【挖矿与共识】
每10分钟就会有⼀个新的区块被“挖掘”出来,每个区块⾥包含着从上⼀个区块产⽣到⽬前这段时间内发⽣的所有交易,这些交易被依次添加到区块链中。我们把包含在区块内且被添加到区块链上的交易称为“确认”交易,交易经过“确认”之后,新的拥有者才能够花费他在交易中得到的⽐特币。
矿⼯们在挖矿过程中会得到两种类型的奖励:创建新区块的新币奖励,以及区块中所含交易的交易费。
换句话说在2140年之后,不会再有新的⽐特币产⽣。
⼤约每⼗分钟产⽣⼀个新区块,每开采 210,000(21W) 个块(1年5.25W个区块),⼤约耗时4年,货币发⾏速率降低50%。在⽐特币运⾏的第⼀个四年中,每个区块创造出50个新⽐特币。
到2140年左右,会存在接近2,100万⽐特币。
比特币发行量脚本:


# 初始的块奖励为50BTC start_block_reward = 50 # 以10分钟为⼀个区块的间隔,210000个块共约4年时间 reward_interval = 210000 def max_money(): # 50 BTC = 50 0000 0000 Satoshis current_reward = 50 * 10**8 total = 0 while current_reward > 0: total += reward_interval * current_reward current_reward /= 2 return total print "Total BTC to ever be created:", max_money(), "Satoshis"

总量有限并且发⾏速度递减创造了⼀种抗通胀的货币供应模式。法币可被中央银⾏⽆限制地印刷出来,⽽⽐特币永远不会因超额印发⽽出现通胀。
许多经济学家提出通缩经济是⼀种⽆论如何都要避免的灾难型经济。因为在快速通缩时期,⼈们预期着商品价格会下通货紧缩货币跌,⼈们将会储存货币,避免花掉它。这种现象充斥了⽇本经济“失去的⼗年”,就是因为在需求坍塌之后导致了滞涨状态。
【去中心化共识】
1、交易的独立校验。
每⼀个节点在校验每⼀笔交易时,都需要对照⼀个⻓⻓的标准列表:
1)交易的语法和数据结构必须正确。
2)输⼊与输出列表都不能为空。
3)交易的字节⼤⼩是⼩于 MAX_BLOCK_SIZE 的。
4)解锁脚本( scriptSig )只能够将数字压⼊栈中,并且锁定脚本( scriptPubkey )必须要符合 isStandard 的格式 (该格式将会拒绝⾮标准交易)。
5)对于每⼀个输⼊,如果引⽤的输出存在于池中任何的交易,该交易将被拒绝。
2、整合交易至区块。
交易的优先级是由交易输⼊所花费的UTXO的“块龄”决定,交易输⼊值⾼、“块龄”⼤的交易⽐那些新的、输⼊值⼩的交易拥有更⾼的优先级。
交易的优先级是通过输⼊值和输⼊的“块龄”乘积之和除以交易的总⻓度得到的。交易输⼊的值是由⽐特币单位“聪”(1亿分之1个⽐特币)来表⽰的。

UTXO的“块龄”是⾃该UTXO被记录到区块链为⽌所经历过的区块数,即这个UTXO在区块链中的深度。交易记录的⼤⼩由字节来表⽰。
⼀个交易想要成为“较⾼优先级”,需满⾜的条件:优先值⼤于57,600,000,相当于⼀个⽐特币(即1亿聪),年龄为⼀天(144个区块),交易的⼤⼩为250个字节:

1)区块中⽤来存储交易的前50K字节是保留给较⾼优先级交易的。Jing的节点在填充这50K字节的时候,会优先考虑这些最⾼优先级的交易,不管它们是否包含了矿⼯费。这种机制使得⾼优先级交易即便是零矿⼯费,也可以优先被处理。
