http://blog.csdn.net/yirenboy/article/details/46800855
1.Hadoop介绍
1.1Hadoop简介
Apache Hadoop软件库是一个框架,允许在集群服务器上使用简单的编程模型对大数据集进行分布式处理。Hadoop被设计成能够从单台服务器扩展到数以千计的服务器,每台服务器都有本地的计算和存储资源。Hadoop的高可用性并不依赖硬件,其代码库自身就能在应用层侦测并处理硬件故障,因此能基于服务器集群提供高可用性的服务。
1.2 Hadoop生态系统
经过多年的发展形成了Hadoop1.X生态系统,其结构如下图所示: 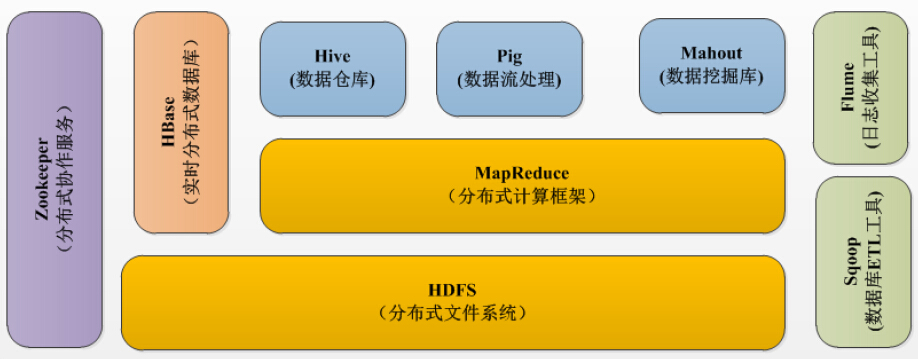
- HDFS–Hadoop生态圈的基本组成部分是Hadoop分布式文件系统(HDFS)。HDFS是一种数据分布式保存机制,数据被保存在计算机集群上,HDFS为HBase等工具提供了基础。
- MapReduce–Hadoop的主要执行框架是MapReduce,它是一个分布式、并行处理的编程模型,MapReduce把任务分为map(映射)阶段和reduce(化简)。由于MapReduce工作原理的特性,Hadoop能以并行的方式访问数据,从而实现快速访问数据。
- Hbase–HBase是一个建立在HDFS之上,面向列的NoSQL数据库,用于快速读/写大量数据。HBase使用Zookeeper进行管理,确保所有组件都正常运行。
- Zookeeper–用于Hadoop的分布式协调服务。Hadoop的许多组件依赖于Zookeeper,它运行在计算机集群上面,用于管理Hadoop操作。
- Pig–它是MapReduce编程的复杂性的抽象。Pig平台包括运行环境和用于分析Hadoop数据集的脚本语言(Pig Latin)。其编译器将Pig Latin翻译成MapReduce程序序列。
- Hive–Hive类似于SQL高级语言,用于运行存储在Hadoop上的查询语句,Hive让不熟悉MapReduce开发人员也能编写数据查询语句,然后这些语句被翻译为Hadoop上面的MapReduce任务。像Pig一样,Hive作为一个抽象层工具,吸引了很多熟悉SQL而不是Java编程的数据分析师。
- Sqoop是一个连接工具,用于在关系数据库、数据仓库和Hadoop之间转移数据。Sqoop利用数据库技术描述架构,进行数据的导入/导出;利用MapReduce实现并行化运行和容错技术。
- Flume提供了分布式、可靠、高效的服务,用于收集、汇总大数据,并将单台计算机的大量数据转移到HDFS。它基于一个简单而灵活的架构,并提供了数据流的流。它利用简单的可扩展的数据模型,将企业中多台计算机上的数据转移到Hadoop
1.3 Apache版本衍化
Apache Hadoop版本分为两代,我们将第一代Hadoop称为Hadoop 1.0,第二代Hadoop称为Hadoop2.0。第一代Hadoop包含三个大版本,分别是0.20.x,0.21.x和0.22.x,其中,0.20.x最后演化成1.0.x,变成了稳定版,而0.21.x和0.22.x则NameNode HA等新的重大特性。第二代Hadoop包含两个版本,分别是0.23.x和2.x,它们完全不同于Hadoop 1.0,是一套全新的架构,均包含HDFS Federation和YARN两个系统,相比于0.23.x,2.x增加了NameNode HA和Wire-compatibility两个重大特性。 
2 Hadoop1.X伪分布安装
Hadoop安装有如下三种方式:
- 单机模式:安装简单,几乎不用作任何配置,但仅限于调试用途;
- 伪分布模式:在单节点上同时启动NameNode、DataNode、JobTracker、TaskTracker、Secondary Namenode等5个进程,模拟分布式运行的各个节点;
- 完全分布式模式:正常的Hadoop集群,由多个各司其职的节点构成
由于实验环境的限制,本节课程将讲解伪分布模式安装,并在随后的课程中以该环境为基础进行其他组件部署实验。以下为伪分布式环境下在CentOS6中配置Hadoop-1.1.2,该配置可以作为其他Linux系统和其他版本的Hadoop部署参考。
2.1 软硬件环境说明
节点使用CentOS系统,防火墙和SElinux禁用,创建了一个shiyanlou用户,并在系统根目录下创建/app目录,用于存放Hadoop等组件运行包。因为该目录用于安装hadoop等组件程序,用户对shiyanlou必须赋予rwx权限(一般做法是root用户在根目录下创建/app目录,并修改该目录拥有者为shiyanlou(chown –R shiyanlou:shiyanlou /app)。
Hadoop搭建环境:
- 虚拟机操作系统:CentOS6.6 64位,单核,1G内存
- JDK:1.7.0_55 64位
- Hadoop:1.1.2
2.2 环境搭建(除2.2.1.3步骤需要学员设置外,其他配置实验楼虚拟机已设置)
实验环境的虚拟机已经完成的安装环境的配置,当其他机器部署时可以参考该章节进行环境搭建,需要关注的是JDK路径为/app/lib/jdk1.7.0_55。
2.2.1 配置本地环境
该部分对服务器的配置需要在服务器本地进行配置,配置完毕后需要重启服务器确认配置是否生效,特别是远程访问服务器需要设置固定IP地址。
2.2.1.1 设置IP地址(实验楼环境已配置,无需操作)
点击System–>Preferences–>Network Connections,如下图所示: 
修改或重建网络连接,设置该连接为手工方式,设置如下网络信息:
- IP地址: 192.168.42.8
- 子网掩码: 255.255.255.0
- DNS: 221.12.1.227 (需要根据所在地设置DNS服务器)
- Domain: 221.12.33.227
注意:网关、DNS等根据所在网络实际情况进行设置,并设置连接方式为”Available to all users”,否则通过远程连接时会在服务器重启后无法连接服务器 
在命令行中,使用ifconfig命令查看设置IP地址信息,如果修改IP不生效,需要重启机器再进行设置(如果该机器在设置后需要通过远程访问,建议重启机器,确认机器IP是否生效)
2.2.1.2 设置机器名(实验楼环境已配置,无需操作)
使用sudo vi /etc/sysconfig/network
打开配置文件,根据实际情况设置该服务器的机器名,新机器名在重启后生效

