change、date、dayofweek、delta、diff、iregexp、last、max、min、nodata、now、sum等
parameter:函数参数;大多数数值函数可以接受秒数为其参数,而如果在数值参数之前使用“#”做为前缀,则表示为最近几次的取值,如sum(300)表示300秒内所有取值之和,而sum(#10)则表示最近10次取值之和;- 此外,avg、count、last、min和max还支持使用第二个参数,用于完 成时间限定;例如,max(1h,7d)将返回一周之前的最大值;
表达式所支持的运算符及其功能如下图所示:
③ 定义一个触发器
我们可以查看一下rate of packets(in)的值,并以其为标准确定我们的非正常的值: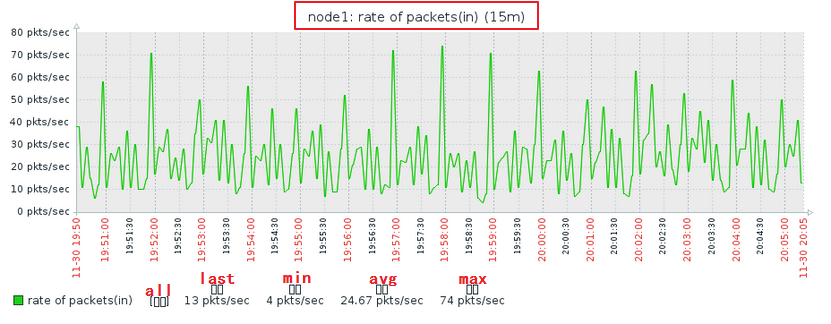
图中我们可以看出,我们的最大值为74,最小值为4,平均值为24。这样的话,我们可以定义50以上的都是非正常的值。
下面我们来定义一个触发器:
进入:配置 ---> 主机 ---> node1 ---> 触发器 ---> 创建触发器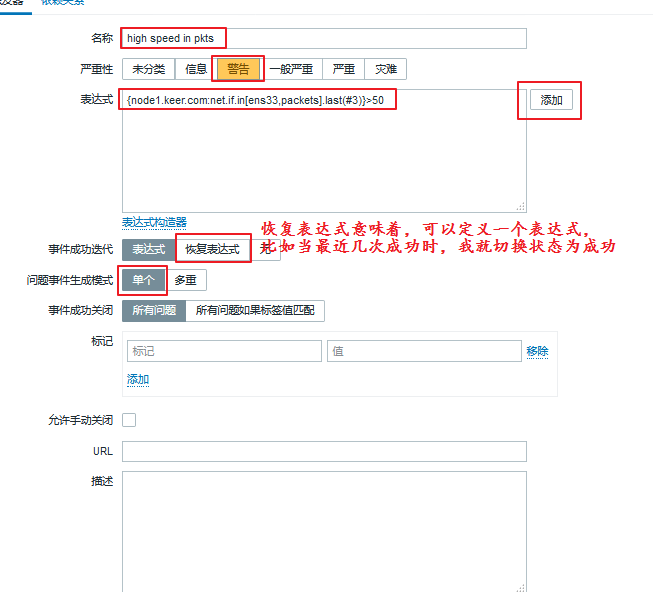
我们的表达式可以直接点击右侧的添加,然后定义自己所需的内容,即可自动生成:
生成完毕后,我们就点击页面下方的添加,即成功定义了一个触发器,同时页面自动跳转: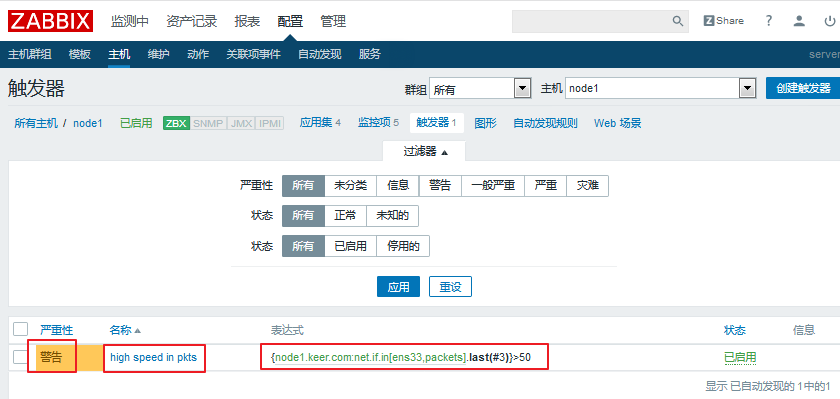
然后我们去看一下我们刚刚定义了触发器的那个监控项: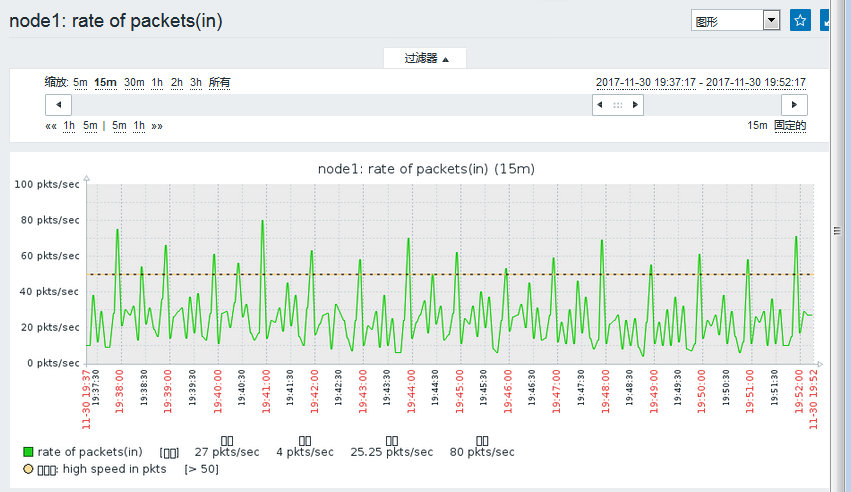
我们可以看出,这个里面就有了一根线,就是我们刚刚定义的值,超过线的即为异常状态,看起来非常直观。
但是,现在即使超过了这根线,也仅仅会产生一个触发器事件而不会做其他任何事。因此,我们就需要去定义一个动作(action)。
④ 触发器的依赖关系
我们的触发器彼此之间可能会存在依赖关系的,一旦某一个触发器被触发了,那么依赖这个触发器的其余触发器都不需要再报警。
我们可以来试想一下这样的场景:
我们的多台主机是通过交换机的网络连接线来实现被监控的。如果交换机出了故障,我们的主机自然也无法继续被监控,如果此时,我们的所有主机统统报警……想想也是一件很可怕的事情。要解决这样的问题,就是定义触发器之间的依赖关系,当交换机挂掉,只它自己报警就可以了,其余的主机就不需要在报警了。这样,也更易于我们判断真正故障所在。
注意:目前zabbix不能够直接定义主机间的依赖关系,其依赖关系仅能通过触发器来定义。