2)然后,Jing的挖矿节点会选出那些包含最⼩矿⼯费的交易,并按照“每千字节矿⼯费”进⾏排序,优先选择矿⼯费⾼的交易来填充剩下的区块,区块⼤⼩上限为 MAX_BLOCK_SIZE 。
3)如区块中仍有剩余空间,Jing的挖矿节点可以选择那些不含矿⼯费的交易。有些矿⼯会竭尽全⼒将那些不含矿⼯费的交易整合到区块中,⽽其他矿⼯也许会选择忽略这些交易。
4)在区块被填满后,内存池中的剩余交易会成为下⼀个区块的候选交易。因为这些交易还留在内存池中,所以随着新的区块被加到链上,这些交易输⼊时所引⽤UTXO的深度(即交易“块龄”)也会随着变⼤。
【创币交易】
1、
区块中的第⼀笔交易是笔特殊交易,称为创币交易或者coinbase交易。Jing的节点会创建“向Jing的地址⽀付25.09094928个⽐特币”这样⼀个交易,把⽣成交易的奖励发送到⾃⼰的钱包。
与常规交易不同,创币交易没有输⼊,不消耗UTXO。它只包含⼀个被称作coinbase的输⼊,仅仅⽤来创建新的⽐特币:

创币交易有⼀个输出,⽀付到这个矿⼯的⽐特币地址。创币交易的输出将这25.09094928个⽐特币发送到矿⼯的⽐特币地址,如本例所⽰的1MxTkeEP2PmHSMze5tUZ1hAV3YTKu2Gh1N。
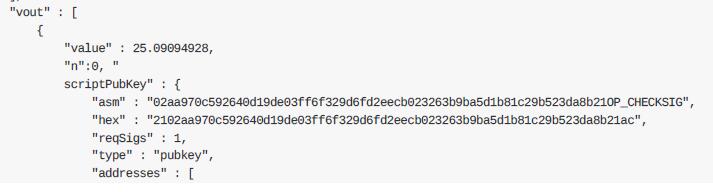

2、Coinbase奖励与矿工费。
Jing的节点需要计算矿⼯费的总额,将这418个已添加到区块交易的输⼊和输出分别进⾏加总,然后⽤输⼊总额减去输出总额得到矿⼯费总额,公式如下:

奖励与矿工费计算函数:
int64_t GetBlockValue(int nHeight, int64_t nFees) { int64_t nSubsidy = 50 * COIN; int halvings = nHeight / Params().SubsidyHalvingInterval(); // 如果右移的次数未定义,区块奖励强制为零 if (halvings >= 64) return nFees; // Subsidy每210,000个区块减半⼀次,⼤概每4年发⽣⼀次 nSubsidy >>= halvings; return nSubsidy + nFees; }
3、创币交易的结构。
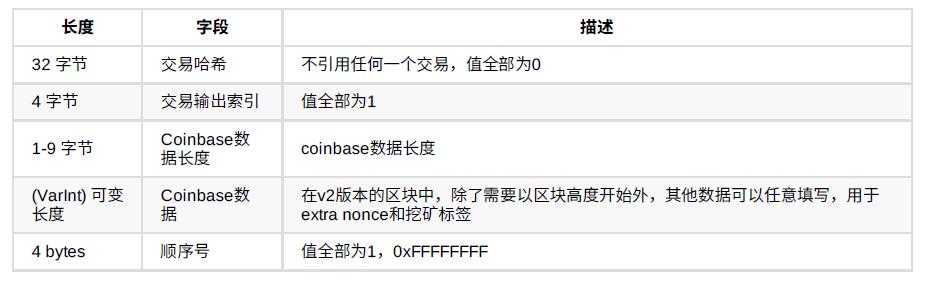
在创币交易中,“交易哈希”字段32个字节全部填充0,“交易输出索引”字段全部填充0xFF(⼗进制的255),这两个字段的值表⽰不引⽤UTXO。“解锁脚本”由coinbase数据代替,数据可以由矿⼯⾃定义。
4、CoinBase数据。
coinbase数据替代,⻓度最⼩2字节,最⼤100字节。除了开始的⼏个字节外,矿⼯可以任意使⽤coinbase的其他部分,随意填充任何数据。
以例8-4中的区块277,316为例,coinbase就是交易输⼊的“解锁脚本“(或scriptSig)字段,这个字段的⼗六进制值为 03443b0403858402062f503253482f。下⾯让我们来解码这段数据。
1)第⼀个字节是03,脚本执⾏引擎执⾏这个指令将后⾯3个字节压⼊脚本栈。
2)紧接着的3个字节——0x443b04,是以⼩端格式(最低有效字节在先)编码的区块⾼度。翻转字节序得到0x043b44,表⽰为⼗进制是277,316。
3)紧接着的⼏个⼗六进制数(03858402062)⽤于编码extra nonce(参⻅"8.11.1 随机值升位⽅案"),或者⼀个随机值,从⽽求解⼀个适当的⼯作量证明。
