本节的主题是快速排序,它可能是应用最广泛的排序算法了。快速排序流行的原因是它实现简单、适用于各种不同的输入数据且在一般应用中比其他排序算法都要快得多。快速排序引人注目的特点包括它是原地排序(只需要一个很小的辅助栈),且将长度为N的数组排序所需的时间和NlgN成正比。我们已经学习过的排序算法都无法将这两个优点结合起来。另外,快速排序的内循环比大多数排序算法都要短小,这意味着它无论是在理论上还是在实际中都要更快。它的主要缺点是非常脆弱,在实现中要非常小心才能避免低劣的性能。已经有无数例子显示许多错误都能致使它在实际中的性能只有平方级别。幸好我们将会看到,由这些错误中学到的教训也大大改进了快速排序算法,使它的应用更加广泛。
快速排序是一种分治的排序算法。它将一个数组分成两个子数组,将两部分独立地排序。快速排序和归并排序是互补的:归并排序将数组分成两个子数组分别排序,并将有序的子数组归并以将整个数组排序;而快速排序将数组排序的方式则是当两个子数组都有序时整个数组也就自然有序了。在第一种情况中,递归调用发生在处理整个数组之前;在第二种情况中,递归调用发生在处理整个数组之后。在归并排序中,一个数组被等分成两半;在快速排序中,切分(partition)的位置取决于数组的内容。
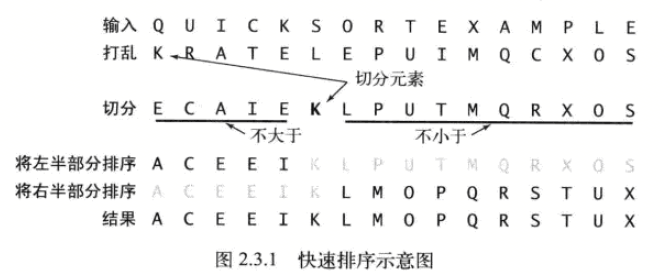
快速排序的代码实现:


package algorithm; import stdLib.StdRandom; /** * 〈算法2.5 快速排序〉<br> */ public class Quick { public static void sort(Comparable[] a){ StdRandom.shuffle(a); //消除对输入的依赖 sort(a, 0, a.length-1); } private static void sort(Comparable[] a, int lo, int hi){ if(hi <= lo) return; int j = partition(a, lo, hi); //切分(请见"快速排序的切分") sort(a, lo, j-1); //将左半部分a[lo .. j-1]排序 sort(a, j+1, hi); //将右半部分a[j+1 .. hi]排序 } /** * 快速排序的切分 */ private static int partition(Comparable[] a, int lo, int hi){ //将数组切分为a[lo..i-1], a[i], a[i+1..hi] int i = lo, j = hi + 1; //左右扫描指针 Comparable v = a[lo]; //切分元素 while(true){ //扫描左右,检查扫描是否结束并交换元素 while(less(a[++i], v)){ if(i == hi){ break; } } while(less(v, a[--j])){ if(j == lo){ break; } } if(i >= j){ break; } exch(a, i, j); } exch(a, lo, j); //将v=a[j]放入正确的位置 return j; //a[lo..j-1] <= a[j] <= a[j+1..hi] 达成 } private static boolean less(Comparable v, Comparable w){ return v.compareTo(w) < 0; } private static void exch(Comparable[] a, int i, int j){ Comparable t = a[i]; a[i] = a[j]; a[j] = t; } }
StdRandom.java的随机打乱数组:
/** * Rearranges the elements of the specified array in uniformly random order. */ public static void shuffle(Object[] a) { validateNotNull(a); int n = a.length; for (int i = 0; i < n; i++) { int r = i + uniform(n-i); // between i and n-1 Object temp = a[i]; a[i] = a[r]; a[r] = temp; } }
切分方法的解释:p289
原地切分:
如果使用一个辅助数组,我们可以很容易实现切分,但将切分后的数组复制回去的开销也许会使我们得不偿失。一个初级java程序员甚至可能会将空数组创建在递归的切分方法中,这会大大降低排序的速度。
别越界
如果切分元素是数组中最小或最大的那个元素,我们就要小心别让扫描指针跑出数组的边界。partiotion()实现可进行明确的检测来预防这种情况。测试条件(j==lo)是冗余的,因为切分元素就是a[lo],它不可能比自己小。数组右端也有同样的情况,它们都是可以去掉的。
保持随机性
数组元素的顺序是被打乱过的。因为算法2.5对所有的子数组都一视同仁,它的所有子数组也都是随机排序的,这对于预测算法的运行时间很重要。保持随机性的另一种方法是在partition()中随机选择一个切分元素。
快速排序的性能特点: 见p293/p294,写的比较复杂,不是太懂...还需要研究。
算法改进
很多人在研究并改进快速排序算法,提出各种改进方法,并不是所有的想法都可行,因为快速排序的平衡性已经非常好,改进所带来的提高可能会被意外的副作用所抵消。但其中一些,也是我们现在要介绍的,非常有效。
如果你的排序代码会被执行很多次或者会被用在大型数组上(特别是如果它会被发布成一个库函数,排序的对象数组的特性是未知的),那么下面所讨论的这些改进值得你参考。需要注意的是,你需要通过实验来确定改进的效果并为实现选择最佳的参数,一般来说它们能将性能提升20%~30%。
1.切换到插入排序
和大多数递归排序算法一样,改进快速排序性能的一个简单办法基于以下两点:
·对于小数组,快速排序比插入排序慢;
·因为递归,快速排序的sort()方法在小数组中也会调用自己。
因此在排序小数组时应该切换到插入排序,简单得改动算法2.5就可以做到这点:将sort中的语句
if(hi <= lo) return;
替换成下面这条语句来对小数组使用插入排序:
if(hi <= lo + M) { Insertion.sort(a, lo, hi); return; }
转换M的最佳值是个系统相关的,但是5~15之间的任意值在大多数情况下都能令人满意。
----