我们来简单举一个例子,示范一下如何定义一个依赖关系:
打开任意一个触发器,上面就有依赖关系,我们进行定义即可:
由于当前我们只定义了一个触发器,就不演示了,过程就是这样~添加以后点击更新即可。
触发器可以有多级依赖关系,比如我们看下面的例子: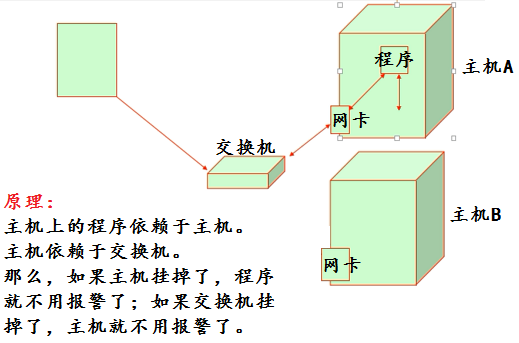
5)定义动作(action)
① 简介
我们需要去基于一个对应的事件为条件来指明该做什么事,一般就是执行远程命令或者发警报。
我们有一个告警升级的机制,所以,当发现问题的时候,我们一般是先执行一个远程操作命令,如果能够解决问题,就会发一个恢复操作的讯息给接收人,如果问题依然存在,则会执行发警报的操作,一般默认的警报接收人是当前系统中有的zabbix用户,所以当有人需要收到警报操作的话,我们则需要把它加入我们的定义之中。
其次,每一个用户也应该有一个接收告警信息的方式,即媒介,就像我们接收短信是需要有手机号的一样。
我们的每一个监控主机,能够传播告警信息的媒介有很多种,就算我们的每一种大的媒介,能够定义出来的实施媒介也有很多种。而对于一个媒介来说,每一个用户都有一个统一的或者不同的接收告警信息的端点,我们称之为目标地或者目的地。
综上,为了能够发告警信息,第一,我们要事先定义一个媒介,第二,还要定义这个媒介上用户接收消息的端点(当然,在用户上,我们也称之为用户的媒介)。
我们可以去看一下系统内建的媒介类型:
这只是大的媒介类型,里面还有更多的细分,我们以Email为例:
同样的,同一个类型我们也可以定义多个,还是以Email为例,我们可以定义一个腾讯的服务器,一个网易的服务器,一个阿里的服务器等等。
② 定义一个媒介(media)
我们还是以Email为例。来简单的定义一个媒介: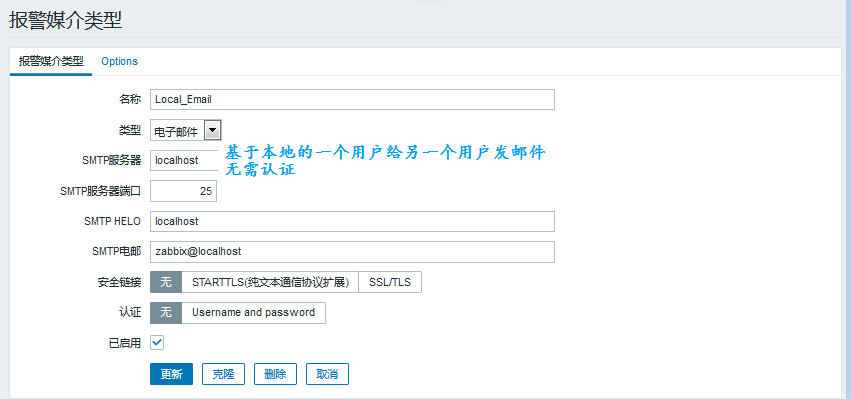
这样定义以后,我们去更新一下就可以了。
媒介定义好了,那么我们怎么才能够然后用户接收到邮件呢?比如让我们的Admin用户接收邮件,我们应该怎么操作呢?具体步骤如下:
进入 管理 ---> 用户 ---> Admin ---> 报警媒介
我们来添加一条进来:
添加过后是这样的: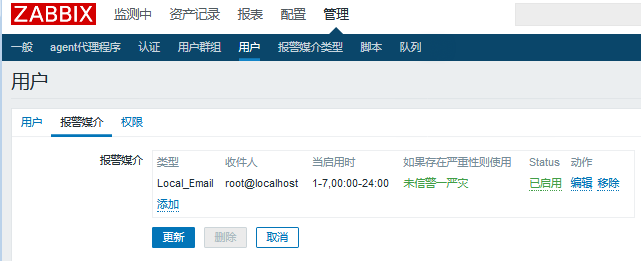
然后我们更新就可以了。
一个用户可以添加多个接收的媒介类型。
③ 定义一个动作(action)
我们之前说过了,动作是在某些特定条件下触发的,比如,某个触发器被触发了,就会触发我们的动作。
现在,我么基于redis来定义一个动作。