下面代码打印创世区块的Coinbase的信息:
/* Display the genesis block message by Satoshi. */ #include <iostream> #include <bitcoin/bitcoin.hpp> int main() { // Create genesis block. bc::block_type block = bc::genesis_block(); // Genesis block contains a single coinbase transaction. assert(block.transactions.size() == 1); // Get first transaction in block (coinbase). const bc::transaction_type& coinbase_tx = block.transactions[0]; // Coinbase tx has a single input. assert(coinbase_tx.inputs.size() == 1); const bc::transaction_input_type& coinbase_input = coinbase_tx.inputs[0]; // Convert the input script to its raw format. const bc::data_chunk& raw_message = save_script(coinbase_input.script); // Convert this to an std::string. std::string message; message.resize(raw_message.size()); std::copy(raw_message.begin(), raw_message.end(), message.begin()); // Display the genesis block message. std::cout << message << std::endl; return 0; }
【构造区块头】


1)为了向区块头填充merkle根字段,要将全部的交易组成⼀个merkle树。创币交易作为区块中的⾸个交易,后将余下的418笔交易添⾄其后,这样区块中的交易⼀共有419笔。
2)4字节的时间戳,以Unix纪元时间编码,即⾃1970年1⽉1⽇0点到当下总共流逝的秒数。
3)难度在区块中以“尾数-指数”的格式,编码并存储,这种格式称作“难度位”。这种编码的⾸字节表⽰指数,后⾯的3字节表⽰尾数(系数)
4)最后⼀个字段是nonce,初始值为0。区块头完成全部的字段填充后,挖矿就可以开始进⾏了。挖矿的⽬标是找到⼀个使区块头哈希值⼩于难度⽬标的nonce。挖矿节点通常需要尝试数⼗亿甚⾄数万亿个不同的nonce取值,直到找到⼀个满⾜条件的nonce值。
【构建区块】
挖矿就是重复计算区块头的哈希值,不断修改该参数,直到与哈希值匹配的⼀个过程。哈希函数的结果⽆法提前得知,也没有能得到⼀个特定哈希值的模式。哈希函数的这个特性意味着:得到哈希值的唯⼀⽅法是不断的尝试,每次随机修改输⼊,直到出现适当的哈希值。
1、工作量证明算法。
⽆论输⼊的⼤⼩是多少,SHA256函数的输出的⻓度总是256bit。
在语句末尾的变化的数字叫做 Nonce。Nonce是⽤来改变加密函数输出的,在这个⽰例中改变了这个语句的SHA256指纹。
区块哈希值实际上并不包含在区块的数据结构⾥,不管是该区块在⽹络上传输时,抑或是它作为区块链的⼀部分被存储在某节点的永久性存储设备上时。
