数据提取
在我之前的文章Scrapy自动爬取商品数据爬虫里实现了爬虫爬取商品网站搜索关键词为python的书籍商品,爬取到了60多页网页的1260本python书籍商品的书名,价格,评论数和商品链接,并将所有商品数据存储到本地的.json文件中。数据存储格式如下:
爬虫爬取到的商品数据
接下来对爬取到的商品数据作预处理及可视化分析,使用工具为Anaconda的Jupyter notebook和python3.6环境。首先用python将爬取到的数据输出为.csv文件,方便观察和保存再利用。观察第1260个数据可以发现价格格式为“¥46.60”,评论数格式为“301条评论”,都为字符串格式,要先分别转换为数字格式“46.60”和“301”以方便处理。
import jsonimport csvimport numpy as npyimport pandas as pda#读取.json文件dic=[]f = open("D:/python/.../getdata.json", 'r',encoding='utf-8')#这里为.json文件路径for line in f.readlines(): dic.append(json.loads(line))#对爬取到的数据作处理,将价格和评论数由字符串处理为数字 tmp=''name,price,comnum,link=[]for i in range(0,1260): dic[i]['price']=tmp + dic[i]['price'][1:] dic[i]['comnum']=dic[i]['comnum'][:-3]+tmp price.append(float(dic[i]['price'])) comnum.append(int(dic[i]['comnum'])) name.append(dic[i]['name']) link.append(dic[i]['link'])data = numpy.array([name,price,comnum,link]).Tprint (data)
这里将爬取的数据都作处理后,转换为python科学计算库的numpy.array格式,data输出结果如下:
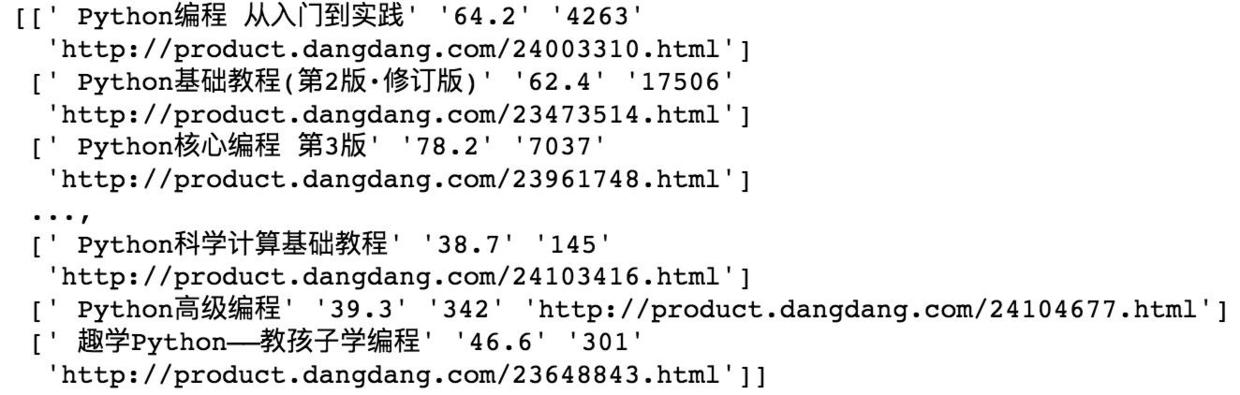
print(data)
然后将data存储为.csv文件
#要存储.csv文件的路径csvFile = open('D:/python/.../csvFile.csv','w') writer = csv.writer(csvFile)writer.writerow(['name', 'price', 'comnum','link'])for i in range(0,1260): writer.writerow(data[i])csvFile.close()
现在可以打开该路径下的.csv文件,已存储为如下格式:
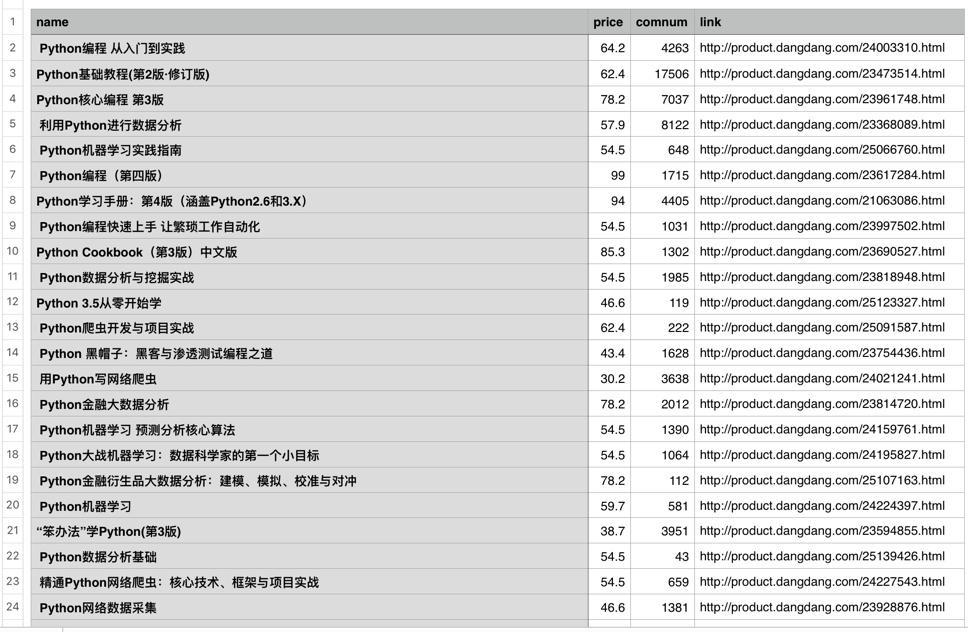
.csv文件
当然可以在Scrapy爬虫项目中修改pipelines.py文件,爬取到数据后直接输出为.csv文件保存至本地,以相同方式改动添加上面的代码即可,这里因为爬取到的数据并不直接可用,为方便分析处理先输出到了.json文件。