2.2.1.3 设置Host映射文件(需要在实验楼操作)
1.设置IP地址与机器名的映射,设置信息如下:
# 配置主机名对应的IP地址
$ sudo vi /etc/hosts
# sudo需要输入shiyanlou用户的密码:shiyanlou设置:
$ ping hadoop2.2.2 设置操作系统环境(实验楼环境已配置,无需操作)
2.2.2.1 关闭防火墙
在Hadoop安装过程中需要关闭防火墙和SElinux,否则会出现异常
1.使用sudo service iptables status
查看防火墙状态,如下所示表示iptables已经开启

(注意:若弹出权限不足,可能防火墙已经关闭,请输入命令:chkconfig iptables –list查看防火墙的状态。)
2.使用如下命令关闭iptables
- sudo chkconfig iptables off

2.2.2.2 关闭SElinux
1.使用getenforce命令查看是否关闭
2.修改/etc/selinux/config 文件
将SELINUX=enforcing改为SELINUX=disabled,执行该命令后重启机器生效

2.2.2.3 JDK安装及配置(实验楼环境已配置,无需操作)
1.下载JDK1.7 64bit安装包
打开JDK1.7 64bit安装包下载链接为:
http://www.oracle.com/technetwork/java/javase/downloads/jdk7-downloads-1880260.html
打开界面之后,先选中 Accept License Agreement ,然后下载 jdk-7u55-linux-x64.tar.gz,如下图所示:

2.创建/app目录,把该目录的所有者修改为shiyanlou
- sudo mkdir /app
- sudo chown -R shiyanlou:shiyanlou /app

3.创建/app/lib目录,使用命令如下:
mkdir /app/lib

4.把下载的安装包解压并迁移到/app/lib目录下
- cd /home/shiyanlou/install-pack
- tar -zxf jdk-7u55-linux-x64.tar.gz
- mv jdk1.7.0_55/ /app/lib
- ll /app/lib