相反,区块哈希值是当该区块从⽹络被接收时由每个节点计算出来的。区块的哈希值可能会作为区块元数据的⼀部分被存储在⼀个独⽴的数据库表中,以便于索引和更快地从磁盘检索区块。
下面是一个简化的工作量证明的算法:
#!/usr/bin/env python # example of proof-of-work algorithm import hashlib import time max_nonce = 2 ** 32 # 4 billion def proof_of_work(header, difficulty_bits): # calculate the difficulty target target = 2 ** (256-difficulty_bits) for nonce in xrange(max_nonce): hash_result = hashlib.sha256(str(header)+str(nonce)).hexdigest() # check if this is a valid result, below the target if long(hash_result, 16) < target: print "Success with nonce %d" % nonce print "Hash is %s" % hash_result return (hash_result,nonce) print "Failed after %d (max_nonce) tries" % nonce return nonce if __name__ == '__main__': nonce = 0 hash_result = '' # difficulty from 0 to 31 bits for difficulty_bits in xrange(32): difficulty = 2 ** difficulty_bits print "Difficulty: %ld (%d bits)" % (difficulty, difficulty_bits) print "Starting search..." # checkpoint the current time start_time = time.time() # make a new block which includes the hash from the previous block # we fake a block of transactions - just a string new_block = 'test block with transactions' + hash_result # find a valid nonce for the new block (hash_result, nonce) = proof_of_work(new_block, difficulty_bits) # checkpoint how long it took to find a result end_time = time.time() elapsed_time = end_time - start_time print "Elapsed Time: %.4f seconds" % elapsed_time if elapsed_time > 0: # estimate the hashes per second hash_power = float(long(nonce)/elapsed_time) print "Hashing Power: %ld hashes per second" % hash_power