首先,我们在agent端使用yum安装一下redis:
[root@node1 ~]# yum install redis -y修改一下配置文件:
[root@node1 ~]# vim /etc/redis.conf
bind 0.0.0.0 #不做任何认证操作修改完成以后,我们启动服务,并检查端口:
[root@node1 ~]# systemctl start redis
[root@node1 ~]# ss -nutlp | grep redis
tcp LISTEN 0 128 *:6379 *:* users:(("redis-server",pid=5250,fd=4))接着,我们就可以去网站上来定义相关的操作了:
1.定义监控项
进入 配置 ---> 主机 ---> node1 ---> 监控项(items)---> 创建监控项
填写完毕以后,我们点击下方的添加。
该监控项已成功添加。
我们可以去查看一下他的值:
检测中 ---> 最新数据
2.定义触发器
定义好了监控项以后,我们亦可来定义一个触发器,当服务有问题的时候,我们才能及时知道:
进入 配置 ---> 主机 ---> node1 ---> 触发器(trigger)---> 创建触发器
填写完毕以后,我们点击下方的添加。
该触发器已成功添加。
我们去查看一下:
监测中 ---> 最新数据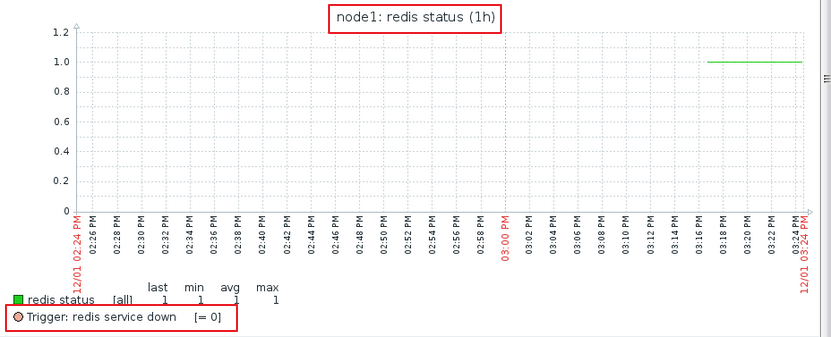
我们来手动关闭redis服务来检测一下:
[root@node1 ~]# systemctl stop redis.service 进入 监测中 ---> 问题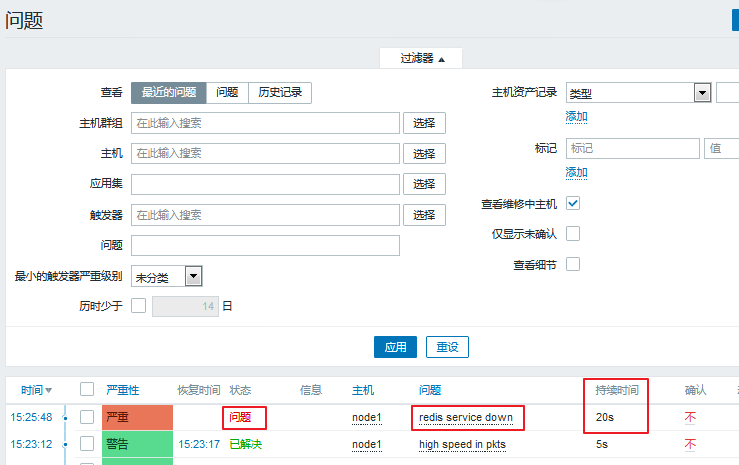
可以看到,现在已经显示的是问题了。并且有持续的时间,当我们的服务被打开,会转为已解决状态:
[root@node1 ~]# systemctl start redis.service 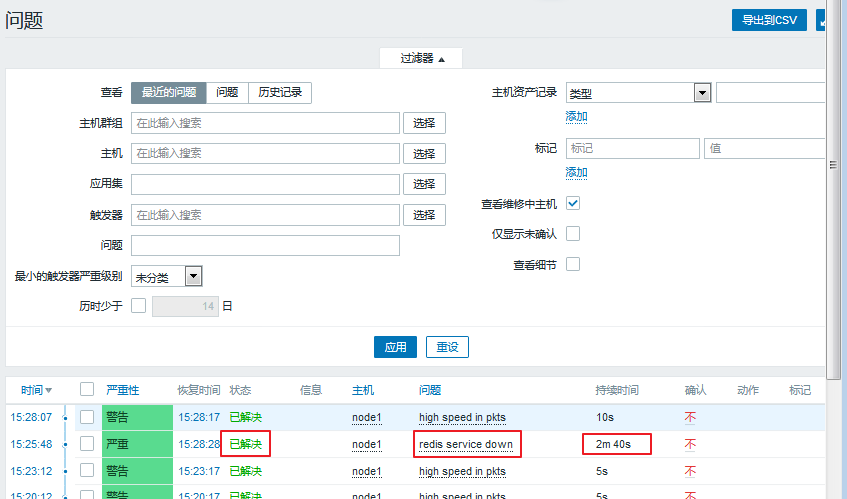
3.定义动作(action)
现在我们就可以去定义action了。
进入 配置 ---> 动作 ---> 创建动作(注意选择事件源为触发器)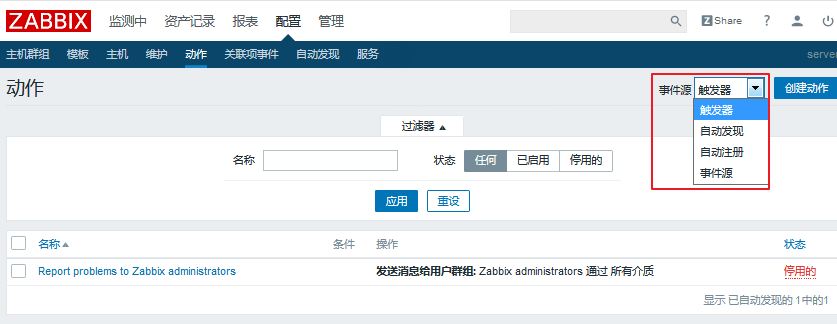
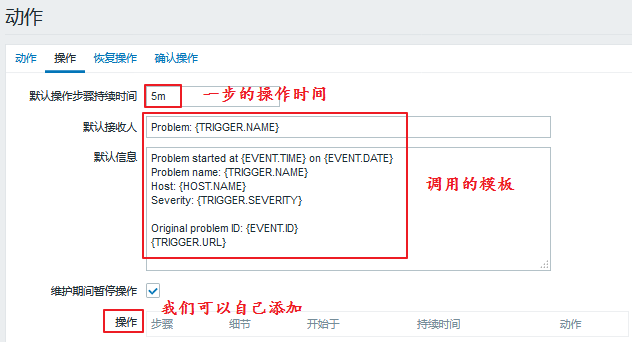
我们可以进行操作添加:
我们可以看出,还需要在虚拟机上进行两项操作,一是修改sudo配置文件使zabbix用户能够临时拥有管理员权限;二是修改zabbix配置文件使其允许接收远程命令。我们进行如下操作:
[root@node1 ~]# visudo #相当于“vim /etc/sudoers”
## Allow root to run any commands anywhere
root ALL=(ALL) ALL
zabbix ALL=(ALL) NOPASSWD: ALL #添加的一行,表示不需要输入密码
[root@node1 ~]# vim /etc/zabbix/zabbix_agentd.conf
EnableRemoteCommands=1 #允许接收远程命令
LogRemoteCommands=1 #把接收的远程命令记入日志
[root@node1 ~]# systemctl restart zabbix-agent.service 我们添加了第一步需要做的事情,也就是重启服务,如果重启不成功怎么办呢?我们就需要来添加第二步: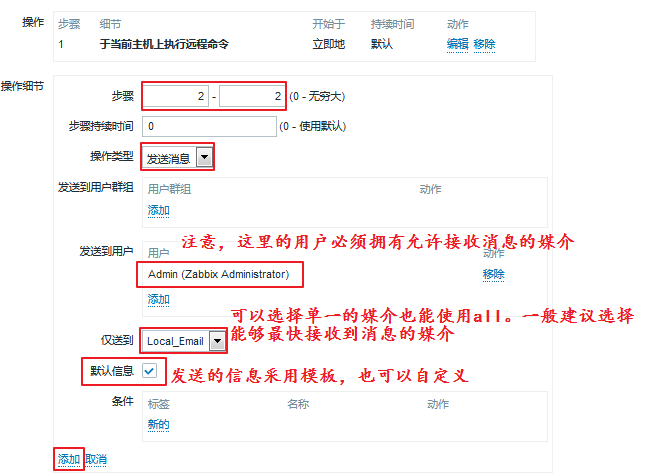
添加完成以后,我们可以看一下: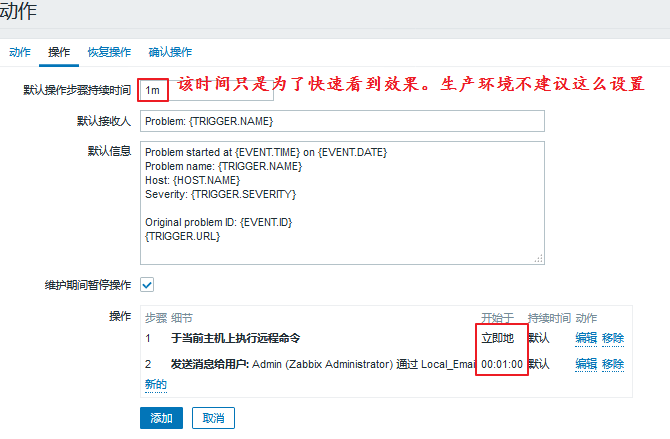
操作添加完了,如果服务自动恢复了,我们可以发送消息来提示:
至此,我们的动作设置完毕,可以点击添加了,添加完成会自动跳转至如下页面: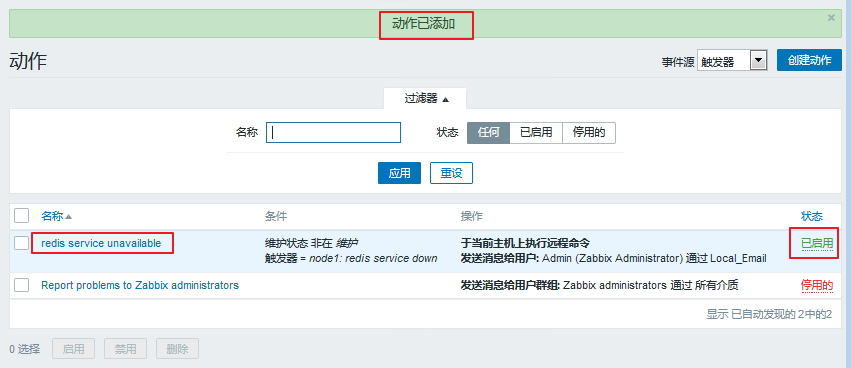
现在我们可以手动停止服务来进行测试:
[root@node1 ~]# systemctl stop redis.service 然后我们来到问题页面来查看,发现确实有问题,并且已经解决:
我们可以去server端查看是否收到邮件: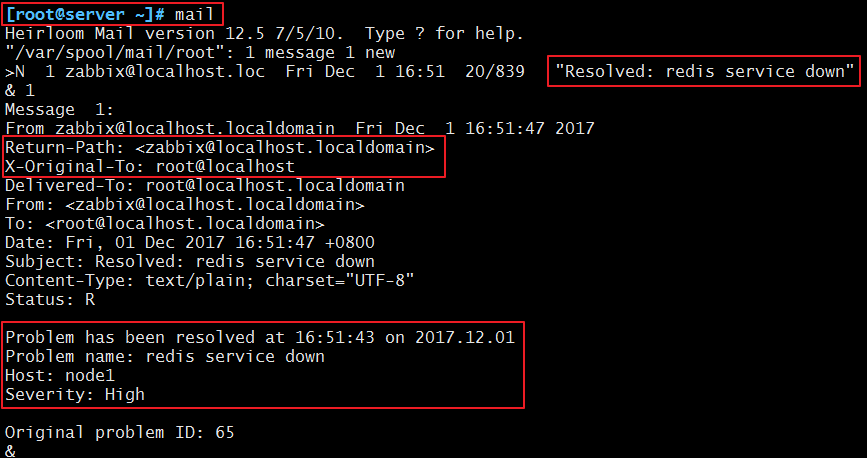
也可以去agent端查看端口是否开启:
[root@node1 ~]# systemctl stop redis.service
[root@node1 ~]# ss -ntl
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN 0 128 *:6379 *:*
LISTEN 0 128 *:111 *:*
LISTEN 0 5 192.168.122.1:53 *:*
LISTEN 0 128 *:22 *:*
LISTEN 0 128 127.0.0.1:631 *:*
LISTEN 0 128 *:23000 *:*
LISTEN 0 100 127.0.0.1:25 *:*
LISTEN 0 128 *:10050 *:*