5.使用sudo vi /etc/profile命令打开配置文件,设置JDK路径
- export JAVA_HOME=/app/lib/jdk1.7.0_55
- export PATH=JAVAHOME/bin:PATH
- export CLASSPATH=.:JAVAHOME/lib/dt.jar:JAVA_HOME/lib/tools.jar

6.编译并验证
- source /etc/profile
- java -version

2.2.2.4 更新OpenSSL(实验楼环境已配置,无需操作)
CentOS自带的OpenSSL存在bug,如果不更新OpenSSL在Ambari部署过程会出现无法通过SSH连接节点,使用如下命令进行更新:
yum update openssl


2.2.2.5 SSH无密码验证配置(实验楼环境已配置,无需操作)
1.使用sudo vi /etc/ssh/sshd_config,打开sshd_config配置文件,开放三个配置,如下图所示:
- RSAAuthentication yes
- PubkeyAuthentication yes
- AuthorizedKeysFile .ssh/authorized_keys

2.配置后重启服务
- sudo service sshd restart

3.使用shiyanlou用户登录使用如下命令生成私钥和公钥;
- ssh-keygen -t rsa

4.进入/home/shiyanlou/.ssh目录把公钥命名为authorized_keys,使用命令如下:
- cp id_rsa.pub authorized_keys

5.使用如下设置authorized_keys读写权限
- sudo chmod 400 authorized_keys

6.测试ssh免密码登录是否生效
2.3 Hadoop变量配置
2.3.1 下载并解压hadoop安装包
在Apache的归档目录中下载hadoop-1.1.2-bin.tar.gz安装包,也可以在/home/shiyanlou/install-pack目录中找到该安装包,解压该安装包并把该安装包复制到/app目录中
- cd /home/shiyanlou/install-pack
- tar -xzf hadoop-1.1.2-bin.tar.gz
- rm -rf /app/hadoop-1.1.2
- mv hadoop-1.1.2 /app

2.3.2 在Hadoop-1.1.2目录下创建子目录
- cd /app/hadoop-1.1.2
- mkdir tmp
- mkdir hdfs
- mkdir hdfs/name
- mkdir hdfs/data
- ls

把hdfs/data设置为755,否则DataNode会启动失败

2.3.3 配置hadoop-env.sh
1.进入hadoop-1.1.2/conf目录,打开配置文件hadoop-env.sh
- cd /app/hadoop-1.1.2/conf
- vi hadoop-env.sh

2.加入配置内容,设置了hadoop中jdk和hadoop/bin路径
- export JAVA_HOME=/usr/lib/java/jdk1.7.0_55
- export PATH=$PATH:/app/hadoop-1.1.2/bin

3.编译配置文件hadoop-env.sh,并确认生效
- source hadoop-env.sh
- hadoop version

2.3.4 配置core-site.xml
1.使用如下命令打开core-site.xml配置文件
- sudo vi core-site.xml
2.在配置文件中,按照如下内容进行配置
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://hadoop:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/app/hadoop-1.1.2/tmp</value>
</property>
</configuration>
2.3.5 配置hdfs-site.xml
1.使用如下命令打开hdfs-site.xml配置文件
- sudo vi hdfs-site.xml
2.在配置文件中,按照如下内容进行配置
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>/app/hadoop-1.1.2/hdfs/name</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/app/hadoop-1.1.2/hdfs/data</value>
</property>
</configuration>
2.3.6 配置mapred-site.xml
1.使用如下命令打开mapred-site.xml配置文件
- sudo vi mapred-site.xml
2.在配置文件中,按照如下内容进行配置
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>hadoop:9001</value>
</property>
</configuration>
2.3.7 配置masters和slaves文件
1.设子主节点
- vi masters

2.设置从节点
- vi slaves

2.3.8 格式化namenode
在hadoop1机器上使用如下命令进行格式化namenode
- hadoop namenode -format

2.3.9 启动hadoop
cd /app/hadoop-1.1.2/bin
./start-all.sh
2.3.10 用jps检验各后台进程是否成功启动
使用jps命令查看hadoop相关进程是否启动

这时我们发现少了一个DataNode进程,到$HADOOP_HOME/logs目下,使用cat hadoop-shiyanlou-datanode-5****.log(*表示所在机器名)查看日志文件,可以看到在日志中提示:Invalid directory in dfs.data.dir:Incorrect permission for /app/hadoop-1.1.2/hdfs/data, expected:rwxr-xr-x, while actual: rwxrwxr-x

sudo chmod 755 /app/hadoop-1.1.2/hdfs/data
重新启动hadoop集群,可以看到DataNode进程