下图是一部分运行输出。为寻找⼀个nonce使得哈希值开头的26位值为0,⼀共尝试了8千多万次。即使家⽤笔记本每秒可以达270,000多次哈希计算,这个查找依然需要6分钟。
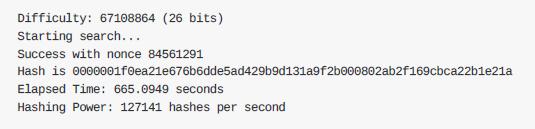
在写这本书的时候,⽐特币⽹络要寻找区块头信息哈希值⼩于000000000000004c296e6376db3a241271f43fd3f5de7ba18986e517a243baa7。可以看出,这个⽬标哈希值开头的0多了很多。这意味着可接受的哈希值范围⼤幅缩减,因⽽找到正确的哈希值更加困难。⽣成下⼀个区块需要⽹络每秒计算1.5 x1017次哈希。这看起来像是不可能的任务,但幸运的是⽐特币⽹络已经拥有100PH每秒(petahashes per second, peta-为1015)的处理能⼒,平均每10分钟就可以找到⼀个新区块。
【难度表示】
1、难度计算
计算难度⽬标的公式为:
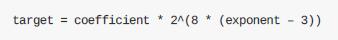
由此公式及难度位的值 0x1903a30c,可得:
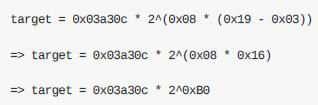
按⼗进制计算为:

转化为⼗六进制后为:

也就是说⾼度为277,316的有效区块的头信息哈希值是⼩于这个⽬标值的。这个数字的⼆进制表⽰中前60位都是0。在这个难度上,⼀个每秒可以处理1万亿个哈希计算的矿⼯(1 tera-hash per second 或 1 TH/sec)平均每8,496个区块才能找到⼀个正确结果,换句话说,平均每59天,才能为某⼀个区块找到正确的哈希值。
2、难度目标与难度选择。
难度的调整是在每个完整节点中独⽴⾃动发⽣的。每2,016个区块中的所有节点都会调整难度。难度的调整公式是由最新2,016个区块的花费时⻓与20,160分钟(两周,即这些区块以10分钟⼀个速率所期望花费的时⻓)⽐较得出的。难度是根据实际时⻓与期望时⻓的⽐值进⾏相应调整的(或变难或变易)。简单来说,如果⽹络发现区块产⽣速率⽐10分钟要快时会增加难度。如果发现⽐10分钟慢时则降低难度。

以下是难度调整代码:
// Go back by what we want to be 14 days worth of blocks const CBlockIndex* pindexFirst = pindexLast; for (int i = 0; pindexFirst && i < Params().Interval()-1; i++) pindexFirst = pindexFirst->pprev; assert(pindexFirst); // Limit adjustment step int64_t nActualTimespan = pindexLast->GetBlockTime() - pindexFirst->GetBlockTime(); LogPrintf(" nActualTimespan = %d before bounds ", nActualTimespan); if (nActualTimespan < Params().TargetTimespan()/4) nActualTimespan = Params().TargetTimespan()/4; if (nActualTimespan > Params().TargetTimespan()*4) nActualTimespan = Params().TargetTimespan()*4; // Retarget uint256 bnNew; uint256 bnOld; bnNew.SetCompact(pindexLast->nBits); bnOld = bnNew; bnNew *= nActualTimespan; bnNew /= Params().TargetTimespan(); if (bnNew > Params().ProofOfWorkLimit()) bnNew = Params().ProofOfWorkLimit();
公平正当地从事挖矿的矿⼯群体保持⾜够的哈希算⼒,"接管"攻击就不会得逞,让⽐特币的安全⽆虞。
【成功构建区块】
在Jing的桌⾯电脑上的挖矿节点将区块头信息传送给这些硬件,让它们以每秒亿万次的速度进⾏nonce测试。
在对区块277,316的挖矿⼯作开始⼤概11分钟后,这些硬件⾥的其中⼀个求得了解并发回挖矿节点。当把这个结果放进区块头时,nonce 4,215,469,401 就会产⽣⼀个OK的区块哈希值。
Jing的挖矿节点⽴刻将这个区块发给它的所有相邻节点。这些节点在接收并验证这个新区块后,也会继续传播此区块。当这个新区块在⽹络中扩散时,每个节点都会将它作为区块277,316加到⾃⾝节点的区块链副本中。当挖矿节点收到并验证了这个新区块后,它们会放弃之前对构建这个相同⾼度区块的计算,并⽴即开始计算区块链中下⼀个区块的⼯作。
如果一部分结点接收了Jing的新区块,而另一部分节点接受了其他人的区块,则分链问题就产生了。
【校验新区块】
当新区块在⽹络中传播时,每⼀个节点在将它转发到其节点之前,会进⾏⼀系列的测试去验证它。这确保了只有有效的区块会在⽹络中传播。独⽴校验还确保了诚实的矿⼯⽣成的区块可以被纳⼊到区块链中,从⽽获得奖励。⾏为不诚实的矿⼯所产⽣的区块将被拒绝,这不但使他们失去了奖励,⽽且也浪费了本来可以去寻找⼯作量证明解的机会,因⽽导致其电费亏损。
当⼀个节点接收到⼀个新的区块,它将对照⼀个⻓⻓的标准清单对该区块进⾏验证,若没有通过验证,这个区块将被拒绝。这些标准可以在⽐特币核⼼客⼾端的CheckBlock函数和CheckBlockHead函数中获得,它包括:
1)区块的数据结构语法上有效
2)区块头的哈希值⼩于⽬标难度(确认包含⾜够的⼯作量证明)
3)区块时间戳早于验证时刻未来两个⼩时
4)区块⼤⼩在⻓度限制之内
5)第⼀个交易(且只有第⼀个)是coinbase交易
6)使⽤检查清单验证区块内的交易并确保它们的有效性,如前文
7)“交易的独⽴校验”⼀节已经讨论过这个清单。
【区块链的组装与选择】
节点维护三种区块:
1)第⼀种是连接到主链上的
2)第⼆种是从主链上产⽣分⽀的(备⽤链)
3)最后⼀种是在已知链中没有找到已知⽗区块的。
如果节点收到了⼀个有效的区块,⽽在现有的区块链中却未找到它的⽗区块,那么这个区块被认为是“孤块”。孤块会被保存在孤块池中,直到它们的⽗区块被节点收到。⼀旦收到了⽗区块并且将其连接到现有区块链上,节点就会将孤块从孤块池中取出,并且连接到它的⽗区块,让它作为区块链的⼀部分。当两个区块在很短的时间间隔内被挖出来,节点有可能会以相反
的顺序接收到它们,这个时候孤块现象就会出现。
挖矿节点通过“投票”来选择它们想要延⻓的区块链,当它们挖出⼀个新块并且延⻓了⼀个链,新块本⾝就代表它们的投票。
【区块链分叉】