LISTEN 0 128 :::111 :::*
LISTEN 0 128 :::22 :::*
LISTEN 0 128 ::1:631 :::*
LISTEN 0 100 ::1:25 :::* 可以看出端口正常开启,我们的动作触发已经完成。
补充:我们也可以使用脚本来发送警报,我们的脚本存放路径在配置文件中可以找到,定义为:
AlterScriptsPath=/usr/lib/zabbix/alertscripts
接下来,我们来一波彻底一点的操作,我们来手动修改一下redis服务的监听端口,这样,我们就不能通过重启服务恢复了:
[root@node1 ~]# vim /etc/redis.conf
#port 6379
port 6380 #注释掉原来的端口,更换为新的端口
[root@node1 ~]# systemctl restart redis 然后,我们来网页查看一下状态:
进入 监测中 ---> 问题,可以看到是报错的: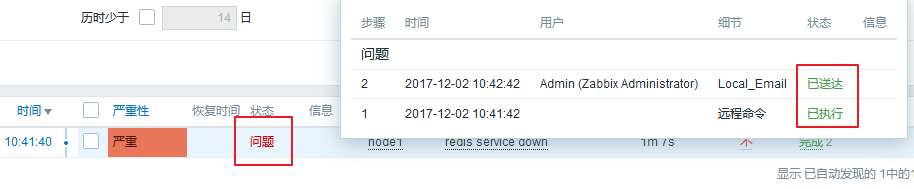
这样,在经过了重启服务以后还是没能把解决问题,就会发邮件告警: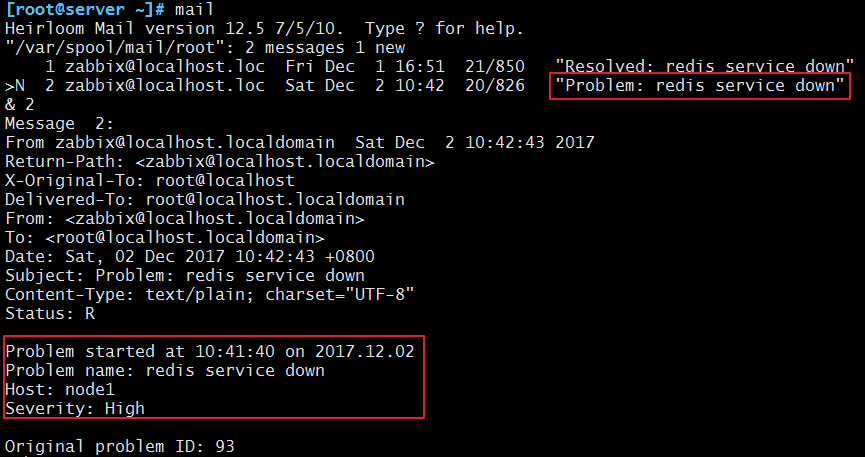
我们再把服务端口改回来,然后重启服务。这样,等到问题自动解决了以后,我们会再次收到邮件:
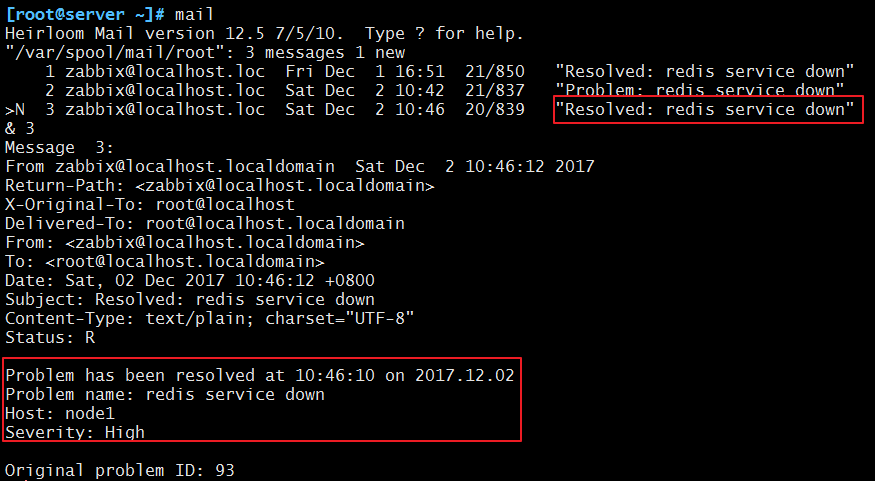
这样,我们的动作设定已经全部测试完成。
6)zabbix可视化
① 简介
数据日积月累,如果我们想要更直观的了解到各项数据的情况,图形无疑是我们的最佳选择。
zabbix提示了众多的可视化工具提供直观展示,如graph、screen及map等。上文中我们也看到过一些简单的图形展示。
如果我们想要把多个相关的数据定义在同一张图上去查看,就需要去自定义图形了~
② 自定义图形(Graphs)
自定义图形中可以集中展示多个时间序列的数据流。支持“线状图(normal)”、“堆叠面积图(stacked)”、“饼图(pie)” 和“分离型饼图(exploded)”四种不同形式的图形。
具体的设置过程如下:
进入 配置 ---> 主机 ---> node1 ---> 图形,选择右上角创建图形: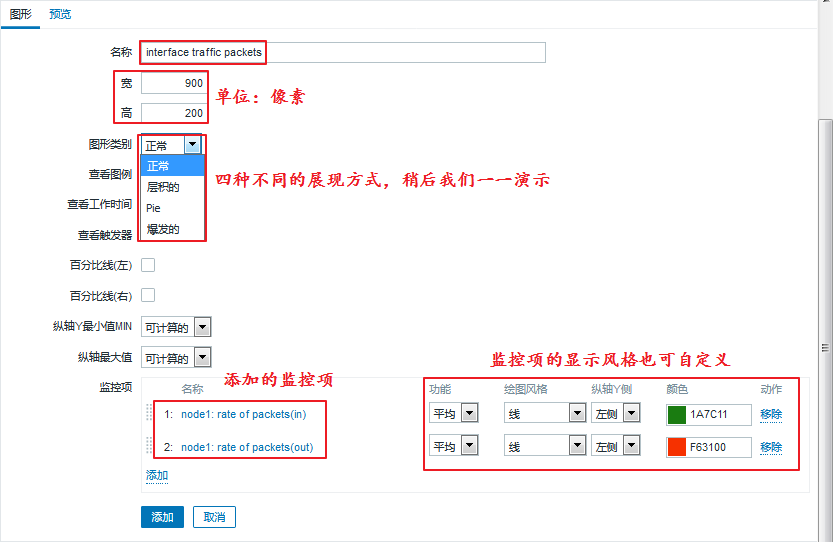
我们来看一看四种状态: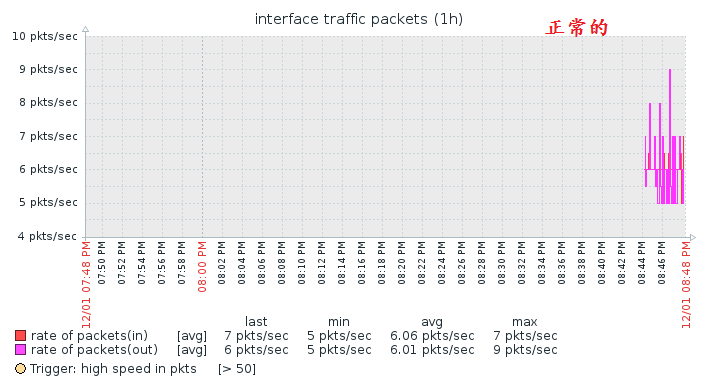



包括我们的主机都可以自定义,不过一般来说,线型是看的最清晰的,我们通常会使用这个。
