python与机器学习实战 [何宇健] [2017.7第一版]
交流QQ:1825587919
交流WX:ly1825587919
机器学习绪论
- ......
机器学习常用术语
- ......
使用python进行机器学习
- ......
python一些第三方库的安装
- ......
第一个机器学习样例
该问题来自Coursera上的斯坦福大学机器学习课程:
现有47个房子的面积和价格,需要建立一个模型对新的房价进行预测
即有这样的理解:
- 输入数据只有一维,即房子的面积
- 目标数据也只有一维,即房子的价格
- 需要做的,就是根据已知房子的面积和价格的关系进行机器学习
虽然机器学习算法很多,但通常而言,进行机器学习的过程会包含以下三步:
- 获取与处理数据
- 选择与训练模型
- 评估与可视化结果
获取与处理数据
原始数据如下:
1 2104,399900 2 1600,329900 3 2400,369000 4 1416,232000 5 3000,539900 6 1985,299900 7 1534,314900 8 1427,198999 9 1380,212000 10 1494,242500 11 1940,239999 12 2000,347000 13 1890,329999 14 4478,699900 15 1268,259900 16 2300,449900 17 1320,299900 18 1236,199900 19 2609,499998 20 3031,599000 21 1767,252900 22 1888,255000 23 1604,242900 24 1962,259900 25 3890,573900 26 1100,249900 27 1458,464500 28 2526,469000 29 2200,475000 30 2637,299900 31 1839,349900 32 1000,169900 33 2040,314900 34 3137,579900 35 1811,285900 36 1437,249900 37 1239,229900 38 2132,345000 39 4215,549000 40 2162,287000 41 1664,368500 42 2238,329900 43 2567,314000 44 1200,299000 45 852,179900 46 1852,299900 47 1203,239500
在这个例子里,采取常用的将输入数据标准化的做法,数学公式为X=(X-X拔)/std(X),X拔表示X的均值,std(X)表示X的标准差。
1 #导入库 2 import numpy 3 import matplotlib.pyplot as plot 4 5 #定义存储数组 x 和目标数组 y 6 x,y = [],[] 7 for sample in open(r'prices_data.txt','r'): 8 #调用python中的split方法并将逗号作为参数传入 9 _x,_y = sample.split(',') 10 x.append(float(_x)) 11 y.append(float(_y)) 12 #转为numpy数组进一步处理 13 x,y = numpy.array(x),numpy.array(y) 14 #标准化 15 x= (x-x.mean()) /x.std() 16 #以散点图的形式画出 17 plot.figure() 18 plot.scatter(x,y,c='g',s=6) 19 plot.show()
这段代码即实现数据的可视化工作,下图分别为将x不做标准化和做标准化后的运行结果
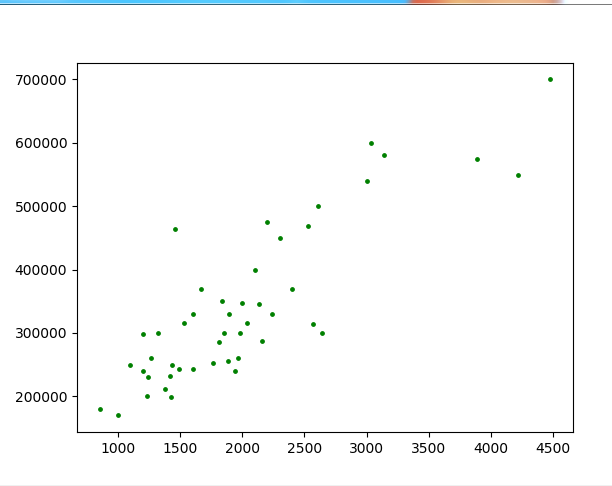
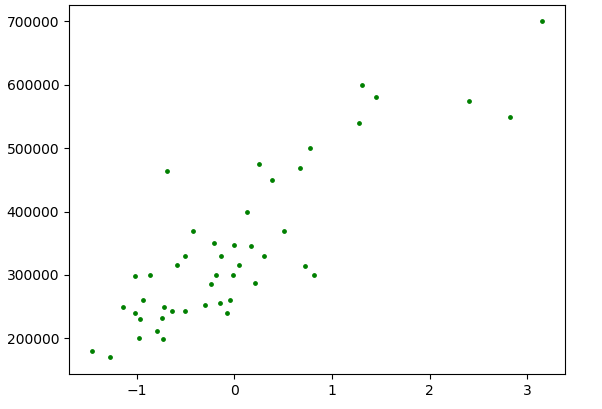
选择与训练模型
接下来便是选择训练模型,通过可视化数据,很有可能通过线性回归中的多项式拟合来进行训练。
PS:多项式拟合只是线性回归的很小一部分
f(x|p;n)=p0xn+p1xn-1+p2xn-2+...+pn-1x+pn
L(p;n)=1/2(求和)[f(x|p;n)-y]2
其中f(x|p;n)就是模型,p,n都是模型的参数,L(p;n)则是模型的损失函数,这里采用常见的平方损失函数,也就是所谓的欧式距离(向量的二范数)
接下来就是最小化这个损失函数
#开始训练 x0=numpy.linspace(-2,4,100) def get_model(deg): min_p=numpy.polyfit(x,y,deg) #该函数返回L(p;n)最小的参数p,亦即多项式的各项系数 yy=lambda input_x=x0:numpy.polyval(min_p,input_x) #根据输入的值x(默认为x0),返回预测的值y, return yy
评估与可视化结果
为了简单起见,我们取n=1,2,4,7,10,得到一些训练出来的损失值
#根据参数n、输入的x,y返回相对应的损失 def get_cost(deg,input_x,input_y): return 0.5* ((get_model(deg)(input_x) - input_y) ** 2).sum() #定义几个不同的n进行测试 text=(1,2,4,7,10) for d in text: print(get_cost(d,x,y))
得到的结果如下:
96732238800.4
96709317398.4
94112406641.7
79655422575.4
75874846680.1
Process finished with exit code 0
分析可得出,似乎n=10优于n=7,4,2,而n=1最差
我们再直观的做出图像:
#画出相应的图像 plot.scatter(x,y,c='g',s=20) for d in text: plot.plot(x0,get_model(d)(),label='degree={}'.format(d)) plot.xlim(-2,4) plot.ylim(1e5,8e5) plot.legend() plot.show()
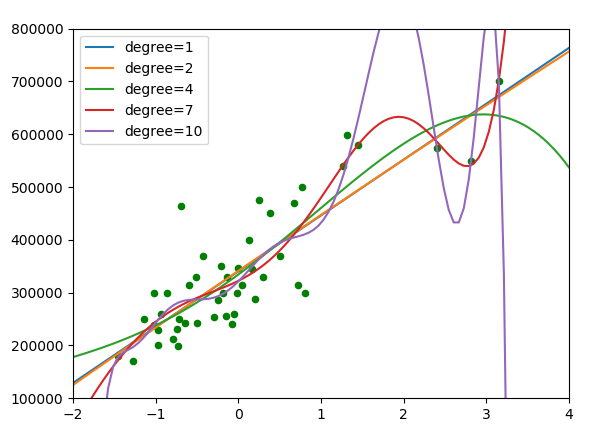
分析这张图,可以发现,n=1和n=2时拟合的最好,而n=4,7,10都开始出现过拟合了,n=10 时已经非常不合理了
至此我们便解决了这个问题,取n=1,则函数模型为y=ax+b;参数为:y=[ 105764.13349282 340412.65957447]
即 y=105764x+340412
如果不进行标准化,得出的模型为y=[ 134.52528772 71270.49244873]
即y=134.5x+71270.5