分叉发⽣在两名矿⼯在较短的时间内,各⾃都算得了⼯作量证明解的时候。两个矿⼯在各⾃的候选区块⼀发现解,便⽴即传播⾃⼰的“获胜”区块到⽹络中,先是传播给邻近的节点⽽后传播到整个⽹络。每个收到有效区块的节点都会将其并⼊并延⻓区块链。如果该节点在随后⼜收到了另⼀个候选区块,⽽这个区块⼜拥有同样⽗区块,那么节点会将这个区块连接到候选链上。其结果是,⼀些节点收到了⼀个候选区块,⽽另⼀些节点收到了另⼀个候选区块,这时两个不同版本的区块链就出现了。
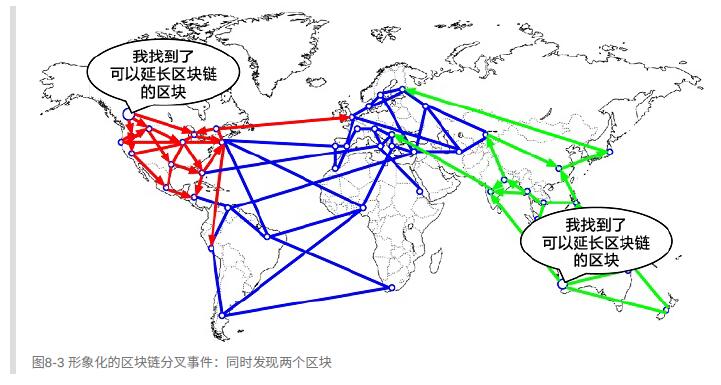
在这个例⼦中我们可以打个⽐⽅,假如⼯作在“绿⾊”区块上的矿⼯找到了⼀个“粉⾊”区块延⻓了区块链(蓝⾊-绿⾊-粉⾊),他们会⽴刻传播这个新区块,整个⽹络会都会认为这个区块是有效的:
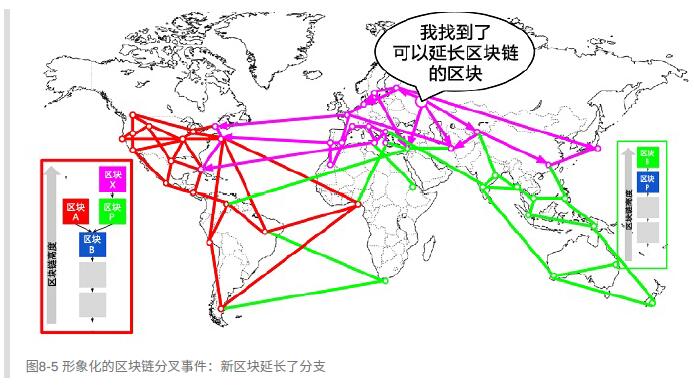
⽐特币将区块间隔设计为10分钟,是在更快速的交易确认和更低的分叉概率间作出的妥协。更短的区块产⽣间隔会让交易清算更快地完成,也会导致更加频繁地区块链分叉。与之相对地,更⻓的间隔会减少分叉数量,却会导致更⻓的清算时间。
【挖矿和算力竞赛】
⾃从⽐特币存在开始,每年⽐特币算⼒都成指数增⻓。⼀些年份的增⻓还体现出技术的变⾰。
1)⽐如在2010年和2011年,很多矿⼯开始从使⽤CPU升级到使⽤GPU,进⽽使⽤FGPA(现场可编程⻔阵列)挖矿。
2)在2013年,ASIC挖矿的引⼊,把SHA256算法直接固化在挖矿专⽤的硅芯⽚上,引起了算⼒的另⼀次巨⼤⻜跃。⼀台采⽤这种芯⽚的矿机可以提供的算⼒,⽐2010年⽐特币⽹络的整体算⼒还要⼤。

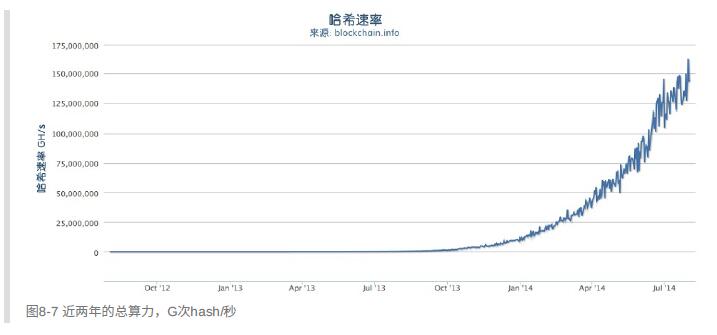
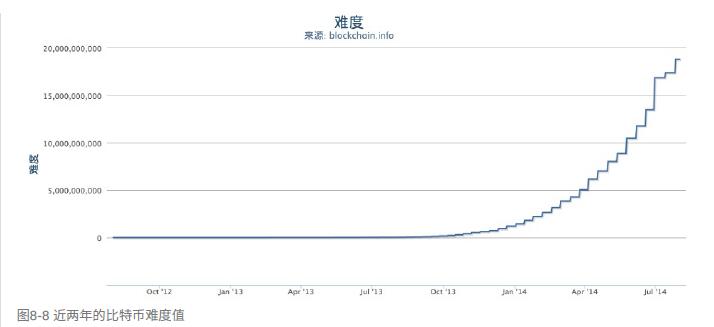
上图可以看到,难度是每2周调整一次,所以会有水平的直线。
【随机值升位方案】
Nonce存储于区块头结构中。长度为4个字节,取值为0-41亿。
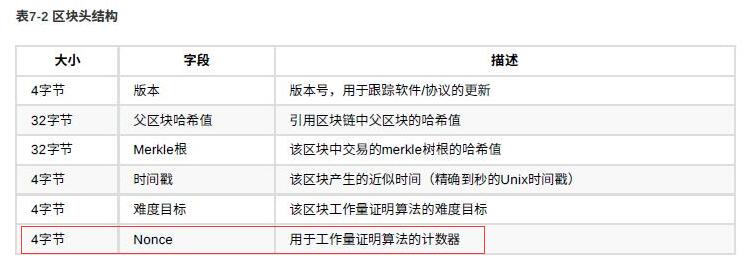
但这41亿个Nonce,并不随机出所有可能的区块头Hash。当这41个数被用完时怎么办呢?可以通过 CoinBase 中的 ExtraNonce 来加上Nonce 范围。
1、一种方法是改变区块头中的时间戳。
难度增⻓后,矿⼯经常在尝试了40亿个值后仍然没有出块。然⽽,这很容易通过读取块的时间戳并计算经过的时间来解决。因为时间戳是区块头的⼀部分,它的变化可以让矿⼯⽤不同的随机值再次遍历。
2、另一种方法是 CoinBase 中的 ExtraNonce。
当挖矿硬件的速度达到了4GH/秒,这种⽅法变得越来越困难,因为随机数的取值在⼀秒内就被⽤尽了。当出现ASIC矿机并很快达到了TH/秒的hash速率后,挖矿软件为了找到有效的块,需要更多的空间来储存nonce值。可以把时间戳延后⼀点,但将来如果把它移动得太远,会导致区块变为⽆效。区块头需要⼀个新的“差异性”的信息来源。解决⽅案是使⽤coinbase交易作为额外的随机值来源,因为coinbase脚本可以储存2-100字节的数据,矿⼯们开始使⽤这个空间作为额外随机值的来源,允许他们去探索⼀个⼤得多的区块头值范围来找到有效的块。这个coinbase交易包含在merkle树中,这意味着任何coinbase脚本的变化将导致Merkle根的变化。8个字节的额外随机数,加上4个字节的“标准”随机数,允许矿⼯每秒尝试2^96(8后⾯跟28个零)种可能性⽽⽆需修改时间戳。
【共识攻击】
1、51%双重支付攻击
2、拒绝服务攻击