我们也可以克隆一个packets来更改为bytes用~同样的,我们如果想添加别的内容,也都可以添加的。
我们一共添加了三个图形,我们可以在 监测中 ---> 图形 来查看
③ 聚合图形(Screens)
我们创建的自定义图形也可以放在一个聚合图里显示,具体的设置方法如下:
进入 监测中 ---> 聚合图形 ---> 选择右上角创建聚合图形
我们还可以选择分享:
定义好了添加即可。
定义完成以后,我们需要编辑一下,来指定保存哪些图: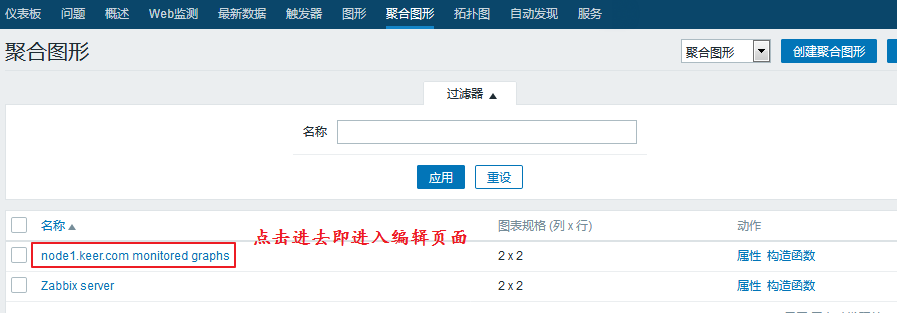
依次添加即可,添加完成之后是这样婶儿的~: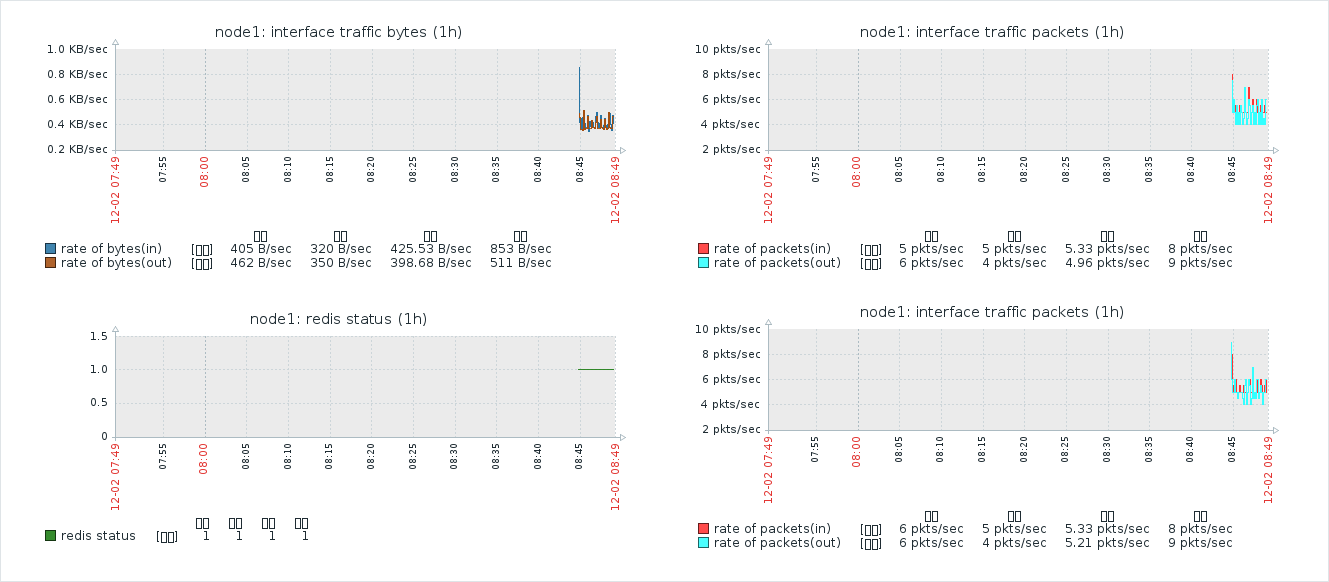
因为我们只有三张图,所以添加的有重复的,通常情况下是不需要这样的。
④ 幻灯片演示(Slide shows)
如果我们有多个聚合图形想要按顺序展示的话,我们就可以定义一个幻灯片。
具体步骤如下:
进入 监测中 ---> 聚合图形 ---> 右上角选择幻灯片演示 ---> 创建幻灯片
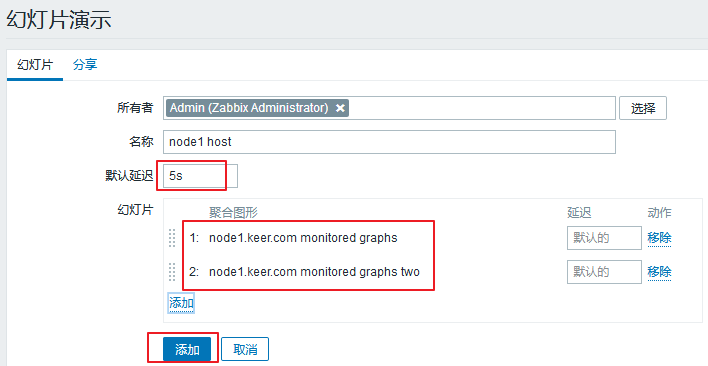
然后我们打开即可。打开以后显示的是图片1,5s以后会自动切换为图片2。
这样就可以实现幻灯片演示,我们就不需要去手动切换了。
⑤ 定义拓扑图(Maps)
在拓扑图中,我们可以定义成一个复杂的网络连接图,我们可以使用一台主机来连接另一台主机,这样的话,我们就可以查看出到底是哪个链接出了问题。
我们就不来演示了,看一下过程即可:
进入 监测中 ---> 拓扑图 ---> 所有地图 ---> Local network(默认就有的)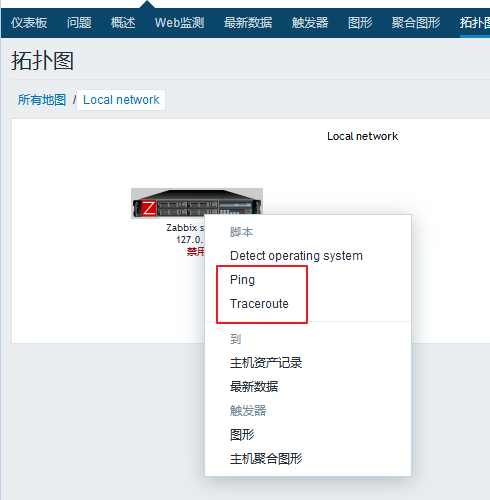
通过 Ping 和 Traceroute 就可以实验我们上述的功能。
7)模板
① 创建模板
之前我们说过,每一个主机的监控项都很多,我们一个一个的添加实在是太头疼了,更何况,可能不止一个主机。
但是我们可以把一个redis的监控项添加进一个模板里,这样更方便于我们以后的添加。
具体操作如下:
进入 配置 ---> 模板 ---> 选择右上角创建模板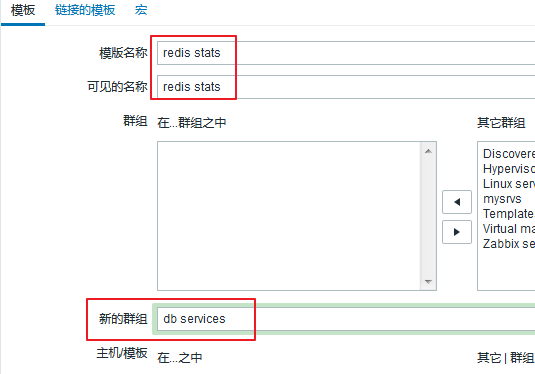
填写完以后,我们点击下方的添加即可。
我们可以基于组过滤一下,就能看到我们刚刚定义的模板: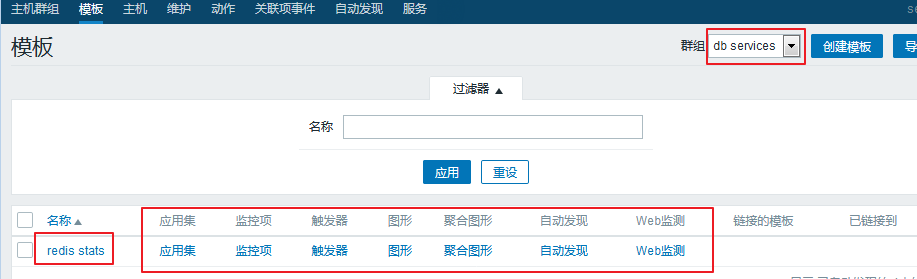
一样的,我们可以向里面添加应用集、监控项、触发器、图形等等,添加完成以后,后期我们再有主机需要添加就直接套用模板即可。