数据预处理
缺失值处理
首先用数据分析处理库pandas读取.csv文件中的数据,存储为数据框格式。可以发现该数据中有许多书的评论数为0,所以首先要做数据清洗,找到这些缺失值,这也是数据分析过程中很重要的一环。在数据分析过程中,对这些缺失数据有两种处理方式,可以用评论数的均值来填补,也可以直接删除缺失数据,针对相应情况选择处理方式。
#读取.csv文件数据data = pda.read_csv("D:/python/.../csvFile.csv")#发现缺失值,将评论数为0的值转为Nonedata["comnum"][(data["comnum"]==0)]=None#均值填充处理#data.fillna(value=data["comnum"].mean(),inplace=True)#删除处理,data1为缺失值处理后的数据data1=data.dropna(axis=0,subset=["comnum"])
缺失数据过多,这里采取删除处理方式。
异常值处理
在做异常值处理时首先要找到异常值,先画数据的散点图观察一下数据分布情况,这里用python的数据可视化库Matplotlib作图。
import matplotlib.pyplot as plt#画散点图(横轴:价格,纵轴:评论数)#设置图框大小fig = plt.figure(figsize=(10,6))plt.plot(data1['price'],data1['comnum'],"o")#展示x,y轴标签plt.xlabel('price')plt.ylabel('comnum')plt.show()
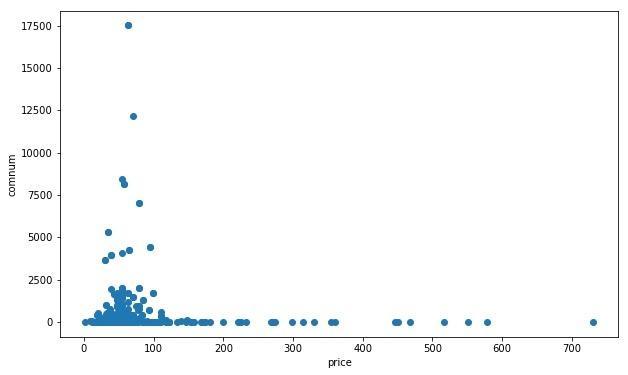
价格-评论数散点图
可以看到有部分数据评论数过高,或许为热销商品或者存在刷评论,还有一部分数据价格过高,甚至高达700,而一般书籍价格不会高过¥150。对于这些异常值我们在作数据分析时一般不会考虑,删除或者改动这些异常值即可。再看看数据的箱型图观察分布情况:
fig = plt.figure(figsize=(10,6))#初始化两个子图,分布为一行两列ax1 = fig.add_subplot(1,2,1)ax2 = fig.add_subplot(1,2,2)#绘制箱型图ax1.boxplot(data1['price'].values)ax1.set_xlabel('price')ax2.boxplot(data1['comnum'].values)ax2.set_xlabel('comnum')#设置x,y轴取值范围ax1.set_ylim(0,150)ax2.set_ylim(0,1000)plt.show()
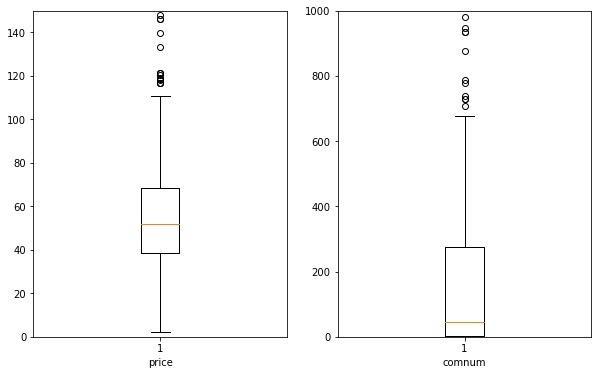
箱型图
价格的箱型图中黄线表示中位数,大概为¥50,箱型图上下分别为上四分位和下四分位,分别为¥40到¥70,上下界分别为¥110和¥0,最上方的圆点都是离群点。可以看到评论数中位数分布点较低。离群点的数值明显偏离其余观测值,会对分析结果产生不良影响,所以我们将价格¥120以上,评论数700以上的离群点删除,不作考虑,代码如下:
#删除价格¥120以上,评论数700以上的数据data2=data[data['price']<120]data3=data2[data2['comnum']<700]#data3为异常值处理后的数据fig = plt.figure(figsize=(10,6))plt.plot(data3['price'],data3['comnum'],"o")plt.xlabel('price')plt.ylabel('comnum')plt.show()
处理后数据剩余约500个,新数据分布如下图:
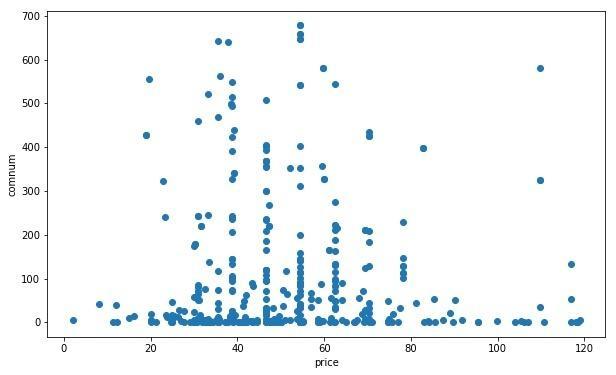
价格-评论数散点图
数据可视化分析
直方图可视化分析
最后可以对数据做可视化分析了,可以对价格及评论数做直方图,分析数据分布情况。
#求最值pricemax=da2[1].max()pricemin=da2[1].min()commentmax=da2[2].max()commentmin=da2[2].min()##计算极差pricerg=pricemax-pricemincommentrg=commentmax-commentmin#组距=极差/组数pricedst=pricerg/13commentdst=commentrg/13fig = plt.figure(figsize=(12,5))ax1 = fig.add_subplot(1,2,1)ax2 = fig.add_subplot(1,2,2)#绘制价格直方图#numpy.arrange(最小,最大,组距)pricesty=numpy.arange(pricemin,pricemax,pricedst)ax1.hist(da2[1],pricesty,rwidth=0.8)ax1.set_title('price')#绘制评论数直方图commentsty=numpy.arange(commentmin,commentmax,commentdst)ax2.hist(da2[2],commentsty,rwidth=0.8)ax2.set_title('comnum')plt.show()
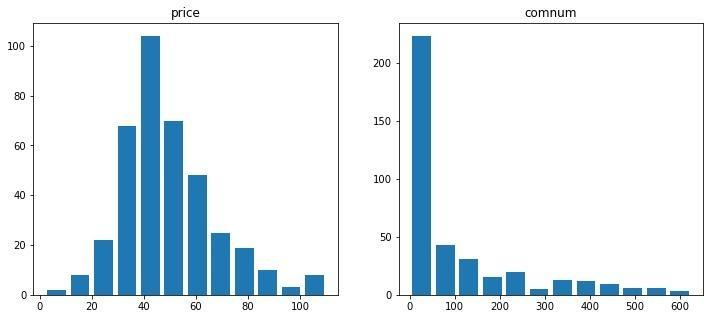
直方图
从直方图中可以观察到:1、书的价格大致呈正态分布,¥40左右的书籍比较多,说明python书籍基本定价在¥40左右2、评论数在50条以下的书籍商品最多(200多本),随着评论数递增,商品数量逐渐减少,说明大部分商品销量一般,销量较好的书就是那几本经典作品。
K-Means聚类可视化分析
最后对数据作聚类分析,这里采用了机器学习算法——K-Means聚类算法,K-Means聚类算法是机器学习中的一个无监督学习算法,简单,快速,适合常规数据集,具体的算法执行步骤如下:1、初始化聚类中心2、计算样本点到各个聚类中心的距离,选择距离小的,进行聚类3、计算新的聚类中心,改变新的聚类中心4、重复2-3步,直到聚类中心不发生改变通过调用Python的机器学习库sklearn,可利用此算法实现对商品的分类:
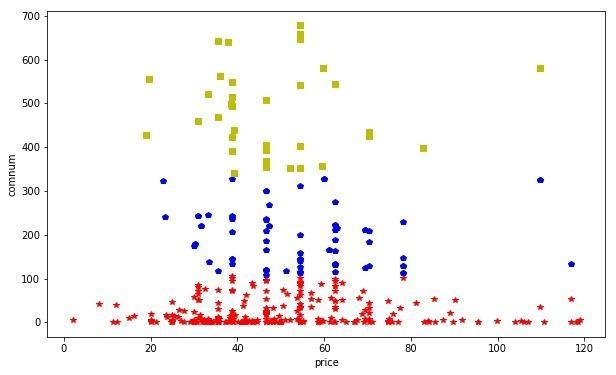
#转换数据格式tmp=numpy.array([data3['price'],data3['comnum']]).T#调用python关于机器学习sklearn库中的KMeansfrom sklearn.cluster import KMeans#设置分为3类,并训练数据kms=KMeans(n_clusters=3)y=kms.fit_predict(tmp)#将分类结果以散点图形式展示fig = plt.figure(figsize=(10,6))plt.xlabel('price')plt.ylabel('comnum')for i in range(0,len(y)): if(y[i]==0): plt.plot(tmp[i,0],tmp[i,1],"*r") elif(y[i]==1): plt.plot(tmp[i,0],tmp[i,1],"sy") elif(y[i]==2): plt.plot(tmp[i,0],tmp[i,1],"pb")plt.show()
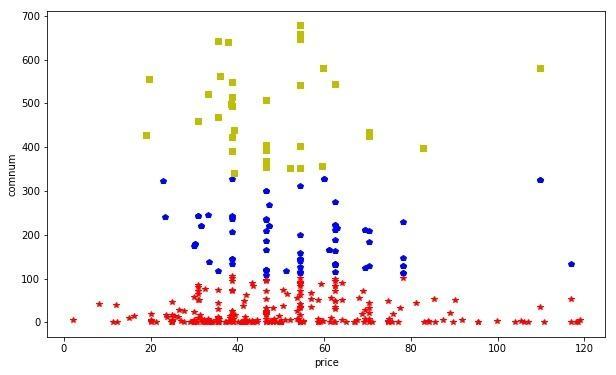
聚类分布图
从聚类结果中可以看到,K-Means聚类算法将评论数100以下的分为了一类,评论数大致从100到350的分为一类,评论数大致在350以上的分为了一类,基本按照书籍是否畅销分成了三类,从图中可明显看出聚类效果。
总结
本文总结了拿到一份初始的爬虫数据后,从数据提取成文件,到数据缺失值和异常值处理,再到商品的直方图分布和K-Means聚类可视化分析的全部过程。以上过程就是利用python进行简单的数据分析的大致过程,读者在拿到一份数据后,也可参考本文代码按照此过程自己进行数据分析,自己玩转数据啦。
相关推荐:
| 标题 |
|---|
| 使用R语言随机波动模型SV处理时间序列中的随机波动率 (2020-04-15 14:49) |
| R语言用WinBUGS 软件对学术能力测验(SAT)建立分层模型 (2020-04-14 16:27) |
| R语言使用随机技术差分进化算法优化的Nelson-Siegel-Svensson模型 (2020-04-12 18:52) |
| 已迁离北京外来人口的数据画像 (2020-04-11 20:55) |
| R语言用神经网络改进Nelson-Siegel模型拟合收益率曲线分析 (2020-04-10 15:51) |
| 用R语言用Nelson Siegel和线性插值模型对债券价格和收益率建模 (2020-04-06 11:16) |
| R语言LME4混合效应模型研究教师的受欢迎程度 (2020-03-27 15:18) |
| R语言Black Scholes和Cox-Ross-Rubinstein期权定价模型案例 (2020-03-25 14:36) |
| R语言中的Nelson-Siegel模型在汇率预测的应用 (2020-03-25 14:07) |
| R语言中的block Gibbs吉布斯采样贝叶斯多元线性回归 (2020-03-06 16:20) |