需要注意的一点是,我们现在添加的是模板,所以不会立即采用数据,只有链接到主机上以后,才会真正生效。
② 模板的导入与导出
我们也可以直接导入一个模板,在互联网上可以找到很多,导入的步骤如下:

同样的,我们创建好的模板也可以导出为文件:
我们任意选中一个准备好的模板,然后页面的最下方就有导出按钮: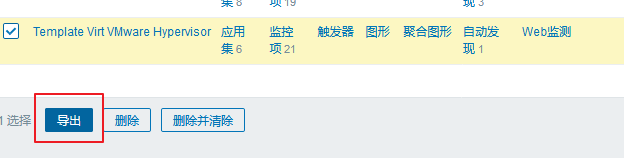
因此,我们就可以非常方便的进行应用了~
③ 模板的应用
我们的软件已经创建了许多模板,我们可以使用一个模板来看看效果。
进入 配置 ---> 主机 ---> node1 ---> 模板
我们就可以选择要添加的模板了: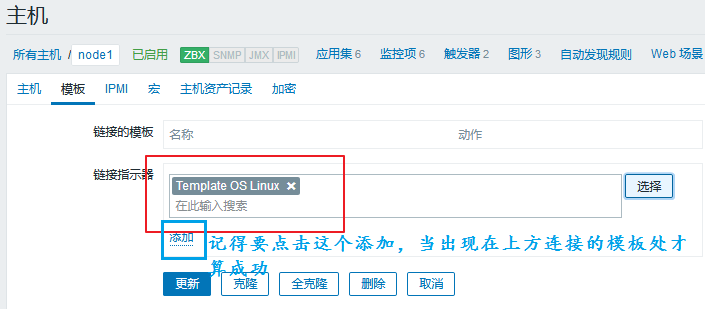
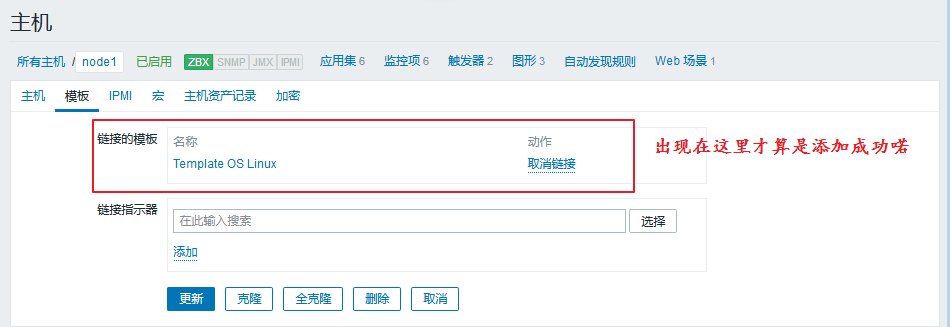
到这里我们就可以点击更新了。一旦我们成功链接至模板,我们的主机数据就会更新了:
注意:1、一个主机可以链接多个模板,但尽量不要让一个指标被采样两次。
2、如果我们有多个主机,同时这些主机也在一个主机组里,这样的话,我们只需要在这个主机组里添加模板,就能够让在主机组里的所有主机进行tongb
④ 移除模板链接
当我们一个主机的模板不想要用了,我们就可以移除模板链接,具体操作步骤如下:
进入 配置 ---> 主机 ---> node1 ---> 模板
我们就可以把不需要的模板移除:
我们来删除掉试试看,移除并清理以后,我们点击更新。就会自动跳转至如下界面:
可以看出,我们的模板已经被移除了。
8)宏(macro)
① 简介
宏是一种抽象(Abstraction),它根据一系列预定义的规则替换一定的文本模式,而解释器或编译器在遇到宏时会自动进行这一模式替换。
类似地,zabbix基于宏保存预设文本模式,并且在调用时将其替换为其中的文本。
zabbix有许多内置的宏,如{HOST.NAME}、{HOST.IP}、{TRIGGER.DESCRIPTION}、{TRIGGER.NAME}、{TRIGGER.EVENTS.ACK}等。
详细信息请参考官方文档
② 级别
宏一共有三种级别,分别是全局宏、模板宏、主机宏。
不同级别的宏的适用范围也不一样。
全局宏也可以作用于所有的模板宏和主机宏,优先级最低。
模板宏则可以作用于所有使用该模板的主机,优先级排在中间。
主机宏则只对单个主机有效,优先级最高。
③ 类型
宏的类型分为系统内建的宏和用户自定义的宏。
为了更强的灵活性,zabbix还支持在全局、模板或主机级别使用用户自定义宏(user macro)。
系统内建的宏在使用的时候需要{MACRO}的语法格式,用户自定义宏要使用{$MACRO}这种特殊的语法格式。
宏可以应用在item keys和descriptions、trigger名称和表达式、主机接口IP/DNS及端口、discovery机制的SNMP协议的相关信息中……
宏的名称只能使用大写字母、数字及下划线。
进一步信息请参考官方文档。
④ 定义一个宏
如果我们想要在我们的监控项(items)上使用宏,我们就要先去定义一个宏,然后去创建监控项,直接引用定义好的宏即可。具体操作步骤如下:
1.定义全局宏
进入 管理 ---> 一般 ---> 右上角选择宏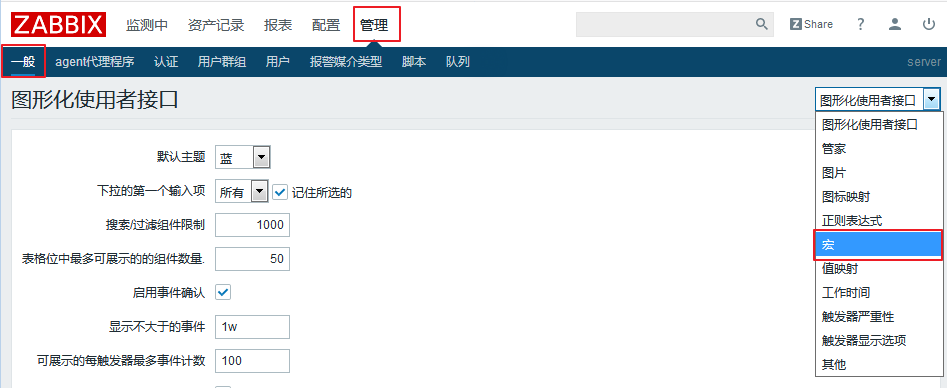

这样,我们的全局宏就添加好了。
2.定义监控项,调用宏
进入 配置 ---> 主机 ---> 所有主机 ---> 监控项 ---> 右上角创建监控项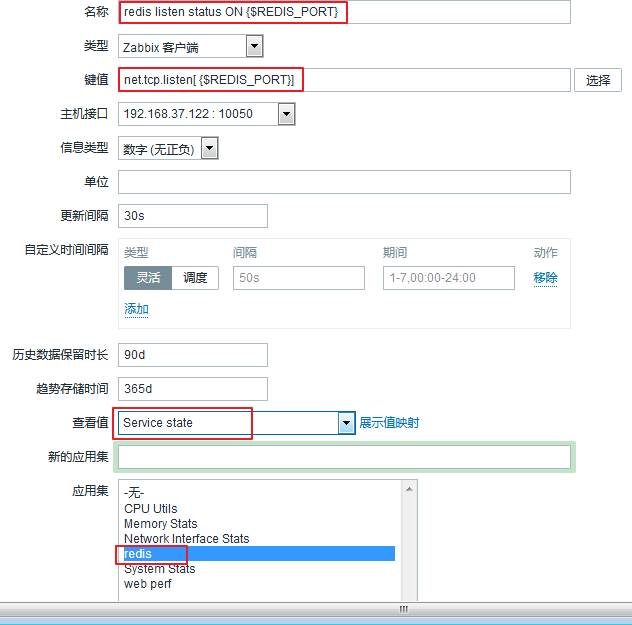
填写完成以后,点击添加。然后我们就可以看到这个调用宏的监控项已经添加成功: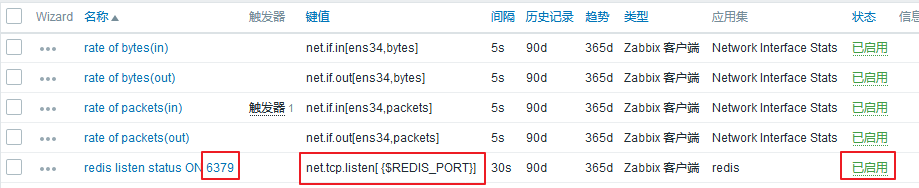
我们可以来查看一下这个监控项现在的状态:
进入 监测中 ---> 最新数据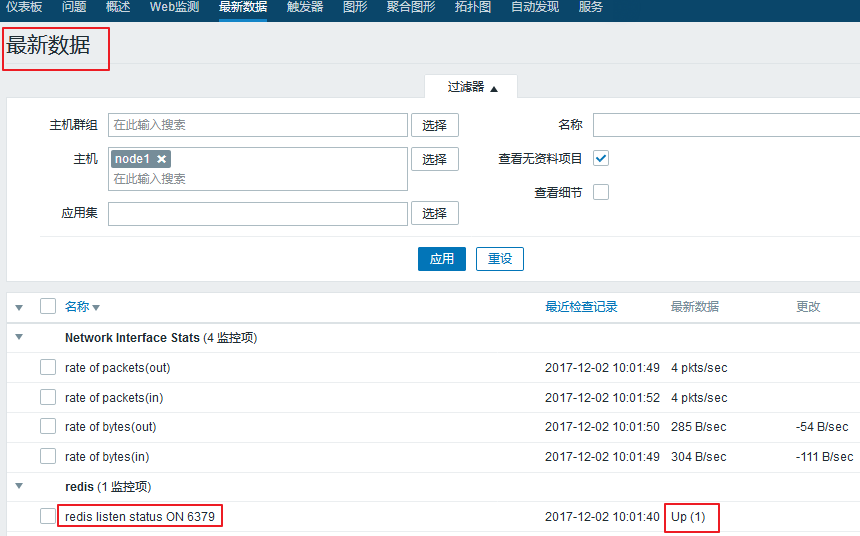
如果我们把服务停掉。就会变成down的状态:
[root@node1 ~]# systemctl stop redis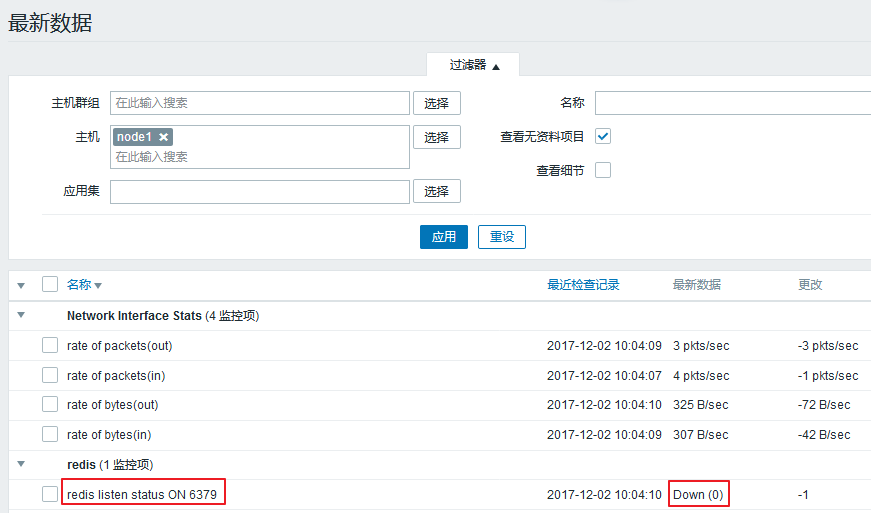
发现我们的监控项是可以正常使用的。
3.修改宏
如果我们把node1节点上的redis服务监听端口手动改掉的话,我们刚刚定义的监控项就不能正常使用了,这样的话,我们就需要去修改宏。
但是,这毕竟只是个例,所以我们不需要去修改全局宏,只用修改模板宏或者主机宏就可以了。
下面分别说一下,模板宏和主机宏的不同修改操作:
模板宏
模板宏的修改,我们需要进入:配置 ---> 模板 ---> redis stats(相应的模板) ---> 宏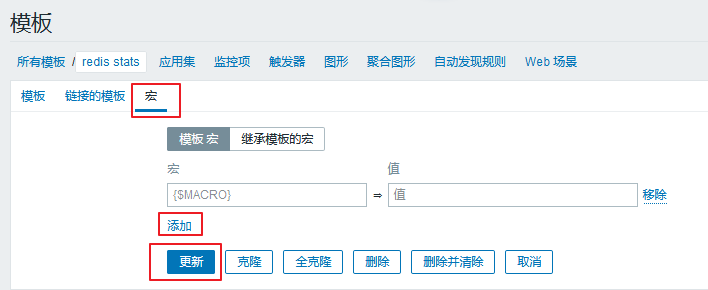
在这里点击添加就可以了。
主机宏
主机宏的修改,我们需要进入:配置 ---> 主机 ---> 所有主机 ---> node1 ---> 宏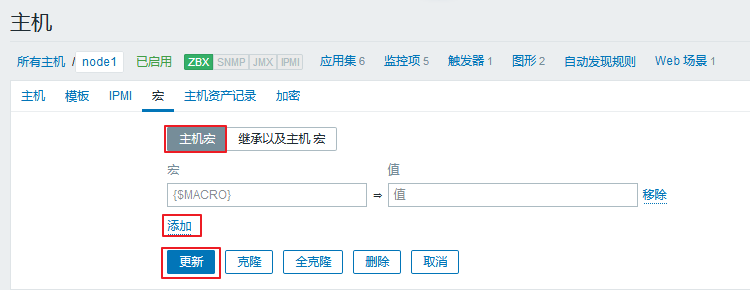
在这里点击添加就可以了。